
Introducing LFM2: The Fastest On-Device Foundation Models on the Market
Today, we release LFM2, a new class of Liquid Foundation Models (LFMs) that sets a new standard in quality, speed, and memory efficiency deployment. LFM2 is specifically designed to provide the fastest on-device gen-AI experience across the industry, thus unlocking a massive number of devices for generative AI workloads. Built on a new hybrid architecture, LFM2 delivers 2x faster decode and prefill performance than Qwen3 on CPU. It also significantly outperforms models in each size class, making them ideal for powering efficient AI agents.
These performance gains make LFM2 the ideal choice for local and edge use cases. Beyond deployment benefits, our new architecture and training infrastructure deliver a 3x improvement in training efficiency over the previous LFM generation, establishing LFM2 as the most cost-effective path to building capable, general-purpose AI systems.
At Liquid, we build foundation models that achieve the optimal balance between quality, latency, and memory for specific tasks and hardware requirements. Full control over this balance is critical for deploying best-in-class generative models on any device. This is exactly the type of control our products allow for enterprise.
Shifting large generative models from distant clouds to lean, on‑device LLMs unlocks millisecond latency, on-device resilience, and data‑sovereign privacy. These are capabilities essential for phones, laptops, cars, robots, wearables, satellites, and other endpoints that must reason in real time. Aggregating high‑growth verticals such as edge AI stack in consumer electronics, robotics, smart appliances, finance, e-commerce, and education, before counting defense, space, and cybersecurity allocations, pushes the TAM for compact, private foundation models toward the $1 trillion mark by 2035.
At Liquid, we are engaged with a large number of Fortune 500 companies in these sectors. We offer ultra‑efficient small multimodal foundation models with a secure enterprise-grade deployment stack that turns every device into an AI device, locally. This gives us the opportunity to obtain an outsized share on the market as enterprises pivot from cloud LLMs to cost-efficient, fast, private, and on‑prem intelligence.
Quick picks on LFM2
Fast training & inference
LFM2 achieves 3x faster training compared to its previous generation. It also benefits from up to 2x faster decode and prefill speed on CPU compared and Qwen3.
Best performance
LFM2 outperforms similarly-sized models across multiple benchmark categories, including knowledge, mathematics, instruction following, and multilingual capabilities.
New architecture
LFM2 is a hybrid Liquid model with multiplicative gates and short convolutions. It consists of 16 blocks: 10 double-gated short-range convolution blocks and 6 blocks of grouped query attention.
Flexible deployment
Whether deploying on smartphones, laptops, or vehicles, LFM2 runs efficiently on CPU, GPU, and NPU hardware. Our full-stack solution includes architecture, optimization, and deployment engines to accelerate the path from prototype to product.
Try now
We’re releasing the weights of three dense checkpoints with 0.35B, 0.7B, and 1.2B parameters. Try them now on the Liquid Playground, Hugging Face, and OpenRouter.
Try LFMs on
Benchmarks
We evaluated LFM2 using automated benchmarks and an LLM-as-a-Judge framework to obtain a comprehensive overview of its capabilities.
