
LFM2.5-8B-A1B: An Even Better On-Device Mixture of Experts
Today, we're releasing LFM2.5-8B-A1B, an edge model built for fast, reliable tool calling on consumer hardware.
It builds on our LFM2-8B-A1B release from October 2025, with an expanded 128K context window, scaled-up pretraining (from 12T to 38T tokens), and large-scale reinforcement learning. We also doubled its vocabulary to improve tokenization efficiency for non-Latin languages. The result is a model that chains tool calls, achieves tasks, and fits comfortably even on an entry-level laptop.
The base (LFM2.5-8B-A1B-Base) and post-trained (LFM2.5-8B-A1B) models are available today on Hugging Face and our Playground. Check out our docs on how to run and fine-tune them locally.
What changed since LFM2-8B-A1B
Compared to LFM2-8B-A1B, this new version expands the context window from 32,768 to 128,000 tokens. This allows the model to process longer documents and reason for longer. Its vocabulary size was also scaled up from 65,536 to 128,000 to tokenize non-Latin scripts more efficiently. We see particularly strong compression gains in Hindi, Thai, Vietnamese, Indonesian, and Arabic. The rest of the architecture follows the same combination of MoE, GQA, and gated short convolution blocks as LFM2-8B-A1B, as shown in the following figure.
Unlike its predecessor, LFM2.5-8B-A1B is a reasoning-only model, producing an explicit chain of thought before its final answer. We adopted this strategy because MoE models generally run in compute-bound settings, where a smaller number of active parameters makes each reasoning token cheap. This provides a significant quality boost without compromising speed.
Thanks to reasoning and scaled-up training, this new version performs significantly better:
Benchmark | LFM2-8B-A1B | LFM2.5-8B-A1B | Δ |
|---|---|---|---|
AA-Omniscience Index | -78.42 | -24.70 | +53.62 |
AA-Omniscience Accuracy | 7.33 | 8.67 | +1.34 |
AA-Omniscience Non-Hallucination Rate | 7.46 | 63.47 | +56.01 |
IFEval | 79.44 | 91.84 | +12.40 |
IFBench | 26.00 | 56.47 | +30.47 |
Multi-IF | 58.54 | 79.93 | +21.39 |
MATH500 | 74.80 | 88.76 | +13.96 |
AIME25 | 20.00 | 42.53 | +22.53 |
BFCLv3 | 45.07 | 64.36 | +19.29 |
BFCLv4 | 25.52 | 48.50 | +22.98 |
Tau² Telecom | 13.60 | 88.07 | +74.47 |
Tau² Retail | 7.02 | 39.82 | +32.80 |
Training highlights
Tokenizer expansion. LFM2-8B-A1B was originally trained with a 65K BPE tokenizer optimized for our initial language coverage. To better support non-Latin scripts in LFM2.5, we doubled the vocabulary to 128K by extending the existing tokenizer in place rather than retraining the model from scratch.. We continued BPE merge training from the original merges on a multilingual corpus, which keeps most existing token IDs as identity mappings and makes every new token decompose deterministically into a sequence of original sub-tokens. We initialize the new embedding rows as the mean of their sub-token decompositions and copy the shared rows unchanged. We then recover quality through a brief two-stage adaptation: embedding-only training, followed by full-model continued pretraining.
The table below reports chars/token, roughly how much text each token carries: higher is better, and the new tokenizer is more efficient in all 16 languages
Tokenizer | Arabic (ar) | German (de) | English (en) | Spanish (es) | French (fr) | Hindi (hi) | Indonesian (id) | Italian (it) | Japanese (ja) | Korean (ko) | Polish (pl) | Portuguese (pt) | Russian (ru) | Thai (th) | Vietnamese (vi) | Chinese (zh) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Old tokenizer | 2.239 | 3.641 | 4.063 | 3.442 | 3.618 | 0.961 | 2.731 | 3.251 | 1.836 | 1.652 | 2.672 | 3.194 | 2.703 | 0.671 | 1.519 | 1.475 |
New tokenizer | 3.107 | 3.783 | 4.137 | 3.579 | 3.759 | 2.118 | 3.513 | 3.475 | 1.963 | 1.943 | 2.895 | 3.450 | 2.876 | 2.269 | 3.311 | 1.620 |
Improvement | +38.8% | +3.9% | +1.8% | +4.0% | +3.9% | +120.4% | +28.6% | +6.9% | +6.9% | +17.6% | +8.3% | +8.0% | +6.4% | +238.2% | +117.9% | +9.8% |
Context extension. We first extended the context window to 32K through a 2T token midtraining phase focused on reasoning, math, tool-use, and longer documents. We then extended the context to 128K by increasing the RoPE base θ and running an additional 400B token midtraining stage focused on long-document and long-trajectory data.
