開発者やコミュニティが #Liquid AI #LFM#LEAP#Liquid Apollo についてどのように語っているのかをご覧ください
Liquid AI’s LFM2.5 packs multimodal, agentic AI into sub-2B models that run entirely on-device—text, vision, and real-time speech, no cloud needed. But small models still can’t match frontier-scale reasoning; they excel at speed, privacy, and efficiency, not complexity. Already
Jan 6, 2026
TheAiDecode
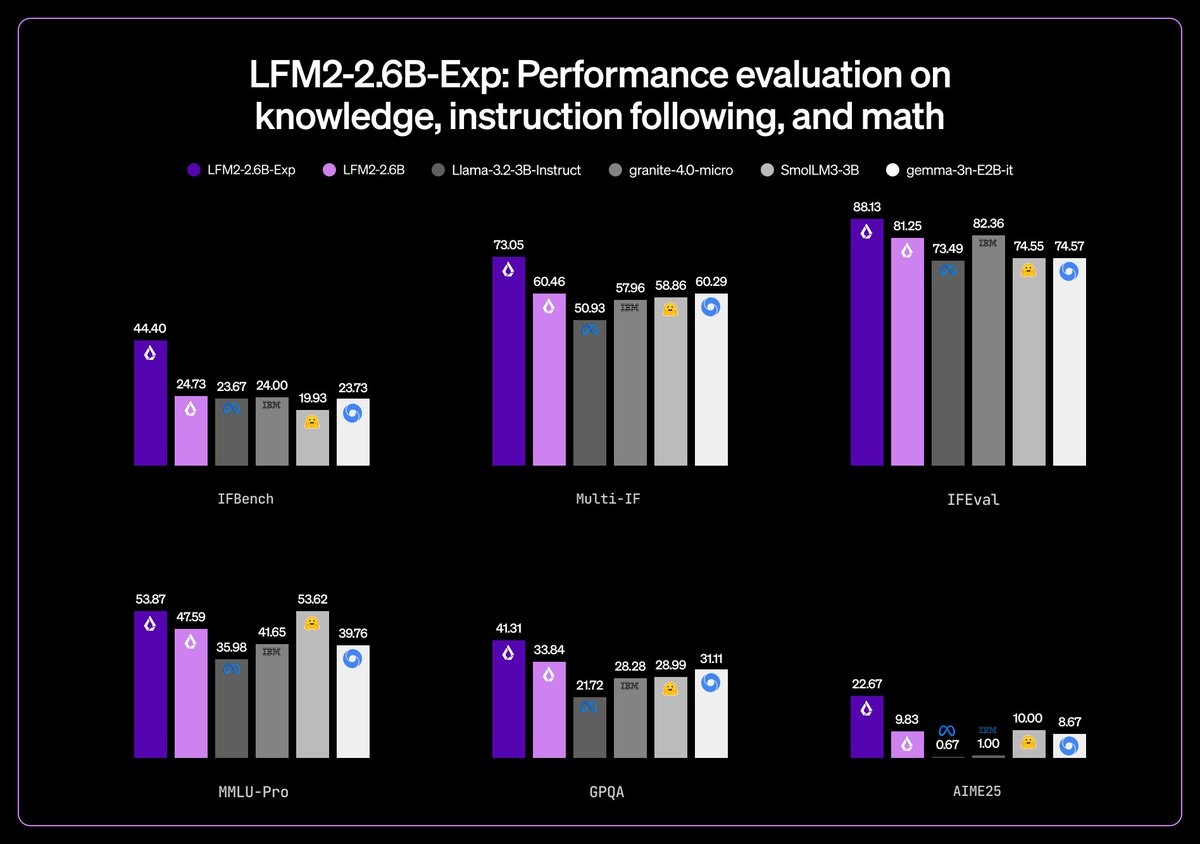
LFM2-2.6B-Exp shows pure RL beating giants: a 3B model tops a 263x larger peer on IFBench, with think tokens and on device tool use for edge reasoning. Is edge AI finally reality? #EdgeAI
Dec 28, 2025
Emp0_com
1. Exciting AI breakthroughs are here! New compact models like LFM2.5 bring powerful on-device intelligence with billions of parameters and smarter multimodal abilities. Tencent’s Youtu-LLM outperforms bigger models in coding & math tasks. 🤖✨
Jan 6, 2026
singleapi2
Small models are getting scary good. Liquid AI shows how reinforcement learning can turn a 2.6B model into something that beats most 3B LLMs — perfect for edge, local and real-world deployments. #AI #LLM #EdgeAI #MachineLearning #ReinforcementLearning
Dec 26, 2025
MartinSzerment
This is pretty interesting, especially the focus on "real on-device agents". Curious if anyone has benchmarked tool-use style workflows (planner/executor, function calling, etc) on LFM2.5 yet, and how it compares to small Llama variants when latency really matters. If youre exploring agentic patterns, Ive been collecting some practical notes and examples here too: https://www.agentixlabs.com/blog/
Jan 6, 2026
macromind
Another great model from Liquid AILFM2.5-1.2B-Thinking. What needed a data center 2 years ago now runs fully on-device—on any phone with \~900MB RAM. Concise reasoning. Thinks before answering. Edge-scale latency. Tools, math, instructions—nailed
Jan 20, 2026
PrabhurajKanche
Benchmarking On-Device MLX LLMs with Russet on iPhone 17 Pro and iPad Pro M5. TL;DR: I ran 6 quantized LLMs on Russet which uses Apple's MLX framework on an iPhone 17 Pro and iPad Pro M5, both with 12GB RAM. LFM2.5 1.2B at 4-bit hits 124 tokens/sec on iPad and 70 tokens/sec on iPhone. iPad Pro is 1.2x–2.2x faster depending on model and prompt length, with the gap widening dramatically for longer contexts. More detailed methodology, results (plots included), and discussion in the link.