Automated benchmarks
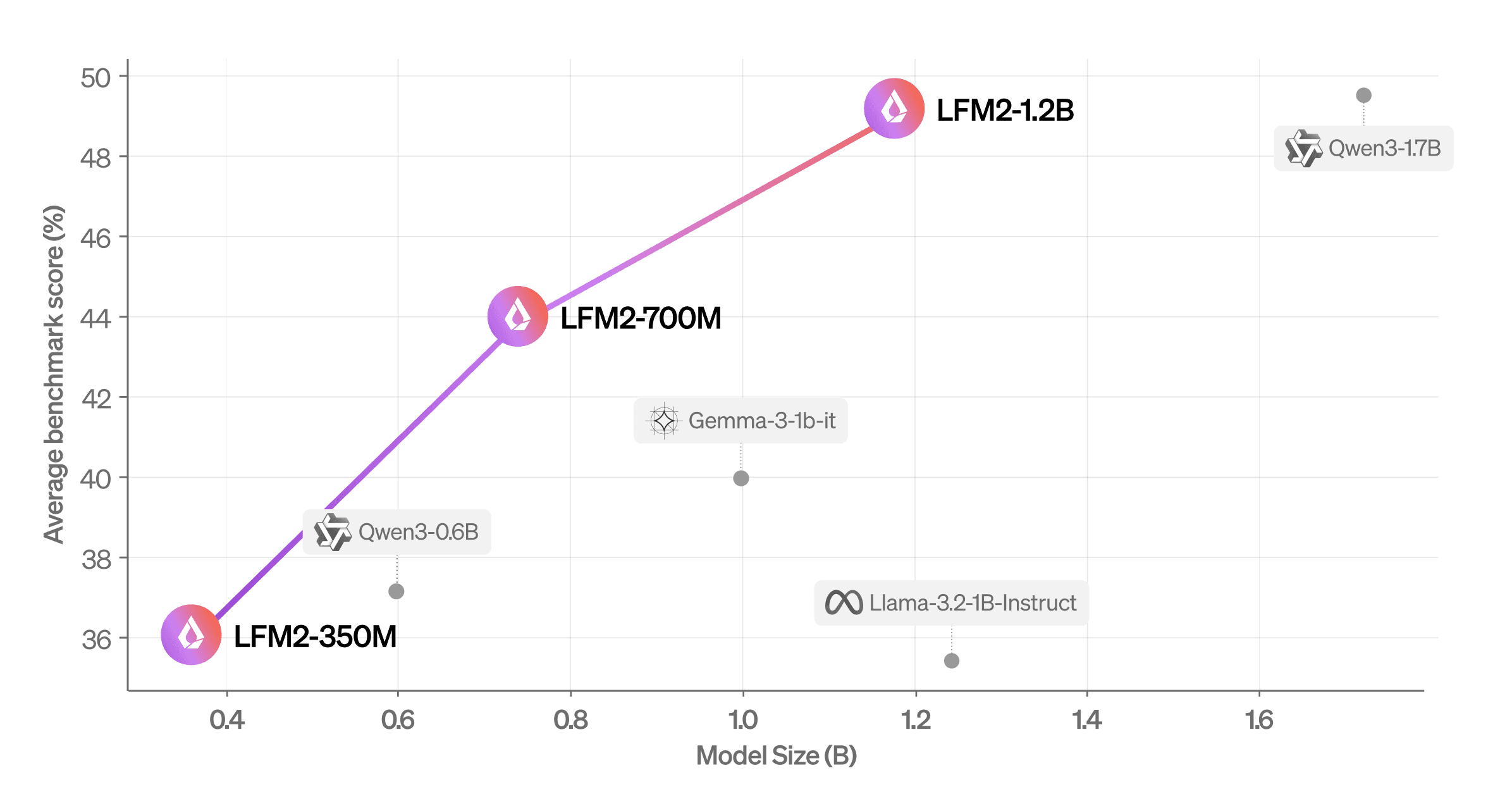
LFM2 outperforms similar-sized models across different evaluation categories. We evaluated LFM2 across seven popular benchmarks covering knowledge (5-shot MMLU, 0-shot GPQA), instruction following (IFEval, IFBench), mathematics (0-shot GSM8K, 5-shot MGSM), and multilingualism (5-shot OpenAI MMMLU, 5-shot MGSM again) with seven languages (Arabic, French, German, Spanish, Japanese, Korean, and Chinese).
LFM2-1.2B performs competitively with Qwen3-1.7B, a model with a 47% bigger parameter count. LFM2-700M outperforms Gemma 3 1B IT, and our tiniest checkpoint, LFM2-350M, is competitive with Qwen3-0.6B and Llama 3.2 1B Instruct.