Doom loops. We added a targeted preference optimization stage to reduce doom loops in long reasoning traces. This stage identifies tokens that tend to trigger looping behavior in specific contexts, then redistributes probability mass toward plausible alternatives, while leaving the rest of the next-token distribution largely intact. During RL, we also added a lightweight shaping reward that discourages excessive use of common loop-inducing restart words like “Wait…”. We'll share more details on the full pipeline, objective, and empirical results in a dedicated blog post.
Hallucinations. Because of their small number of parameters, edge models have a limited knowledge capacity, which leads to more hallucinations. To mitigate hallucinations, we added a targeted RL stage that uses an avg@k-based reward over a diverse knowledge dataset. The goal is to reinforce abstention on queries beyond reliable knowledge while preserving existing knowledge. This produces a sharper knowledge boundary and clearer expression of uncertainty.
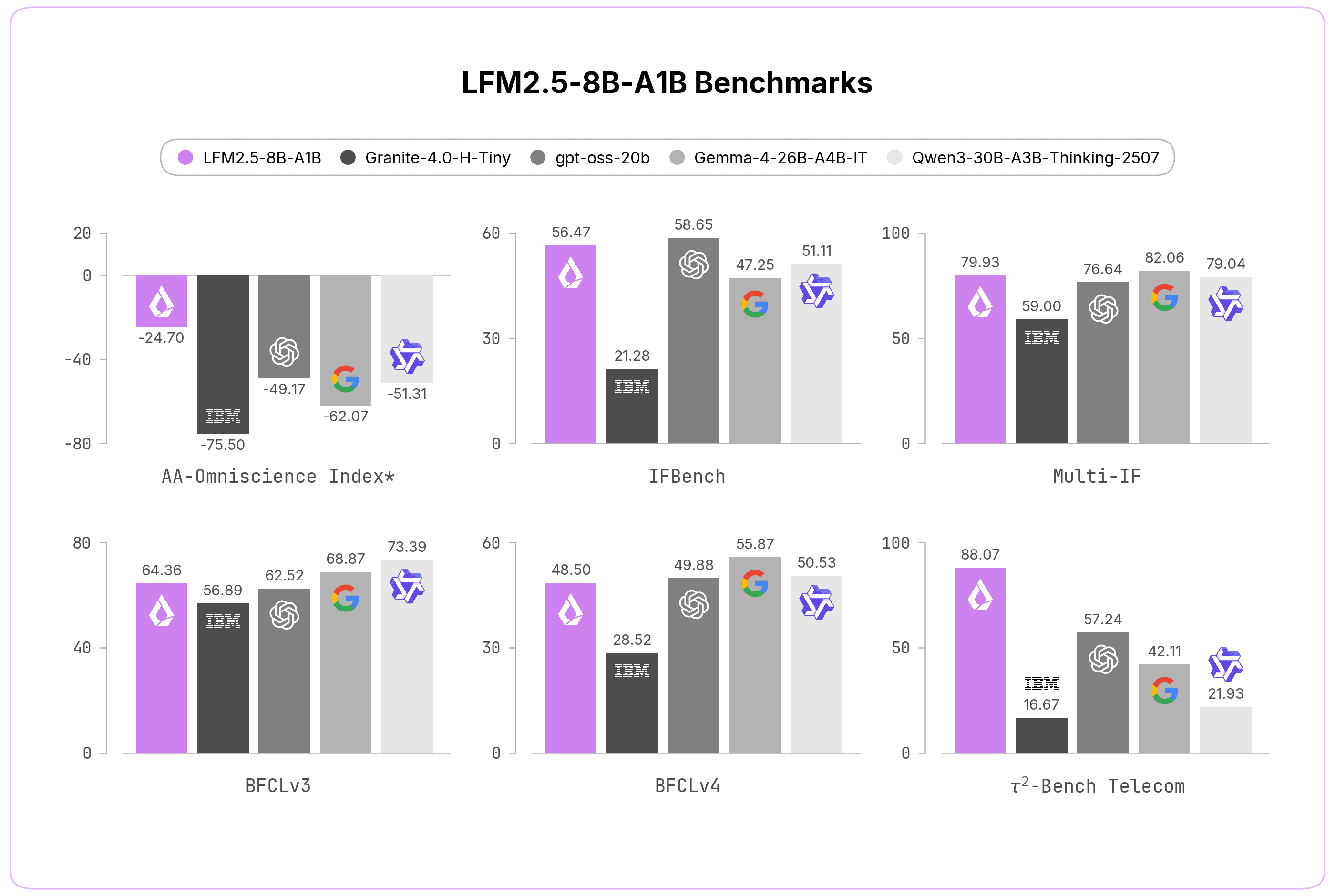
Benchmarks
