開発者やコミュニティが #Liquid AI #LFM#LEAP#Liquid Apollo についてどのように語っているのかをご覧ください
GPT 4 level AI with 3B parameters is insane! Absolutely going to give it a try.
Dec 26, 2025
soikat
@LocallyAIApp @MistralAI The new LFM2-2.6B-EXP is incredible for local models and runs perfectly. Would it ever arrive on LOCALLYAI?
Dec 27, 2025
DefaultUserName
🚀 LiquidAI just released LFM2‑2.6B‑Exp, a 3 B‑parameter text‑gen model that scored 683 on the latest benchmark — updated just 3 hrs ago. It brings near‑GPT‑4 quality with a tiny footprint. https://huggingface.co/LiquidAI/LFM2-2.6B-Exp
Dec 26, 2025
the_ai_scope
lfm2-2.6b looks like it might be promising for driving NPCs, if i keep the population count reasonably low. tiny and impressively coherent. getting 107tps writing on an old civilian-grade GPU, and 15x that reading. haven't tested long context yet tho
Jan 6, 2026
barredspirals.bsky.social
KaniTTS2, our text-to-speech model with frame-level position encodings, optimized for real-time conversational AI. ...Full Pretraining Code — train your own TTS model from scratch [https://github.com/nineninesix-ai/kani-tts-2-pretrain](https://github.com/nineninesix-ai/kani-tts-2-pretrain. Highlights: 400M parameter model built on LiquidAI's LFM2 backbone + Nvidia NanoCodec; ~0.2 RTF on an RTX 5080, 3GB VRAM — fast enough for real-time use; Voice cloning with speaker embeddings; Pretrained on \~10k hours of speech data (8x H100s, just 6 hours of training!). Why we're releasing the pretrain code: We want anyone to be able t..
Feb 14, 2026
KokaOP
Liquid AI Open-Sources LFM2: A New Generation of Edge LLMs. Liquid AI just dropped a game-changer for edge computing with LFM2, their second-generation foundation models that run directly on your device. These aren't just incremental improvements—we're talking 2x faster inference
Jul 14, 2025
Marktechpost
@maximelabonne Liquid LFM2.5 is incredible, the fact you are able to do so much with 1.2B is absurd!
Jan 13, 2026
710Tek
🔒 Game changer: AMD Ryzen AI runs Liquid AI's LFM2 model locally for meeting summaries. Zero internet needed, complete privacy, 16-second processing. Finally, AI PCs that don't send your data to the cloud. #AdwaitX #AMD #PrivacyFirst #AI #TechNews #CES2026 #AINews #AIComputing #EnterpriseAI
Jan 6, 2026
adwaitx.bsky.social
@liquidai Exciting news! LFM2-2.6B-Exp’s RL approach and improvement benchmarks sound impressive. Curious to see how it transforms small-model capabilities.
Dec 26, 2025
theagenticage
@MParakhin Wow, Mikhail, that's some impressive performance! Sub-20ms inference is quite something, and the architecture sounds game-changing, right?
Nov 15, 2025
codewithimanshu
LiquidAI is the real deal. This company will catch up quick. Their 40B LFM is cool as hell.
Oct 1, 2025
LoveMind_AI
@alshell7 @LiquidAI_ There are also the currently available LFM2-1.2B-Extract and LFM2-350M-Extract. Not tuned for PII but they will do the job very well. Been trying them in the last couple days for a few things and have to say, they are amazing models.
Oct 13, 2025
Matrix_Memories
One of the things im going to do this weekend is run BFCL on LFM2 and Arcee's new tiny MOE Trinity Nano; for me tool calling is .... the benchmark, lets say. That and context i guess. So i'll post about that at some point. But so far, anecdotally just playing with it LFM2 8B A1B is still impressive.
