Our models are rapidly customizable, deliver the lowest latency on the market, and are optimized for even the most constrained hardware - creating end-to-end custom solutions that deliver powerful intelligence, everywhere you need it.
Trusted by







.png)


.png)
.png)

Every millisecond matters. Our small model footprint delivers the lowest time to first token on the market - for all your latency-critical use cases.
Stop letting hardware bottlenecks throttle your progress. Our ultra-efficient models deliver flagship-tier performance, allowing you to run high-complexity tasks on restricted compute footprints without compromise.
Our models are deployable in any environment - GPU, NPU, or CPU. Making powerful intelligence accessible everywhere you need it.
Never worry about cloud outages with AI deployed directly on your devices or on-prem servers. For all of your mission-critical needs.
Our models run entirely locally, in the cloud or hybrid so you’re in control of how and where your data is stored and used.
LFMs span modalities across text, vision, and audio for intelligence in whichever form suits your needs.
Our models are rapidly customizable for peak performance and efficiency in a footprint small enough to be deployed on everything from wearables and phones to cars, laptops, and the cloud.
Liquid’s Small Language Models deliver outsized performance for their small size across 7 languages and vision, text and audio capabilities.

LFMs are designed to be customized for your unique use case, hardware and data. So you get fast, private, secure AI - and only pay for the compute you need.
Our developer platform LEAP empowers your teams to specialize and deploy custom LFMs in one simple workflow – allowing them to ship faster and easier.

Our models are memory-optimized and tuned for real-time deployment on constrained hardware.

We generate synthetic, labeled, or multimodal data at scale, ensuring high-quality data optimized for your use case.
We rapidly develop and rigorously validate custom models, guaranteeing performance aligned with your requirements.
We precisely optimize models for your specific hardware environment, including CPUs, GPUs, automotive-grade chips, mobile devices, and edge deployments.
We work transparently, enabling your teams to extend or adapt your models into your workflows and hardware.
We have successfully delivered specialized LFM solutions to leading global enterprises, demonstrating clear improvements at all levels.
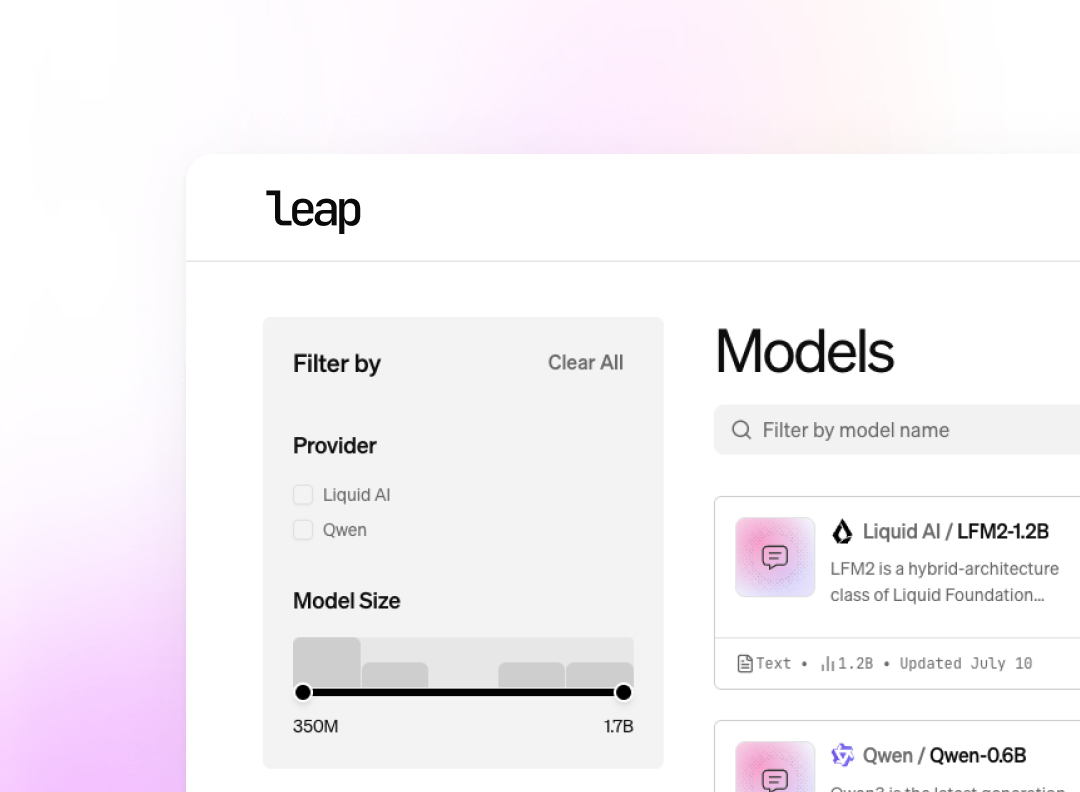
LEAP is our developer-first platform for customizing and deploying powerful multimodal LFMs on any device in one simple workflow. So your teams can deploy faster and easier. Built for speed, control, and end-to-end security.
.svg)