We evaluated LFM2.5-8B-A1B across benchmarks covering knowledge, instruction following, math, and agentic workflows. The model is competitive with both dense alternatives with a similar total number of parameters and much larger MoEs.
Model | Parameters | AA-Omniscience | Instruction following | ||||
|---|---|---|---|---|---|---|---|
Index | Accuracy | Non-Hallucination | IFEval | IFBench | Multi-IF | ||
LFM2.5-8B-A1B | 8B/A1B | -24.70 | 8.67 | 63.47 | 91.84 | 56.47 | 79.93 |
Granite-4.0-H-Tiny | 7B/A1B | -75.50 | 9.37 | 6.38 | 82.23 | 21.28 | 59.00 |
Qwen3.5-4B | 4B | -51.53 | 17.20 | 16.99 | 87.80 | 50.38 | 67.43 |
Qwen3-30B-A3B-Thinking-2507 | 30.5B/3.3B | -51.31 | 18.80 | 13.87 | 90.82 | 51.11 | 79.04 |
Gemma-4-E2B-IT | 5.1B | -72 | 7.00 | 15.05 | 82.93 | 33.53 | 69.70 |
Gemma-4-E4B-IT | 8B | -50.67 | 8.10 | 36.06 | 87.74 | 39.48 | 77.58 |
Gemma-4-26B-A4B-IT | 26B/4B | -62.07 | 14.37 | 10.75 | 91.40 | 47.25 | 82.06 |
gpt-oss-20b | 21B/3.6B | -49.17 | 14.57 | 24.50 | 86.73 | 58.65 | 76.64 |
The avg@k-based reward enables LFM2.5-8B-A1B to achieve a significantly lower hallucination rate while maintaining reasonable accuracy. It also leads on instruction following benchmarks, matching bigger MoEs like Gemma 4-26B at a fraction of the active parameter count.
