.svg)
LFM2.5-8B-A1B: ノートPC上で動くパーソナルアシスタント
本日、私たちはLFM2.5-8B-A1Bをリリースします。これは、一般消費者向けハードウェア上で高速かつ信頼性の高いツール呼び出しを実現するために設計されたエッジモデルです。
本モデルは、2025年10月にリリースしたLFM2-8B-A1Bを基盤としており、128Kへ拡張されたコンテキストウィンドウ、事前学習規模の拡大(12兆→38兆トークン)、および大規模な強化学習を特徴としています。また、非ラテン文字言語におけるトークン化効率を改善するため、語彙数を2倍に増やしました。その結果、ツール呼び出しを連鎖させてタスクを遂行でき、エントリーレベルのノートPCでも快適に動作するモデルが実現できました。
ベースモデル(LFM2.5-8B-A1B-Base)およびポストトレーニング済みモデル(LFM2.5-8B-A1B)は、本日よりHugging Face、Playgroundで利用可能です。ローカル環境での実行やファインチューニング方法については、ドキュメントをご覧ください。
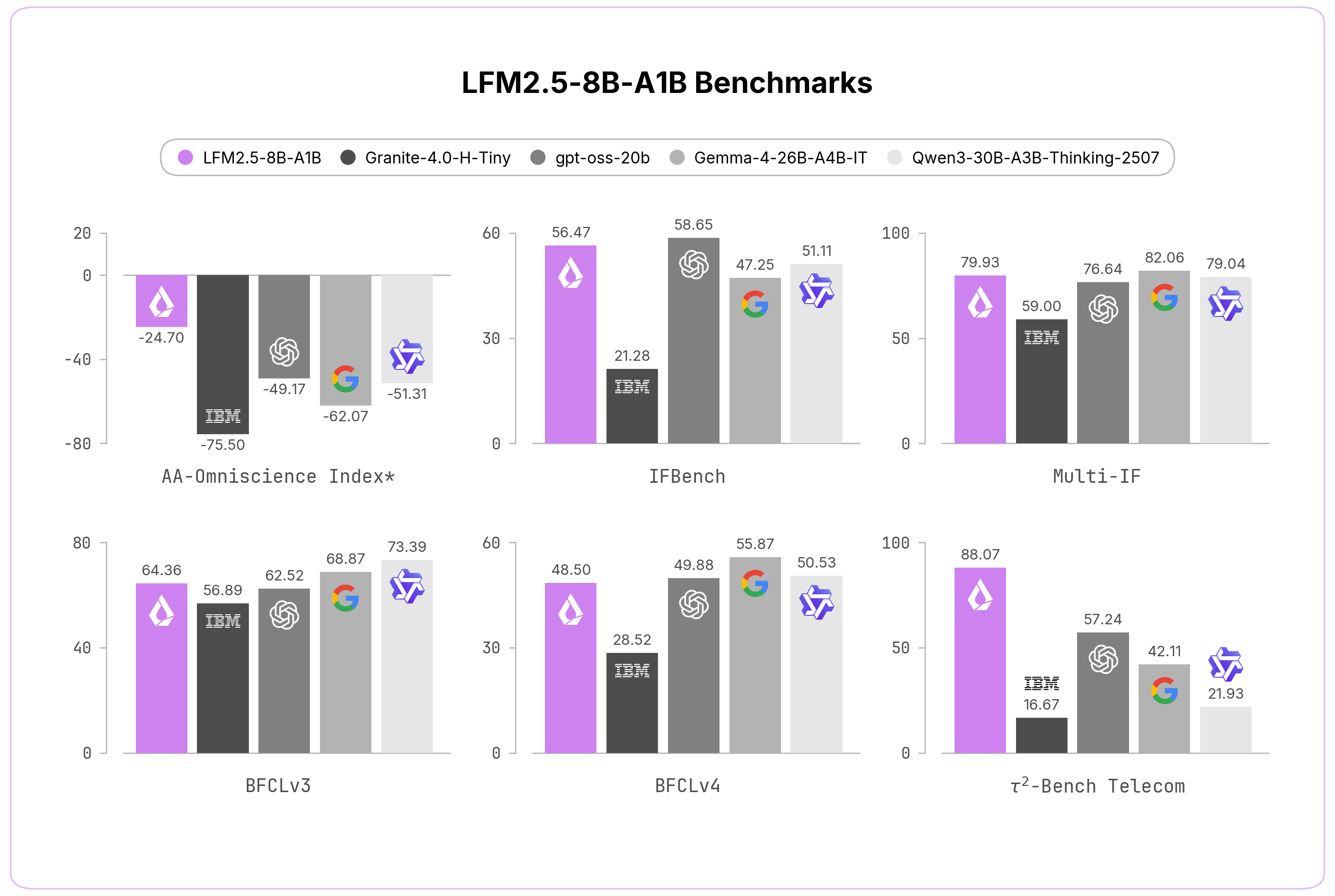
*AA-Omniscience Index(高いほど良い)は、正答を評価しつつハルシネーションを減点する指標で、スコア範囲は -100〜100。詳細はArtificial Analysisをご覧ください。
ハイライト
- オンデバイスのパーソナルアシスタント
実世界のアプリケーションを支え、ツール呼び出しの連鎖や複雑な指示の遂行を、あらゆるデバイス上で可能にするよう設計された - 圧縮された高性能
命令追従やエージェントタスクにおいて、はるかに大規模なDenseモデルやMoEモデルに匹敵する性能を発揮 - 圧倒的スループット
CPU・GPU推論のいずれにおいても同サイズ帯で最速を実現し、llama.cpp、MLX、vLLM、SGLangを初日からサポート
LFM2-8B-A1Bからの変更点
LFM2-8B-A1Bと比較して、この新バージョンではコンテキストウィンドウを32,768トークンから128,000トークンへ拡張しました。これにより、モデルはより長い文書を処理し、より長く推論できるようになります。また、非ラテン文字をより効率的にトークナイズするため、語彙サイズも65,536から128,000へと拡大しました。特にヒンディー語、タイ語、ベトナム語、インドネシア語、アラビア語において、大きな圧縮効果が確認されています。
.png)
前世代モデルとは異なり、LFM2.5-8B-A1Bは推論専用モデルであり、最終回答の前に明示的な思考過程を生成します。この方針を採用したのは、MoEモデルは一般に計算律速の環境で動作し、アクティブパラメータ数が少ないため、各推論トークンの生成コストが低く抑えられるためです。これにより、速度を損なうことなく、大幅な品質向上を実現できました。
