Text Models
LFMs deliver powerful performance in a lightweight, customizable, and compute-efficient footprint for deployment in any environment.
We’ve redefined what’s possible with our proprietary architecture, designed for efficiency, speed, and real-world deployment on any device.
From wearables to robotics, phones, laptops, cars, and more, LFMs run seamlessly on GPUs, CPUs, or NPUs, making intelligence accessible everywhere.
All our models leverage Liquid Neural Networks, a proprietary architecture rooted in dynamical systems and signal processing, to deliver frontier-grade intelligence at a fraction of the compute, on any hardware, on or off the cloud.
Every LFM is free to download, run, and fine-tune — including commercially — until your company passes $10M in annual revenue. See pricing & licensing
LFMs deliver powerful performance in a lightweight, customizable, and compute-efficient footprint for deployment in any environment.
Multimodal models using vision and text inputs and outputs with capabilities designed for low latency and device aware deployment.
End-to-end foundation model for audio and text generation. Designed for low latency, it enables responsive, high-quality conversations with only 1.5 billion parameters.
Tiny customized models for specific tasks and knowledge.
Unmatched speed, quality, and memory-efficiency on the edge, or in the cloud.
Whether deploying on smartphones, laptops, vehicles, or any other device, LFMs run efficiently on CPU, GPU, and NPU hardware. Designed for millisecond latency, on-device resilience, and data privacy, LFMs unlock the full potential of local, cloud, and hybrid AI across industries.
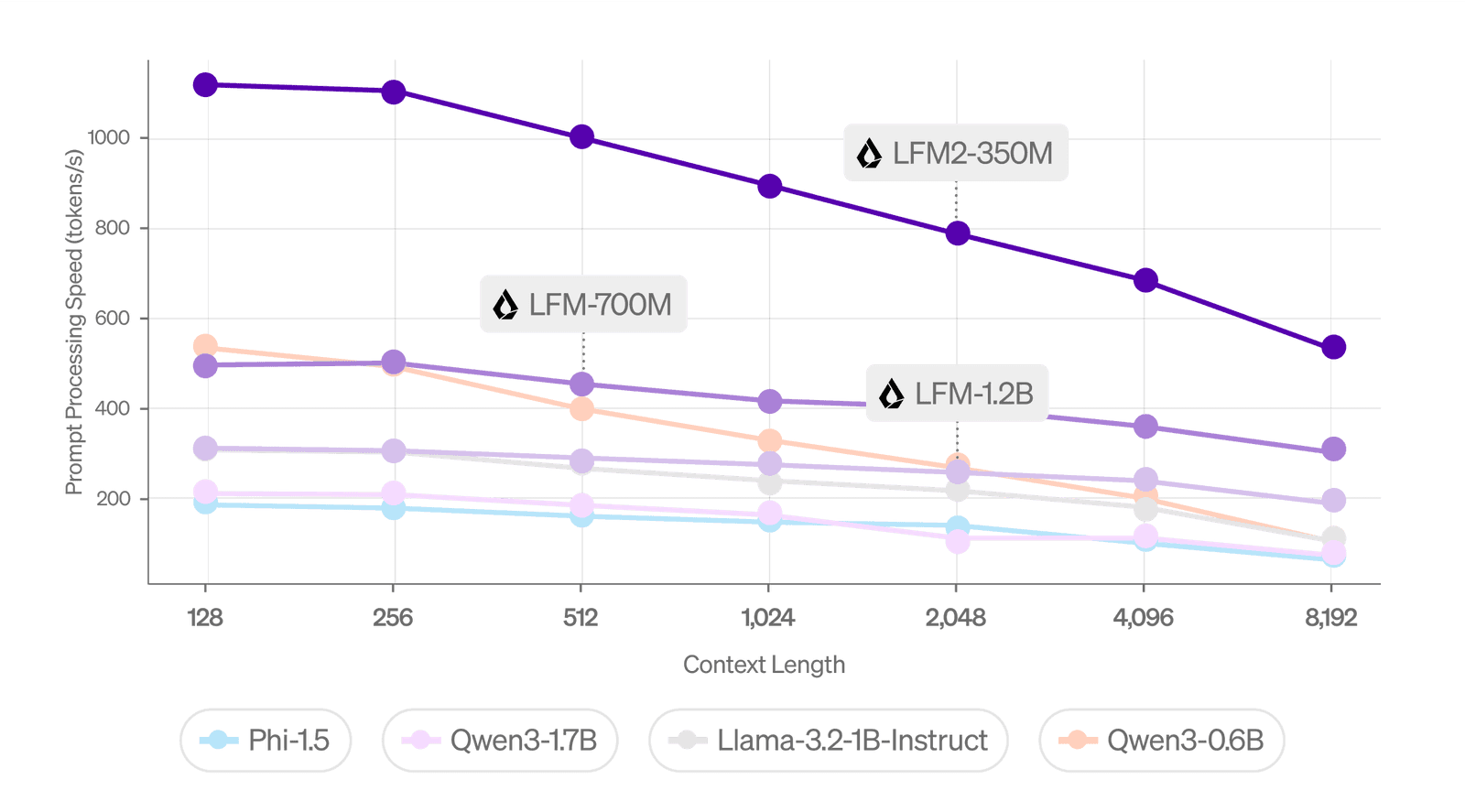
Fig. 1. Prefill performance on CPU in ExecuTorch