Dec 4, 2025
pretzelkins.bsky.social
📰 Small LLMs Reveal Surprising Tool-Calling Mastery on CPU — Benchmark Results. A groundbreaking benchmark tests 21 small language models on their ability to judge when to invoke tools, revealing that ultra-compact models like Qwen3:0.6B and LFM2.5:1.2B outperform larger ...#AINews #AI #Teknoloji
Feb 14, 2026
aihaberleri.bsky.social
Goodbye to 2025 👋Happy New Year 2026! Small LLMs highlights in 2025: Qwen3-4B; LFM2–8B-A1B / LFM2-2.6B-Exp; granite-4.0-h-tiny (7B A1B); gemma-3n-E4B / gemma-3-4b-it; SmolLM3-3B; Ministral-3-3B. They run at decent speeds on the CPU! Looking forward to 2026's smol LLMs!
Dec 31, 2025
axelgarciak.bsky.social
...and another one to the MIX 🔥 LFM2-8B-A1B takes MoE on-device: fast, private, and seriously efficient. Big-model brains, phone-level speed
AI that runs offline on your phone. LFM2.5-1.2B-Thinking uses under 1GB, CPU only, 10 to 15 tokens per second, about 1.5 second latency. Scores 72% GSM8K, 68% ARC. Apache 2.0 on Hugging Face Jan 20 2026. Faster and lighter than Phi-2 and Gemma 2B, but clouds still lead.
Jan 27, 2026
bluehatone
Liquid AI has open-sourced two compact vision-language models, LFM2-VL-450M (350 M LM + 86 M vision) and LFM2-VL-1.6B (1.2 B LM + 400 M vision). Both deliver near-real-time inference that’s about 2× faster on GPUs than many existing VLMs while preserving competitive accuracy.
Sep 3, 2025
WesRothMoney
What's better than an AI LLM chatbot? 10 agents with different specialties and personas responding to you realtime like the boss! (note: video not sped up + autocomplete in bg). Impressed with @liquidai LFM2.5 1.2B model (@UnslothAI version) running all locally with @lmstudio
Jan 16, 2026
BlurSpline
@AntDX316 The response quality of LiquidAI/LFM2.5-1.2B-Thinking and LFM2.5-1.2B-Instruct is very high, which is quite remarkable for such small models.
Jan 25, 2026
support_huihui