推論機能と拡張されたトレーニングにより、この新バージョンは大幅に優れた性能を発揮します。
学習(モデルトレーニング)
トークナイザーの拡張: LFM2-8B-A1Bは当初、初期の対応言語範囲に最適化された65KのBPEトークナイザーで学習されていました。LFM2.5で非ラテン文字をより適切にサポートするため、モデルをゼロから再学習するのではなく、既存のトークナイザーをそのまま拡張する形で、語彙サイズを128Kへと倍増しました。
具体的には、多言語コーパス上で元のマージ規則からBPEマージ学習を継続しました。これにより、既存トークンIDの大部分を同一対応として維持しつつ、すべての新しいトークンが元のサブトークン列へ決定的に分解できるようになります。新たに追加された埋め込み行は、それぞれのサブトークン分解に対応する埋め込みの平均値で初期化し、共有される行は変更せずにコピーしました。その後、短い2段階の適応によって品質を回復しました。まず埋め込みのみを学習し、その後、モデル全体に対して継続事前学習を行いました。
下の表はchars/tokenを示しています。これは各トークンがどれだけのテキスト量を担っているかをおおまかに表す指標であり、値が高いほど優れています。新しいトークナイザーは、16言語すべてにおいて効率が向上しています。
コンテキスト拡張:まず、推論、数学、ツール利用、長文ドキュメントに重点を置いた2Tトークンのミッドトレーニング段階を通じて、コンテキスト長を32Kまで拡張しました。その後、RoPEのベースθを引き上げ、長文ドキュメントおよび長い軌跡データに重点を置いた追加の400Bトークンのミッドトレーニングを行うことで、コンテキスト長を128Kまで拡張しました。
Doom loop: 長い推論トレースにおけるdoom loopを減らすため、対象を絞った選好最適化段階を追加しました。この段階では、特定の文脈でループ挙動を引き起こしやすいトークンを特定し、次トークン分布の大部分はほぼ維持したまま、確率質量をもっともらしい代替候補へ再配分します。また、RL中には、「Wait…」のようなループを誘発しやすい一般的な再開語の過剰な使用を抑制する軽量なシェーピング報酬も追加しました。パイプライン全体、目的関数、実証結果の詳細については、今後の専用ブログ記事で紹介予定です。
ハルシネーション: エッジモデルはパラメータ数が少ないため、知識容量に限りがあり、ハルシネーションが発生しやすくなります。これを軽減するため、多様な知識データセット上でavg@kベースの報酬を用いる、対象を絞ったRL段階を追加しました。目的は、信頼できる知識の範囲を超えるクエリに対しては回答を控える姿勢を強化しつつ、既存の知識を維持することです。これにより、より明確な知識境界と、不確実性のより明瞭な表現が可能になります。
