開発者やコミュニティが #Liquid AI #LFM#LEAP#Liquid Apollo についてどのように語っているのかをご覧ください
What if BabyAGI didn’t need the cloud? We took @yoheinakajima's BabyAGI loop and ran it locally on an iPhone over a small language model (LFM2-350M). No OpenAI key. No servers. Just @RunAnywhereAI SDK + @liquidai LFM2-350M running everything fully on-device.
Nov 28, 2025
ShubhamMal72313
@localghost Big congrats, on device and Liquid AI feels like a game changer combo.
Jul 22, 2025
tikooww
@paulabartabajo_ @liquidai Its matches or outperforms much larger models (e.g., Qwen3-1.7B) on many reasoning benchmarks, even with fewer parameters if it used for specific tasks
Jan 30, 2026
iamGopalJosh
@liquidai Bottom line:LFM2 models show that you can get 3B–4B-level quality from ~1B–2.6B models and run them 2–3× faster on a phone. Small models, if designed correctly, can dominate the accuracy–latency tradeoff.
Dec 4, 2025
iMATTHEWRYAN
3. But here's the sleeper hit everyone's missing: LiquidAI's 1B model. Small enough to run locally. Capable enough to actually be useful. This is the sweet spot for developers who want AI without cloud dependency.
Feb 5, 2026
theatlasvision
Local LLM models are getting good. LFM2-2.6B-Exp is quite powerful and fast on Apple Silicon.
Dec 25, 2025
fragermk
For ~3B model size, its instruction-following and reasoning results are genuinely impressive.
📰 LFM2 2.6B-Exp on Android: 40+ TPS and 32K context. The article discusses the impressive performance of LiquidAI's new LFM2 2.6B-Exp model, which can achieve GPT-4 level performance across a wide range of benchm… Read more 👇https://ai-curator.jp/articles/cmjw8efiq00v2ct1epceqo9q1 #AI #AINews
Jan 1, 2026
kento_morota
@maximelabonne The real breakthrough here isn't just the 2.6B size; it's the proof that Liquid Foundation Models (LFMs) respond to pure RL just as well as (or better than) traditional Transformers. For a long time, the 'Reasoning' meta was locked into the Attention mechanism. Seeing...
Dec 26, 2025
RituWithAI
@paulabartabajo_ @liquidai This is impressive. A 1.2B model achieving 239 tok/s on an AMD CPU and 82 tok/s on a mobile NPU while using under 1GB RAM makes truly private, offline, production-grade inference on everyday devices realistic now.
Jan 13, 2026
ContextrixAi
LFM2.5-1.2B-Instruct from LiquidAI works well with opencode and it's blazing fast
Jan 7, 2026
pebaryan
Hermes 4 14B: Completely uncensored and answers all the questions that other LLMs reject. Jan-Nano: Excellent agentic model for using tools and automating many tasks LFM2-VL 1.6B: Light weight and extremely fast multimodal model with vision
Oct 11, 2025
red_bear888
@maximelabonne @huggingface Congrats! I pre-trained a model using the LFM2 architecture a couple days ago, it's very efficient for training. Forgive me if I'm mistaken, why haven't you guys put out any research directly comparing the LTC architecture with hybrid-attention or regular transformers in LLMs?
Jan 18, 2026
Mostlime12195
Liquid AI just dropped something that kills the entire whisper->gpt->elevenlabs pipeline. sub-100ms end-to-end voice with unified audio i/o - no more stitching 3 apis together and dealing with streaming headaches. this changes everything for voice apps
Oct 1, 2025
BrandGrowthOS
@tmikov Right now, among models with <1B params, LFM models are 🔥
Feb 3, 2026
short_circuit32
I got frustrated dealing with massive responses from many MCPs and threw something together over the last couple days... it might help you too. Or not!...you're playing with multiple AI tools/coding assistants and hate having to reconfigure MCPs for each one- Very configurable options to override behavior globally or different tools via a single JSON file, plus a UI for management and visibility. I've been testing with a high-quant Qwen3-0.6b and LFM2-1.2b and it's doing very well for me. For example, I have it use web search and fetch for URLs and instead of having the larger model process the entire pages, the tiny model reads the page up to 10x faster, and just gives the large model the answers it needs, also keeping context lower.
Jan 2, 2026
steezy13312
#LiquidAI, an @MIT spinoff, just released a blueprint for enterprise-grade small models. Small can be mighty: high performance, low latency, on-device #AI. 51-page roadmap now public. 🚀#EnterpriseAI #OnDeviceAI @VentureBeat @carlfranzen @liquidai
Dec 2, 2025
alok_nayak
man, small models are getting so good. Testing this LFM2.5 model at 1.2b parameters, quantized on disk size less than a GB, and the initial responses I'm getting are definitely comparable to 8b or maybe even larger models from just last year […]
Jan 22, 2026
adr.mastodon.social.ap.brid.gy
@liquidai Impressive results for a 3B model pure RL is paying off.
Dec 26, 2025
10turtle_com
1. The core breakthrough: LFM2 models run 2x faster on regular CPUs compared to similar models while maintaining impressive capabilities. No more choosing between performance and accessibility.
Dec 20, 2025
arxivexplained
@liquidai is the best model I’ve worked with for post-training and fine-tuning, especially at 2–3B params. Most open-source models (Qwen, DeepSeek, etc.) feel over-tuned and hard to adapt.