Emerging AI tools like Liquid AI’s compact reasoning model running on smartphones show how decentralized, real-time intelligence is becoming more accessible for market insights on the go. https://huggingface.co/LiquidAI/LFM2.5-1.2B-Thinking
Jan 21, 2026
wlfc_
@paulabartabajo_ @liquidai Running models locally can be a game changer for privacy and cost. It's amazing how far we've come with efficient inference. What are the implications for offline apps now?
Jan 29, 2026
bygregorr
Small AI designed to follow instructions, run locally and is totally open weights. LFM2-2.6B-Exp technical breakdown: F32 tensor; 2.6B params; For edge devices; Agent & RAG focused; Math skills (AIME25); Good general knowledge (GPQA); Strong prompt adherence (IFBench)
Dec 25, 2025
vectro
The rise of Liquid AI is worth watching 👀. Built for efficiency, scalability & speed — it’s redefining how AI systems learn and adapt. Feels like we’re just scratching the surface of what this tech can unlock. 🚀 #AI #LiquidAI #DeepTech
Sep 26, 2025
Archit_AK47
Wow. Working with small models 1-3B params makes me feel like working with live wires. Tiny changes, big implications. Low key love it. @liquidai Hats off to you folks -- I'm building something on-device and LFM2.5-1.2b punches way above its weight 👊🏾
Feb 2, 2026
DoDataThings
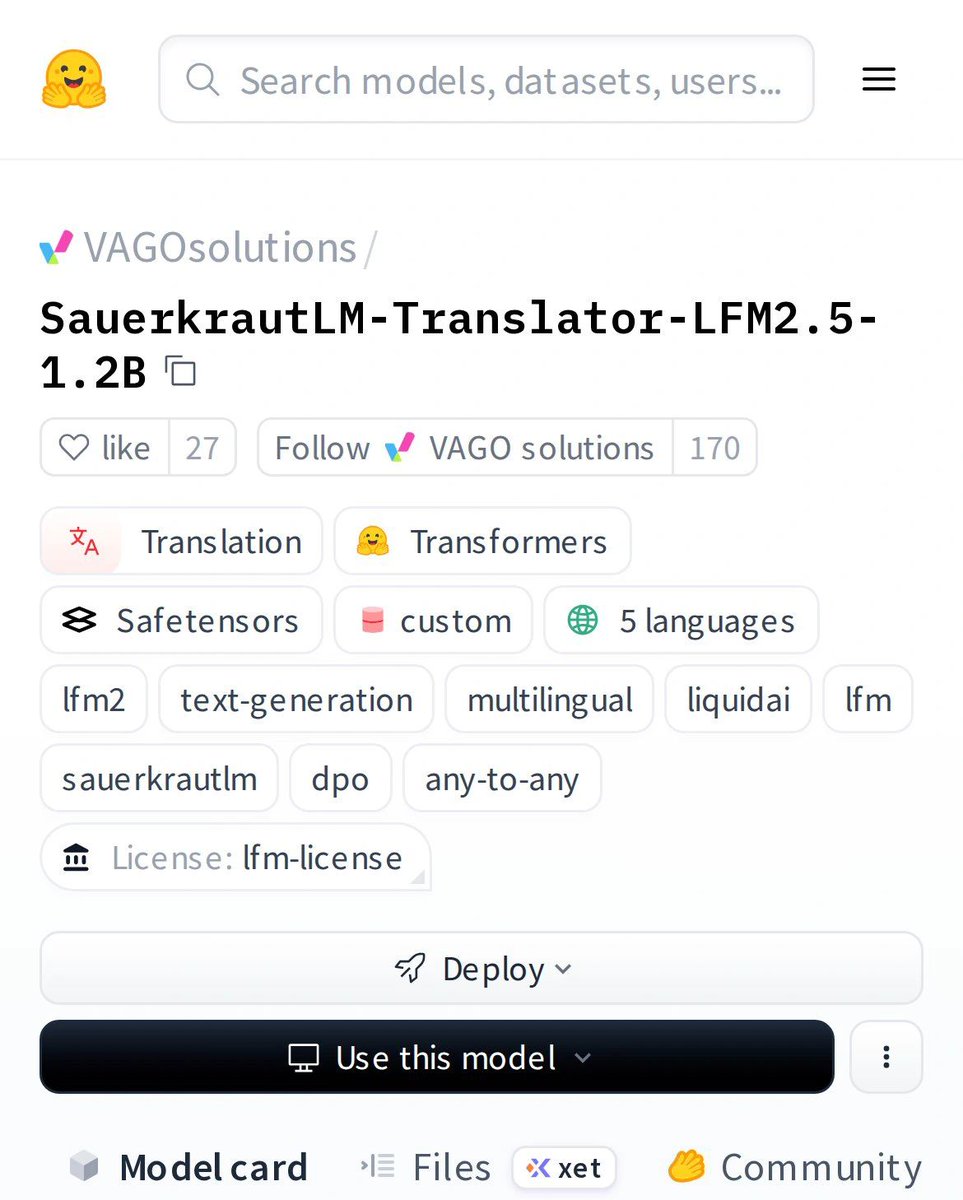
🔥 A 1.2B translation model that punches way above its weight. SauerkrautLM-Translator-LFM2.5-1.2B just dropped. This isn't another general-purpose LLM. It's a specialized translator built for one thing — high-quality, nuanced text conversion. What makes..
Aug 12, 2025
gm8xx8
🔥 A 1.2B translation model that punches way above its weight. SauerkrautLM-Translator-LFM2.5-1.2B just dropped. This isn't another general-purpose LLM. It's a specialized translator built for one thing — high-quality, nuanced text conversion. What makes
Feb 9, 2026
psk90_ai
@maximelabonne Interesting checkpoint. LFM2-2.6B-Exp seems to leverage pure RL effectively for instruction following and reasoning, outperforming most 3B class models in specialized tasks.
