See what developers and the community are saying about #Liquid AI #LFM#LEAP#Liquid Apollo
In my limited experience testing various nano/tiny/small models from various labs, LFM2-1.2B was galaxies ahead of competitors. It's 1.2B but really behaves more like a ~10B model in terms of coherence and reasoning power. Even their smaller ~300M model feels more like a 4B, which is mind blowing because it runs fast even on a CPU (hell, it runs fast even on a browser via WebAssembly, unfathomably amazing). I'm hoping that these specialized models will be very good, I have a good amount of trust in Liquid AI.
Damn you guys keep knocking it out of the park. Congratulations on all the amazing releases. Im still trying to fully utilize LFM2-1.2B then you drop new weights. So fun to be here and experience the fruits of your toil. Thanks for looking out for those of us with less computational capacities. Its amazing how far small models have come and you're an integral part of that puzzle. Best wishes
@TheAhmadOsman These are big names the real benificial models are the ones that are bringing the cost of intelehence down namely the 1-10 b prams pioneerd by the likes of @liquidai and @GeminiApp with gemma with their amazing 1 b prams model which can run inside your mobile phones natively
450M vision model runs at 353 tokens/sec on MLX using just 1.456GB memory 🔥. LiquidAI drops LFM2-VL-450M → MLX-VLM community with @Prince_Canuma ports it → Your Mac becomes a vision AI beast. Liquid neurons adapting computation on the fly. 450M params punching way above its weight class. Open source wins again. Model drops, community delivers, boom - it's local. What are you building with instant vision AI?