Math and agentic workflows
Model | Parameters | Math | Tool use | |||||
|---|---|---|---|---|---|---|---|---|
MATH500 | AIME25 | AIME26 | BFCLv3 | BFCLv4 | Tau² Telecom | Tau² Retail | ||
LFM2.5-8B-A1B | 8B/A1B | 88.76 | 42.53 | 50.00 | 64.79 | 49.73 | 88.07 | 39.82 |
Granite-4.0-H-Tiny | 7B/A1B | 59.20 | 4.93 | 3.33 | 56.89 | 28.52 | 16.67 | 18.42 |
Qwen3.5-4B | 4B | 80.76 | 54.28 | 58.33 | 71.06 | 54.01 | 87.72 | 71.93 |
Qwen3-30B-A3B-Thinking-2507 | 30.5B/3.3B | 86.48 | 71.67 | 66.67 | 73.39 | 50.53 | 21.93 | 56.14 |
Gemma-4-E2B-IT | 5.1B | 64.00 | 26 | 30 | 56.44 | 31.91 | 22.37 | 18.95 |
Gemma-4-E4B-IT | 8B | 65.00 | 34.33 | 40.67 | 57.31 | 33.92 | 26.75 | 42.11 |
Gemma-4-26B-A4B-IT | 26B/4B | 94.20 | 68.67 | 72.00 | 68.87 | 55.87 | 42.11 | 55.26 |
gpt-oss-20b | 21B/3.6B | 92.40 | 68.53 | 68.67 | 62.52 | 49.88 | 57.24 | 53.51 |
On agentic benchmarks, LFM2.5-8B-A1B is competitive with bigger models and particularly strong on Tau2-Telecom. As agentic harnesses are becoming the main way to consume models, LFM2.5-8B-A1B is a first step towards powering on-device, fully private agents.
Sparse Inference, Everywhere
LFM2.5-8B-A1B ships with day-one support across the inference ecosystem:
- LEAP — Liquid's Edge AI Platform for iOS and Android deployment
- llama.cpp — GGUF checkpoints for efficient edge inference
- MLX — Optimized inference for Apple Silicon
- vLLM — GPU-accelerated serving for production throughput
- SGLang — GPU-accelerated serving for production throughput
- ONNX — Cross-platform inference across diverse accelerators
CPU inference. LFM2.5-8B-A1B ships with day-one llama.cpp support and runs on everyday consumer hardware.
On both laptop-class chips, it is the fastest model we tested at reading in prompts and generating answers, decoding 253 tokens/s on an M5 Max and 146 on a Ryzen AI Max+ 395 while staying under 6 GB. It even holds ~30 tokens/s on a phone, so a capable assistant runs instantly and privately on your own device.
GPU inference. We support inference via vLLM and SGLang via active contributions to these codebases. We measure output throughput (total output tokens divided by wall time) on a single NVIDIA H100 SXM5 GPU using a sustained-load setting: at each concurrency level, we continuously maintain the target number of in-flight requests, replacing each completed request immediately.
We benchmark each model with SGLang 0.5.12, 1,024 input tokens, up to 256 output tokens, in BF16, averaging 3 runs per concurrency level. LFM2.5-8B-A1B is the fastest model in its size class, reaching 18.5K output tokens per second at high concurrency, over 1.6B tokens per day on a single H100.
Local Cowork: see it run
Our open-source desktop agent demo, Localcowork, now runs on LFM2.5-8B-A1B. The setup is the same one we used for LFM2-24B-A2B demo in March: a single laptop, 67 tools across 13 MCP servers, no cloud, no API keys, no data leaving the machine. Tool selection is faster and noticeably more reliable across the same tool menu.
The point of the demo is not the individual tools. It is that the tool-dispatch loop feels interactive on consumer hardware: ask, propose, confirm, run, repeat, all in well under a second per dispatch, with full audit trails and your data never leaving the device.
Get Started
With LFM2.5, we're delivering on our vision of AI that runs anywhere. These models are:
- Open-weight — Download, fine-tune, and deploy without restrictions
- Fast from day one — Native support for llama.cpp, MLX, vLLM, SGLang across Apple, AMD, Intel, Qualcomm, and Nvidia hardware
- A complete family — From base models for customization to specialized audio and vision variants, one architecture covers diverse use cases
The on-device agentic future starts here. We can't wait to see what you build.
Please cite this article using the following reference or BibTeX:
Liquid AI, “LFM2.5-8B-A1B: Personal Assistant On Your Laptop,” Liquid AI Blog, May 2026.
@article{liquidAI20268BA1B,
author = {Liquid AI},
title = {LFM2.5-8B-A1B: Personal Assistant On Your Laptop},
journal = {Liquid AI Blog},
year = {2026},
note = {https://www.liquid.ai/blog/lfm2-5-8b-a1b},
}