ベンチマーク
LFM2.5-8B-A1Bを、知識、命令追従、数学、エージェント型ワークフローを対象とする各種ベンチマークで評価しました。このモデルは、総パラメータ数が近いDenseモデルの代替案だけでなく、はるかに大規模なMoEモデルとも競争力のある性能を示しています。
avg@kベースの報酬により、LFM2.5-8B-A1Bは妥当な精度を維持しながら、ハルシネーション率を大幅に低減できます。また、命令追従ベンチマークでも優れた結果を示しており、アクティブパラメータ数を大幅に抑えながら、Gemma 4-26Bのようなより大規模なMoEモデルに匹敵する性能を発揮します。
数学およびエージェント型ワークフロー
エージェント型ベンチマークにおいて、LFM2.5-8B-A1Bはより大規模なモデルと競争力のある性能を示しており、特にTau2-Telecomで高い性能を発揮しています。エージェント型ハーネスがモデル活用の主要な手段になりつつある中で、LFM2.5-8B-A1Bはオンデバイスで完全にプライベートなエージェントを実現するための第一歩です。
あらゆる場所でのスパース推論
LFM2.5-8B-A1Bは、推論エコシステム全体において初日から対応しています:
- LEAP - iOSおよびAndroidへのデプロイに対応するLiquidのEdge AI Platform
- llama.cpp - 効率的なエッジ推論用GGUFチェックポイント
- MLX - Apple Silicon向け最適化された推論
- vLLM - 本番環境のスループットに対応するGPUアクセラレーション推論サービング
- SGLang - 本番環境のスループットに対応するGPUアクセラレーション推論サービング
- ONNX - 多様なアクセラレーターに対応するクロスプラットフォーム推論
CPU推論:LFM2.5-8B-A1Bはllama.cppを初日からサポートし、一般的なコンシューマー向けハードウェア上で動作します。

どちらのラップトップクラスのチップでも、このモデルは、プロンプトの読み込みと回答生成の両方において、私たちがテストした中で最速でした。M5 Maxでは253トークン/秒、Ryzen AI Max+ 395では146トークン/秒でデコードしながら、メモリ使用量は6GB未満に収まっています。さらにスマートフォン上でも約30トークン/秒を維持するため、高性能なアシスタントを、自分のデバイス上で即座に、かつプライベートに動作させることができます。