Great leap in on-device AI: Liquid's new LFM2.5-1.2B-Thinking does genuine step-by-step reasoning using just ~900 MB RAM, runs on basically any modern phone. Beats larger models like Qwen3-1.7B on math/tool use while being dramatically faster & leaner. Privacy + zero-latency
Liquid AI LFM 2.5 1.2B Thinking Model Outperforms Larger Models on Reasoning Benchmarks
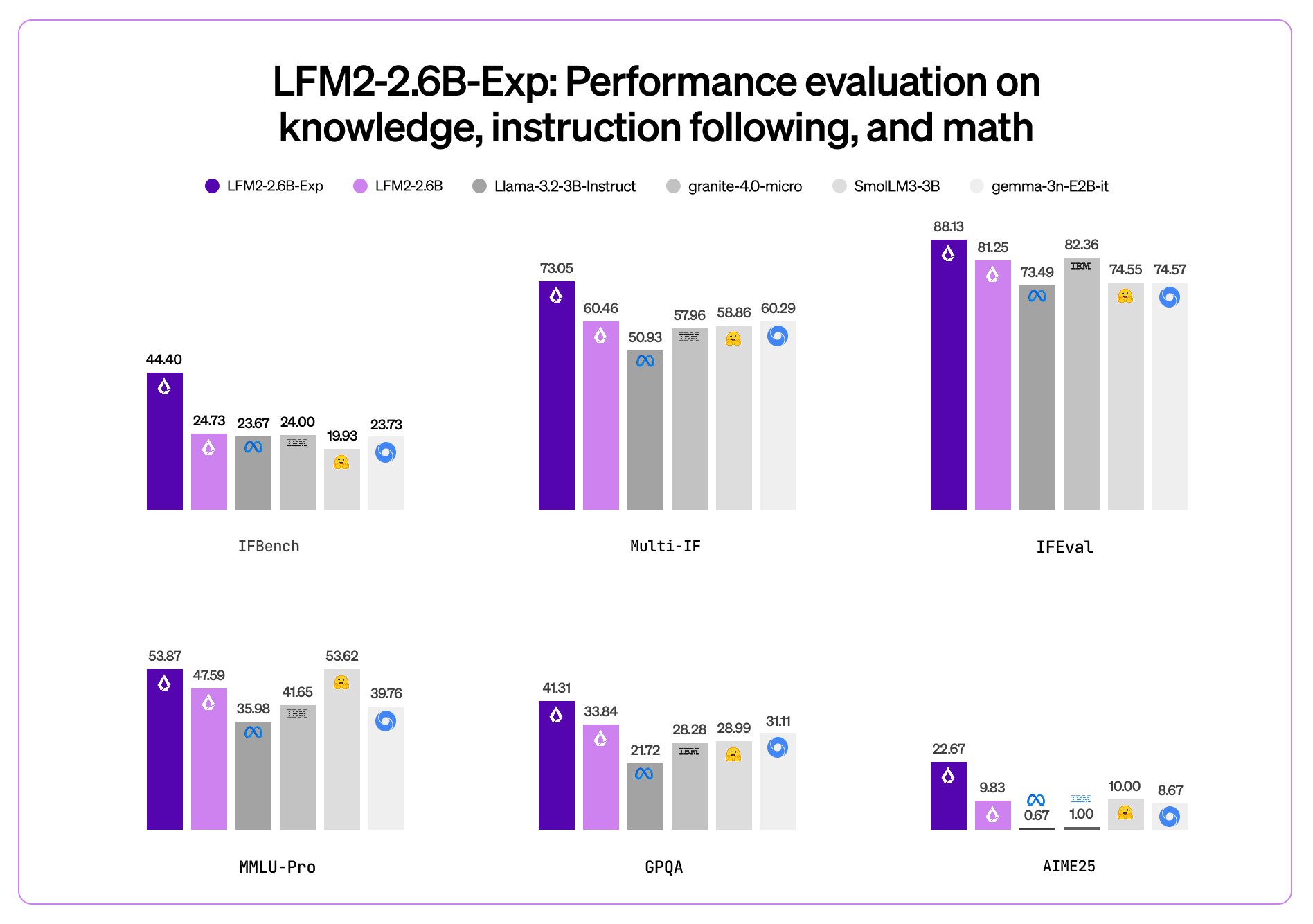
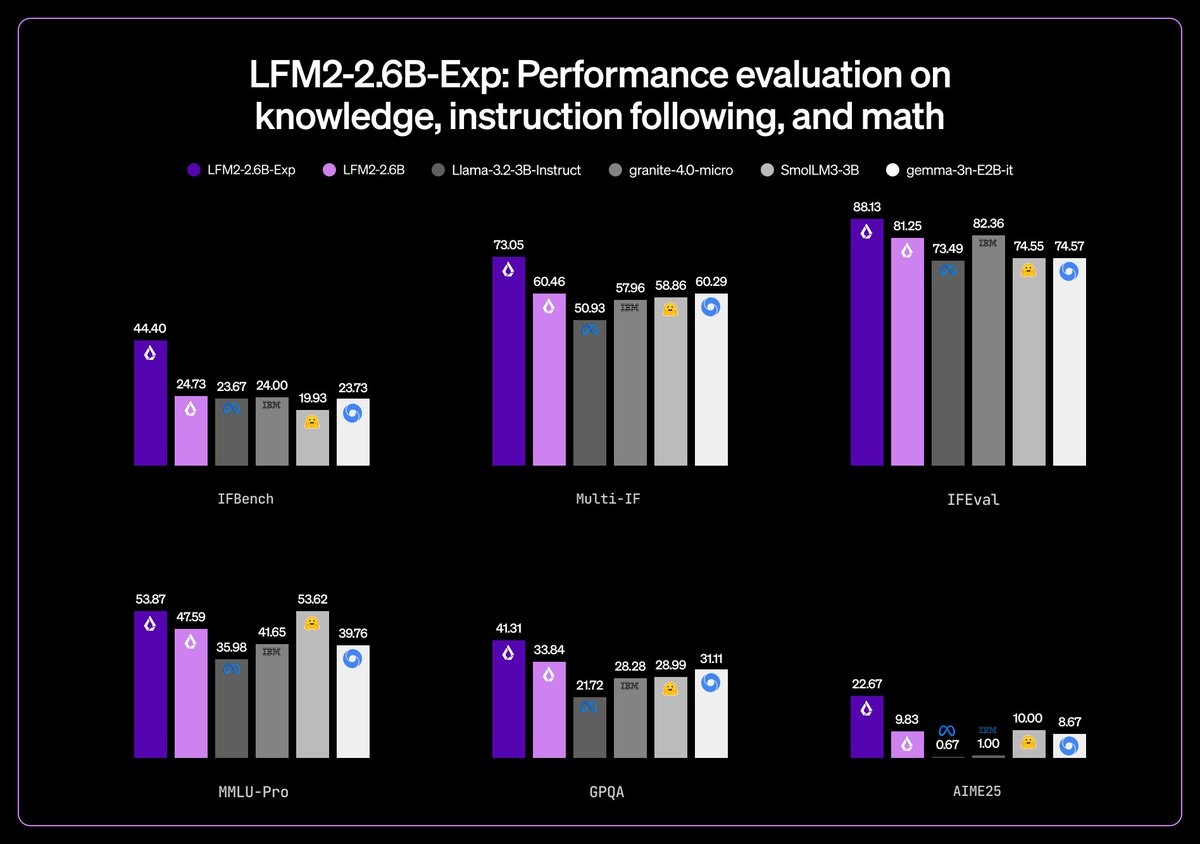
Liquid AI just dropped the LFM-2.5-1.2B-Thinking, a tiny 1.2 billion parameter model designed for fast, private reasoning right on your device. It runs completely offline and uses less than 900MB of memory, perfect for phones and edge devices without any drop in capability. What sets it apart is its clean, straight-to-the-point reasoning traces, blazing-fast inference, and excellent performance on instruction following, tool use, and math problems.Benchmarks show it beating much bigger models like Qwen3-17B in thinking mode on tests such as GPQA Diamond (37.86%), MMLU-Pro (49.65%), and....
LFM2 GGUF models just dropped for llama.cpp - these are game changers. 2x faster than Qwen3 on CPU, 200% higher throughput vs competitors, designed for edge deployment. Finally, high-performance models that actually run well locally: https://huggingface.co/LiquidAI/LFM2-1.2B-GGUF
Game-changing on-device AI just dropped. 🤯Liquid AI unleashed LFM2-Audio, a 1.5B param speech model with a crazy low 95ms latency—that's literally the speed of a blink. This is huge. Try it here: https://playground.liquid.ai/login?callbackUrl=%2FtalkBut
that's not all... 🧵