Jan 12, 2026
SwishMoe
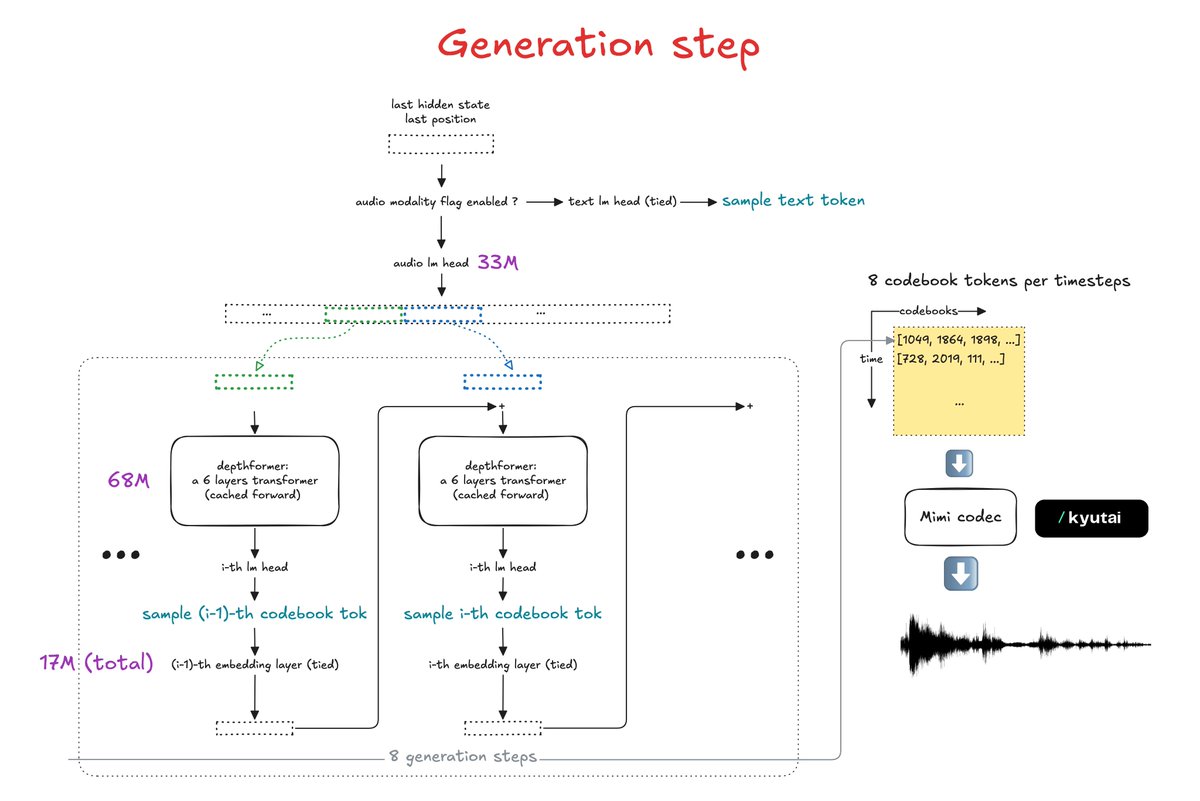
Cool release by @LiquidAI_: LFM2-Audio-1.5B It’s a pretty cool omni-architecture that enables prediction of both text and audio tokens, meaning it can handle multi-turn S2S, ASR, and TTS (with voice description) within a single model. Great to see, once again this year, a model
Oct 3, 2025
eustachelb
LFM2-1.2b is very very usable on my pathetic 8GB M2 MacBook Air. Love it.
Jul 13, 2025
rasmus1610
@LiquidAI_ LiquidAI/LFM2-8B-A1B model is really fast on iPhone. I must say I really like the vibe of this model for an on-device model. Any other LLMs I can check out?
Oct 18, 2025
heynerdceo
Very good little model released quietly. In testing it's quite competent and very fast. Quants available on HF.
Sep 24, 2025
Thrumpwart
Small but Mighty Liquid AI's LMF2-2.6B-Exp punching much above its weight
Dec 26, 2025
insignifictcman
@LiquidAI_ @Shopify Impressive collaboration — sub-20ms inference and measurable conversion gains show how foundational models can deliver real, production-grade impact in commerce. #AI #TechAI
Nov 13, 2025
Tech_AI_Tech
🚨 @liquidai just dropped LFM<2.5-1.2B-Instruct 🎆♠ and the architecture is actually insane 🚀 🔹 Hybrid design: Convolutions + Attention (not pure transformer) 🔹 1.2B params but rivals 3B+ models 🔹 239 tok/s on AMD CPU (runs under 1GB RAM) 🔹 Built for agentic workflows
Jan 8, 2026
fahdmirza
A 1.2B parameter model is now outperforming competitive models. And it runs on your phone. Liquid AI just shipped LFM2.5. The highlights: 2x better at graduate-level science questions than Llama 3.2 1B; 1.6x better at following complex instructions; Runs at 70 tokens/sec on
.svg)



What if BabyAGI didn’t need the cloud? We took @yoheinakajima's BabyAGI loop and ran it locally on an iPhone over a small language model (LFM2-350M). No OpenAI key. No servers. Just @RunAnywhereAI SDK + @liquidai LFM2-350M running everything fully on-device.