GPU推論: 私たちは、これらのコードベースへの積極的なコントリビューションを通じて、vLLMおよびSGLangによる推論をサポートしています。出力スループット(総出力トークン数を経過時間で割った値)は、単一のNVIDIA H100 SXM5 GPU上で、持続負荷の設定により測定しています。各並行度において、目標とする同時処理リクエスト数を常に維持し、完了したリクエストは直ちに新しいリクエストで置き換えました。
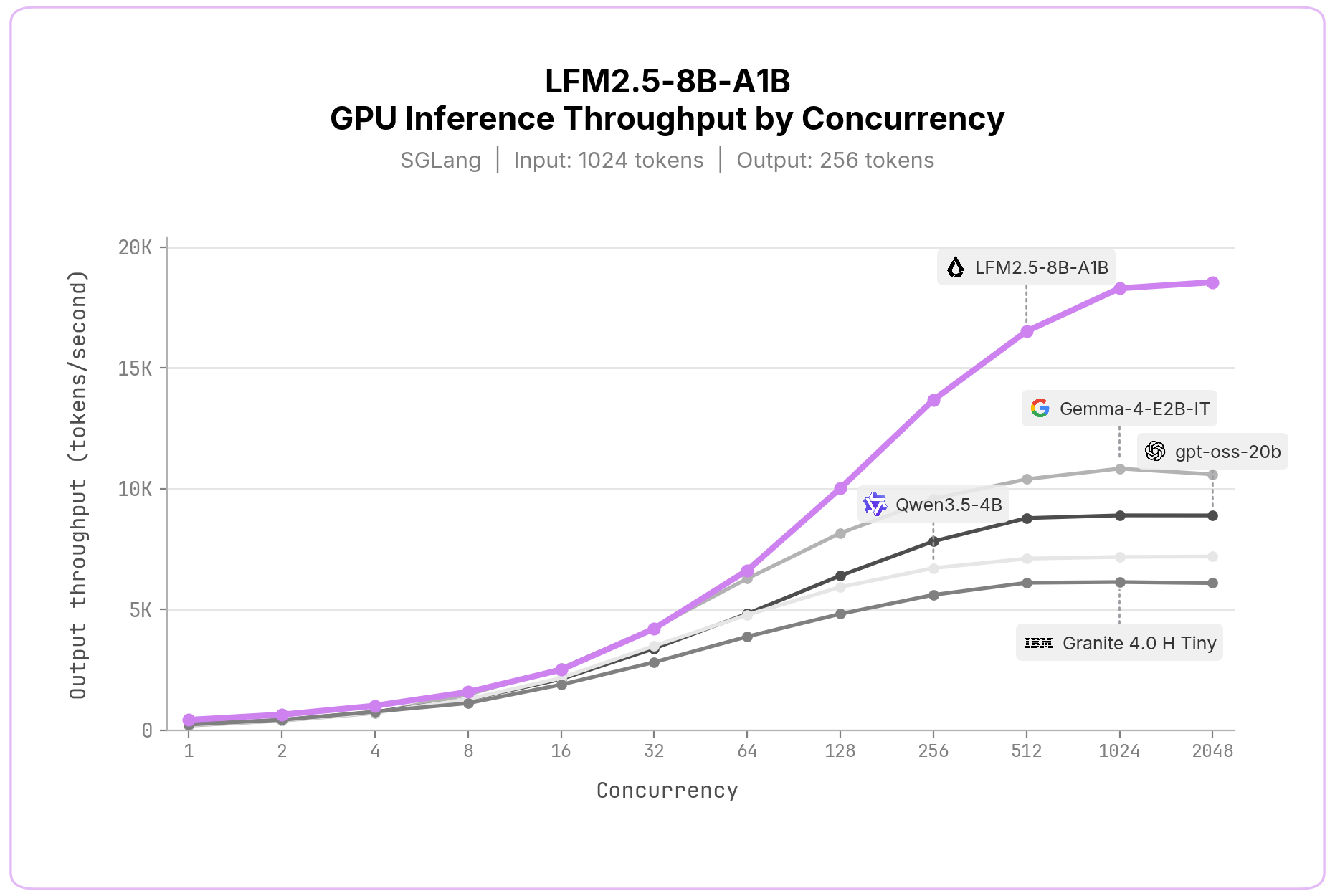
各モデルは、SGLang 0.5.12、1,024入力トークン、最大256出力トークン、BF16の設定でベンチマークし、各並行度について3回の実行結果を平均しました。LFM2.5-8B-A1Bは同サイズ帯で最速のモデルであり、高並行度では毎秒18.5K出力トークン、単一のH100上で1日あたり16億トークン超に達します
LocalCowork デモ
私たちのオープンソースのデスクトップエージェントデモであるLocalCoworkは、現在LFM2.5-8B-A1B上で動作しています。セットアップは、3月に公開したLFM2-24B-A2Bのデモで使用したものと同じです。単一のラップトップ、13のMCPサーバーにまたがる67のツール、クラウドなし、APIキーなし、データがマシン外に出ることもありません。同じツールメニューにおいて、ツール選択はより高速になり、信頼性も目に見えて向上しています。
このデモの主眼は、個々のツールそのものではありません。重要なのは、ツールディスパッチのループがコンシューマー向けハードウェア上でインタラクティブに感じられることです。依頼->提案->確認->実行->繰り返す。この一連の流れが、各ディスパッチあたり十分に1秒未満で完了し、完全な監査証跡を残しながら、データは一切デバイス外に出ません。
はじめよう
Hugging Face、そして私たちのPlaygroundで提供されているLFM2.5-8B-A1Bを使って、今すぐ開発を始めましょう。
LFM2.5により、私たちは「どこでも動くAI」というビジョンを実現します。これらのモデルは次のような特長を備えています。
- オープンウェイト - 制限なくダウンロード、ファインチューニング、デプロイが可能
- 初日から高速 - Apple、AMD、Intel、Qualcomm、Nvidiaの各ハードウェア上で、llama.cpp、MLX、vLLM、SGLangをネイティブサポート
- 完全なファミリー - カスタマイズ向けのベースモデルから、音声・視覚に特化したバリアントまで、ひとつのアーキテクチャで多様なユースケースをカバー
オンデバイス・エージェントの未来はここから始まります。皆さんが何を作るのか、私たちは楽しみにしています!