LiquidAI LFM2.5-1.2B Review: The best free model for high-speed utilityI’ve been hunting for a model that doesn't feel like a sluggish Transformer for high-frequency, low-latency tasks. I finally spent a few days with LiquidAI’s LFM2.5-1.2B-Instruct, and honestly, the performance profile of this Liquid Neural Network (LNN) architecture is a game changer for edge-style utility. The Use Case I set up a real-time monitor for a cluster of web servers...
@LiquidAI_ Congratulations on the launch of LFM2-8B-A1B! Achieving performance comparable to larger models while significantly enhancing inference speed is a remarkable feat. The efficiency of on-device MoE is crucial for real-time applications. I'm excited to see how this innovation will
🚨 GAME CHANGER ALERT: MIT just broke the AI game! 🤯 Liquid AI's new models are DESTROYING traditional LLMs and here's why this is HUGE 👇✨ Uses 90% FEWER neurons but performs BETTER 🚀 Handles 1 MILLION tokens with minimal memory 💡 Perfect for edge devices (your phone could run this!) 🔥 LFM-1B is setting NEW records on every benchmark. While everyone's obsessing over bigger models, Liquid AI said "hold my beer" and went LIQUID 💧 This isn't just an upgrade - it's a complete paradigm shift. Traditional transformers are about to look like flip phones 📱➡️🧠The future of AI just got a lot more interesting... and efficient! 🌟 What do you think? Are liquid neural networks the future? Drop your thoughts below! 👇#LiquidAI #AI #MachineLearning #TechNews #Innovation #MIT #NeuralNetworks #ArtificialIntelligence #TechBreakthrough #FutureOfAI
.svg)

.avif)

HOLY SPEED BATMAN. THIS THING RIPS ON MY MAC BOOK PRO.
Liquid AI drops model and we are racing to test it. #ai #model #24b #moe
Right off the rip its destroying my future use of Anthropic and OpenAI. LFG! Mathias Lechner / Ramin Hasani - Kudos. Looking so nice!
Link:
https://lnkd.in/eyve6hrN