Benchmarks | LFM2-350M | LFM2-700M | LFM2-1.2B | Qwen3-0.6B | Qwen3-1.7B | Llama-3.2-1B-Instruct | gemma-3-1b-it |
|---|---|---|---|---|---|---|---|
MMLU | 43.43 | 49.9 | 55.23 | 44.93 | 59.11 | 46.6 | 40.08 |
GPQA | 27.46 | 28.48 | 31.47 | 22.14 | 27.72 | 28.84 | 21.07 |
IFEval | 65.12 | 72.23 | 74.89 | 64.24 | 73.98 | 52.39 | 62.9 |
IFBench | 16.41 | 20.56 | 20.7 | 19.75 | 21.27 | 16.86 | 17.72 |
GSM8K | 30.1 | 46.4 | 58.3 | 36.47 | 51.4 | 35.71 | 59.59 |
MGSM | 29.52 | 45.36 | 55.04 | 41.28 | 66.56 | 29.12 | 43.6 |
MMMLU | 37.99 | 43.28 | 46.73 | 30.84 | 46.51 | 38.15 | 34.43 |
All benchmark scores were calculated using our internal evaluation suite for consistency. We made several changes compared to EleutherAI’s lm-evaluation-harness:
- We decode and strip the most likely logit for logit-based evaluations, such as MMLU. This ensures a valid comparison without whitespaces (“A” instead of “ A”).
- Based on work related to reasoning models, we consolidated the answer extraction for math benchmarks. This particularly improved results for Gemma 3 1B IT.
- We evaluated Qwen3 in non-reasoning mode only, which consistently improved scores because reasoning traces tend to be longer than the output token budgets relevant for edge deployment (<4,096 tokens).
LLM-as-a-Judge
In addition, we assessed the conversational capabilities of LFM2-1.2B, especially in multi-turn dialogues. In this exercise, we used 1,000 real-world conversations from the WildChat dataset and asked each model to generate answers. Finally, a jury of five LLMs reviewed these answers in a pairwise manner to provide preferences.
LFM2-1.2B is significantly preferred compared to Llama 3.2 1B Instruct and Gemma 3 1B IT. It is also on par with Qwen3-1.7B, despite being significantly smaller and faster to run.
LFM2-700M’s answers are significantly preferred over Qwen3-0.6B’s. LFM2-350M performs competitively against Qwen3-0.6B, with nearly balanced preference scores despite being smaller in size.
Inference
We exported LFM2 to multiple inference frameworks to accommodate a variety of deployment scenarios. For on-device inference, we leveraged both the PyTorch ecosystem via ExecuTorch and the open-source llama.cpp library. The LFM2 models were evaluated using each platform's recommended quantization schemes - 8da4w for ExecuTorch and Q4_0 for llama.cpp - and benchmarked against existing models available in those ecosystems. Target hardware included the Samsung Galaxy S24 Ultra (Qualcomm Snapdragon SoC) and AMD Ryzen (HX370) platforms.
Throughput comparison on CPU in ExecuTorch
Throughput comparison on CPU in Llama.cpp
As shown in the figures, LFM2 dominates the Pareto frontier for both prefill (prompt processing) and decode (token generation) inference speed relative to model size. For example, LFM2-700M is consistently faster than Qwen-0.6B on both decode and prefill speed in ExecuTorch and llama.cpp, despite being 16% larger. The strong CPU performance of LFM2 will transfer to accelerators such as GPU and NPU after kernel optimization.
LFM2 Architecture
In the following, we describe how we design Liquid Foundation Models by drawing from the family of Liquid time-constant networks.
Background
In [Hasani & Lechner et al. 2018 and 2020], we introduced Liquid Time-constant Networks (LTCs), a new class of continuous-time recurrent neural networks (RNNs) of linear dynamical systems modulated by nonlinear input interlinked gates as follows:
where x(t) is the input, y(t) is the state, T(.) & F(.) are nonlinear maps, and A is a constant regulator.
In particular, the gates in LTCs are a continuous-time generalization of input- & state- dependent gating in RNNs for sequence modeling. This property allows us to have finer temporal control over the evolution of the system, enabling the learning of complex “liquid” dynamics from data. In the years since, numerous studies from our team and the machine learning community have integrated the concept in RNNs, state-space models [Hasani & Lechner et al. 2022], and convolutions [Poli & Massaroli et al. 2023].
Systematic Neural Architecture Search in LIV Operators
To unify the architecture design space of efficient Liquid systems, we developed the concept of linear input-varying (LIV) operators [Thomas et al. 2024]. A Linear Input-Varying (LIV) system is a linear operator whose weights are generated on-the-fly from the input it is acting on, letting convolutions, recurrences, attention and other structured layers fall under one unified, input-aware framework.
More formally, an LIV operator can be expressed by the equation:
Where x is the input, and T is an input-dependent weight matrix.