Feb 8, 2026
Russet-Mod
@liquidai cool release. what's the secret sauce for sub-1b latency on-device agents? custom kv cache compression or fused ops? broader modalities – audio+vision in 1b? digging the agentic focus.
Jan 7, 2026
SynthesisLedger
@Henry_Ndubuaku @liquidai 231MB peak for a 1.6B INT8 VLM across context sizes is wild. Curious what dominated after quantization, KV cache, tokenizer, or runtime overhead? Also love the “budget devices first” stance.
Dec 31, 2025
EllaMeng96268
Liquid AI has unveiled the LFM2-8B-A1B, a groundbreaking Mixture-of-Experts (MoE) model designed for on-device execution. With an impressive
Oct 11, 2025
AiTalkIn
5️⃣ Jan Nano An underrated agent model. Executes, plans, automates. Feels like a real assistant. 6️⃣ LFM2 VL 1.6BCompact multimodal engine. Fast inference. Handy for on device vision tasks. 7️⃣ Magistral Small 1.2 Solid visual plus language mix. Consistent and easy to use.
Oct 17, 2025
jokerbobx
Liquid AI launched LFM2-VL-3B, a compact multilingual vision model supporting ten languages, excelling in single- and multi-image understanding and English OCR, scoring 51.8% on MM-IFEval and 71.4% on RealWorldQA with notably low hallucination rates.
Oct 22, 2025
buzagloidan
@0x_Sero I’m using gpt 20b oss, qwen3 coder 30b, phi-4, and im now playing with new releases from lfm2. RAG-MATH-TOOL versions in my home lab. Initial benchmarks are good. Can’t use models bigger than 30b params though.
Sep 27, 2025
lis10inc440
Just benchmarked 16 LLMs on a Raspberry Pi 5 (8GB) with Ollama. Tested the most recent models from Google, Meta, DeepSeek, Microsoft, Mistral, IBM, Alibaba, HuggingFace, and Liquid AI.@LiquidAI_HQ's lfm2.5-thinking led at 11.7 tok/s from just 731MB. Super tricky minimizing
Feb 17, 2026
OthelloOcho
Liquid AI announced LFM2-VL, fast and lightweight vision models (450M & 1.6B). 2 models based on the hybrid LFM2 architecture: LFM2-VL-450M and LFM2-VL-1.6B. Available quant: 8bit MLX, GGUF Q8 & Q4 (llama.cpp release b6183)
Aug 17, 2025
benja0x40
LiquidAI bet on small but mighty model LFM2-1.2B-Tool/RAG/Extract. So LiquidAI just announced their fine-tuned LFM models with different variants - Tool, RAG, and Extract. Each one's built for specific tasks instead of trying to do everything. This lines up perfectly with that Nvidia whitepaper about how small specialized models are the future of agentic AI. Looks like it's actually happening now. I'm planning to swap out parts of my current agentic workflow to test these out. Right now I'm running Qwen3-4B for background tasks and Qwen3-235B for answer generation. Gonna try replacing the background task layer with these LFM models since my main use cases are extraction and RAG. Will report back with results once I've tested them out.
Oct 1, 2025
dheetoo
Smallest Model (600mb) I've tried that knows the legend of the The Lost R -- Book 1 of the Strawberry Saga and 3 Rs trilogySO FAST https://lmstudio.ai/models/liquid/lfm2-1.2b
Jul 21, 2025
jasonkneen
Edge AI just levelled up 🚀 LFM2 is here—2x faster inference, 3x faster training, and open-source. No more cloud dependency for powerful AI. What’s the first edge device you’d supercharge with this? #EdgeAI #OpenSource #MachineLearning
.svg)


Liquid AI’s LFM2.5 packs multimodal, agentic AI into sub-2B models that run entirely on-device—text, vision, and real-time speech, no cloud needed. But small models still can’t match frontier-scale reasoning; they excel at speed, privacy, and efficiency, not complexity. Already