Dec 26, 2025
omer_oved
Exciting news from Liquid AI! 🚀 Introducing LFM2-VL: super-fast, open-weight vision-language models perfect for low-latency, on-device deployment. Revolutionizing AI for smartphones, laptops, wearables, and more! #AI #VisionLanguageModels
.svg)
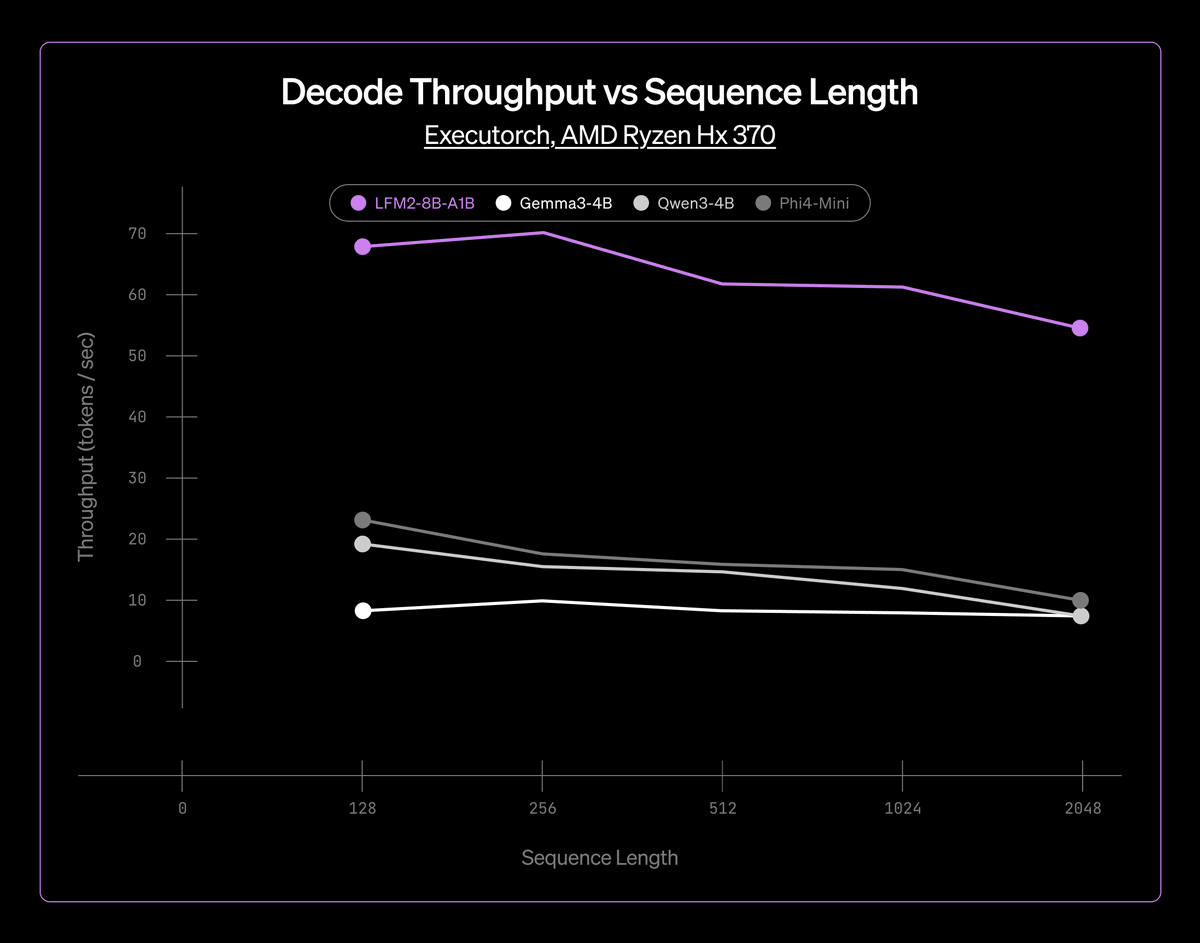



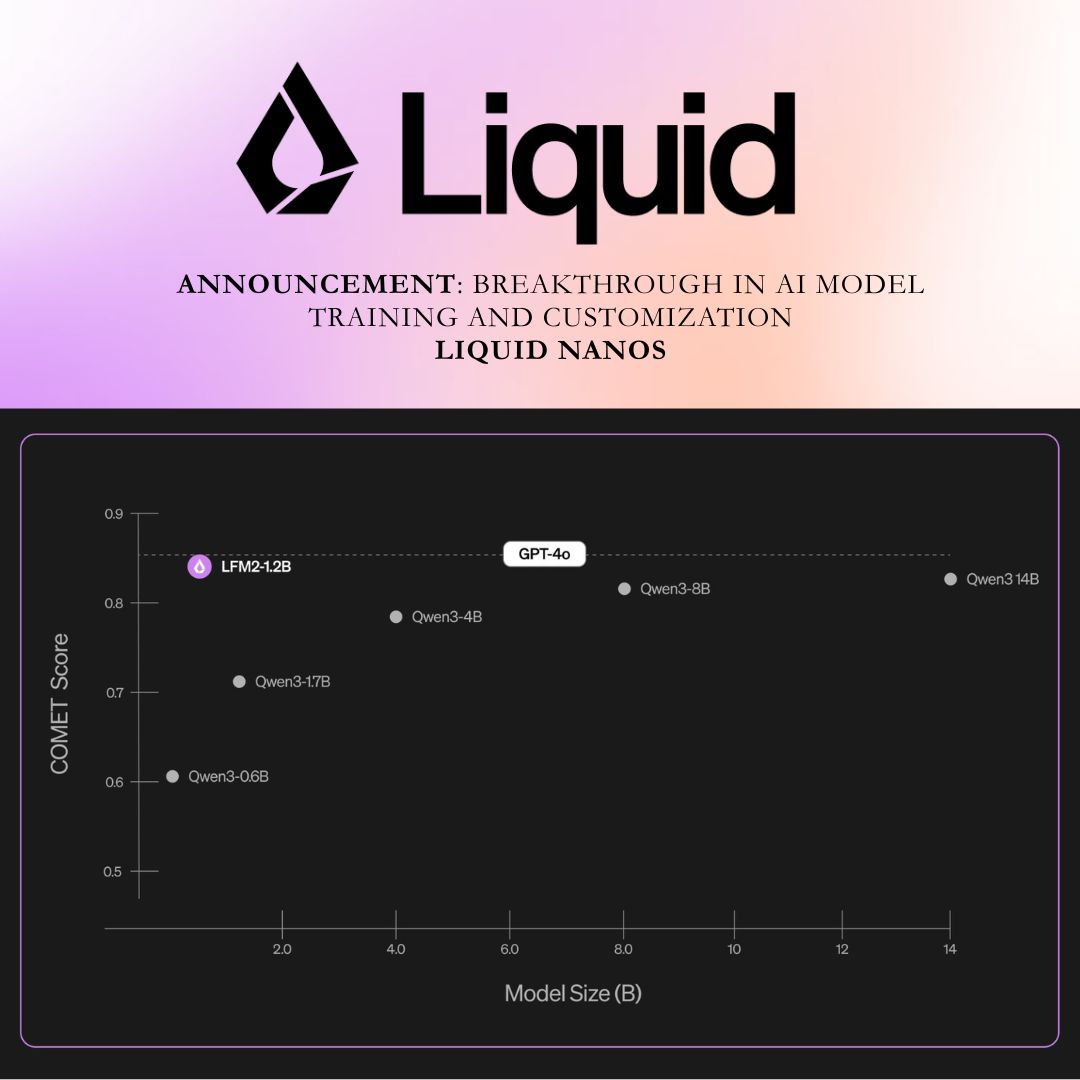
GPT 4 level AI with 3B parameters is insane! Absolutely going to give it a try.