The flexibility of LIV allows us to easily define and describe a wide range of neural network operators and layers in a shared hierarchical format. We built STAR, our neural architecture search engine, to find an optimal neural architecture given quality, memory, and latency criteria for deployment.
LFM2
Our goal with LFM2 was to provide the fastest generative AI experience on embedded SoCs without any compromise. To realize our vision, we employed STAR. However, we applied key modifications to the main algorithm described in STAR’s academic paper:
- To evaluate language modeling capabilities, we move beyond traditional validation loss and perplexity metrics. Instead, we employ a comprehensive suite of over 50 internal evaluations that assess diverse capabilities, including knowledge recall, multi-hop reasoning, understanding of low-resource languages, instruction following, and tool use.
- Similarly, we take a direct approach to measuring architectural efficiency rather than using KV cache size as a proxy. We run actual tests to measure and optimize peak memory usage and prefill+decode speed on Qualcomm Snapdragon embedded SoC CPUs.
The final architecture found by STAR is LFM2, a Liquid model with multiplicative gates and short convolutions, i.e., linear first-order systems converging to zero after a finite time. LFM2 is a hybrid of convolution and attention blocks. There are 16 blocks in total, of which 10 are double-gated short-range LIV convolutions of the form below:
def lfm2_conv(x):
B, C, x = linear(x) # input projection
x = B*x # gating (gate depends on input)
x = conv(x) # short conv
x = C*x # gating
x = linear(x)
return xThere are also 6 blocks of grouped query attention (GQA), and each block contains a SwiGLU and an RMSNorm layer.
Note that the structure and reliance of LFM2 on short convolutions instead of full recurrences or attention layers originates from the target device class, the embedded SoC CPU, as well as the underlying kernel libraries being optimized for these types of workloads and operations. We are actively optimizing LFMs for domain-specific accelerators (e.g., GPUs and NPUs), enlarging the search space, and eventually co-evolving the hardware jointly with the model architecture.
Training LFM2
For our first training scale-up of LFM2, we selected three model sizes (350M, 700M, and 1.2B parameters) targeting low-latency on-device language model workloads. All models were trained on 10T tokens drawn from a pre-training corpus comprising approximately 75% English, 20% multilingual, and 5% code data sourced from the web and licensed materials. For the multilingual capabilities of LFM2 we primarily focus on Japanese, Arabic, Korean, Spanish, French, and German languages.
During pre-training, we leveraged our existing LFM1-7B as a teacher model in a knowledge distillation framework. We used the cross-entropy between LFM2's student outputs and the LFM1-7B teacher outputs as the primary training signal throughout the entire 10T token training process. The context length was extended during pretraining to 32k.
Post-training starts with a very large-scale Supervised Fine-Tuning (SFT) stage on a diverse data mixture to unlock generalist capabilities. For these small models, we found it beneficial to directly train on a representative set of downstream tasks, such as RAG or function calling. Our dataset is comprised of open-source, licensed, as well as targeted synthetic data, where we ensure high quality through a combination of quantitative sample scoring and qualitative heuristics.
We further apply a custom Direct Preference Optimization algorithm with length normalization on a combination of offline data and semi-online data. The semi-online dataset is generated by sampling multiple completions from our model, based on a seed SFT dataset. We then score all responses with LLM judges and create preference pairs by combining the highest and lowest scored completions among the SFT and on-policy samples. Both the offline and semi-online datasets are further filtered based on a score threshold. We create multiple candidate checkpoints by varying the hyperparameters and dataset mixtures. Finally, we combine a selection of our best checkpoints into a final model via different model merging techniques.
Build with LFM2
LFM2 models are available today on Hugging Face. We’re releasing them under an open license, which is based on Apache 2.0. Our license allows you to freely use LFM2 models for academic and research purposes. You can also use the models commercially if you’re a smaller company (under $10m revenue), above this threshold, you should contact us (sales@liquid.ai) to obtain a commercial license. You can get more details about our license here.
Since LFM2 models are designed for on-device efficiency, we recommend testing them privately and locally on your device via one of the many integrations such as llama.cpp, or even fine-tune them for your use cases with TRL.
If you are interested in custom solutions with edge deployment, please contact our sales team at sales@liquid.ai.