.svg)
本日、私たちの最大のLFM2モデルであるLFM2-24B-A2Bの初期チェックポイントを公開します。このスパースなMixture of Experts(MoE)モデルは、総パラメータ数240億、トークンあたり20億のアクティブパラメータを備えており、LFM2アーキテクチャがより大規模なサイズへ効果的にスケールすることを示しています。今回のリリースにより、LFM2ファミリーはLFM2-350MからLFM2-24B-A2Bまで、ほぼ2桁にわたる規模を網羅することになります。スケールを一段階引き上げるごとに、標準ベンチマークにおいて一貫した品質向上を達成してきました。LFM2-24B-A2Bは32GBのRAMに収まるよう設計されており、統合型グラフィックスプロセッサ(iGPU)および専用ニューラルプロセッシングユニット(NPU)を搭載した一般的なノートPCやデスクトップPC上で実行可能です。LFM2-24B-A2Bのオープンウェイトは現在Hugging Faceで利用可能です。ローカルでの実行やファインチューニング方法についてはdocsをご確認いただくか、Playgroundで簡単にお試しください。
LFM2 MoEのスケールアップ
LFM2は、効率的なゲート付きショート畳み込みブロックと少数のGrouped Query Attention(GQA)ブロックを組み合わせたハイブリッドアーキテクチャです。この設計は、ハードウェア・イン・ザ・ループによるアーキテクチャ探索を通じて開発され、低メモリコストで高速なプリフィルおよびデコードを実現します。LFM2-24B-A2Bは、このバックボーンをMixture of Experts構成で適用しています。総パラメータ数は240億ですが、フォワードパスごとにアクティブとなるのは23億のみであり、推論時には20億規模の密なモデルのコストを大きく上回る性能を発揮します。
.png)
私たちはLFM2-8B-A1Bと同様のレシピを採用しています。本モデルは、LFM2-8B-A1Bと同じ隠れ次元(2048)およびアテンション構成を維持しつつ、深さとエキスパート数という2つの軸でスケールしています。層数は24層から40層へ、各MoEブロックあたりのエキスパート数は32から64へ拡張し、top-4ルーティングを維持しています。アクティブパラメータを20億以内に抑えるため、各エキスパートはややスリム化されており(中間サイズは8Bの1792に対して1536)、最初の2層は学習の安定性のために引き続き密な構成としています。また、アテンションと畳み込みの比率はおよそ1:3(40層中10層がアテンション)を維持し、LFM2バックボーンの高速なプリフィルと低メモリ特性を保持しています。
このスケーリングのレシピは、より深くし、エキスパートを増やし、各エキスパートとアクティブ経路をスリムに保つことです。層を増やすことで、畳み込みブロックとGQAブロックの両方にわたり、より豊かな表現を構築できるようになります。一方で、エキスパート数を倍増させることで、より細粒度なルーティングと専門化のための余地が広がります。重要なのは、これらの変更がトークンあたりの計算経路を増大させない点です。アクティブパラメータ数は約1.5倍(15億 → 23億)に増加する一方で、総パラメータ数は3倍(83億 → 240億)に拡大しています。アクティブパラメータではなく総パラメータに容量を集中させることで、モデルはエッジ環境に適した特性を維持します。推論レイテンシとエネルギー消費は小さなアクティブ経路に比例するため、さまざまなノートPCやデスクトップPCでの展開が可能です。
ベンチマーク
私たちは、推論トレースを含まない従来型のインストラクトモデルとして LFM2-24B-A2B を提供するために、軽量なポストトレーニング手法を採用しました。この方針を選択した理由は、インストラクト版をポストトレーニングする方が迅速であり、また思考バリアントよりもインストラクトモデルの方が一般的に人気が高い傾向にあるためです。以下に、350M の密モデルから 24B の MoE まで、LFM2 ファミリー全体にわたるベンチマークの平均スコアを示します。
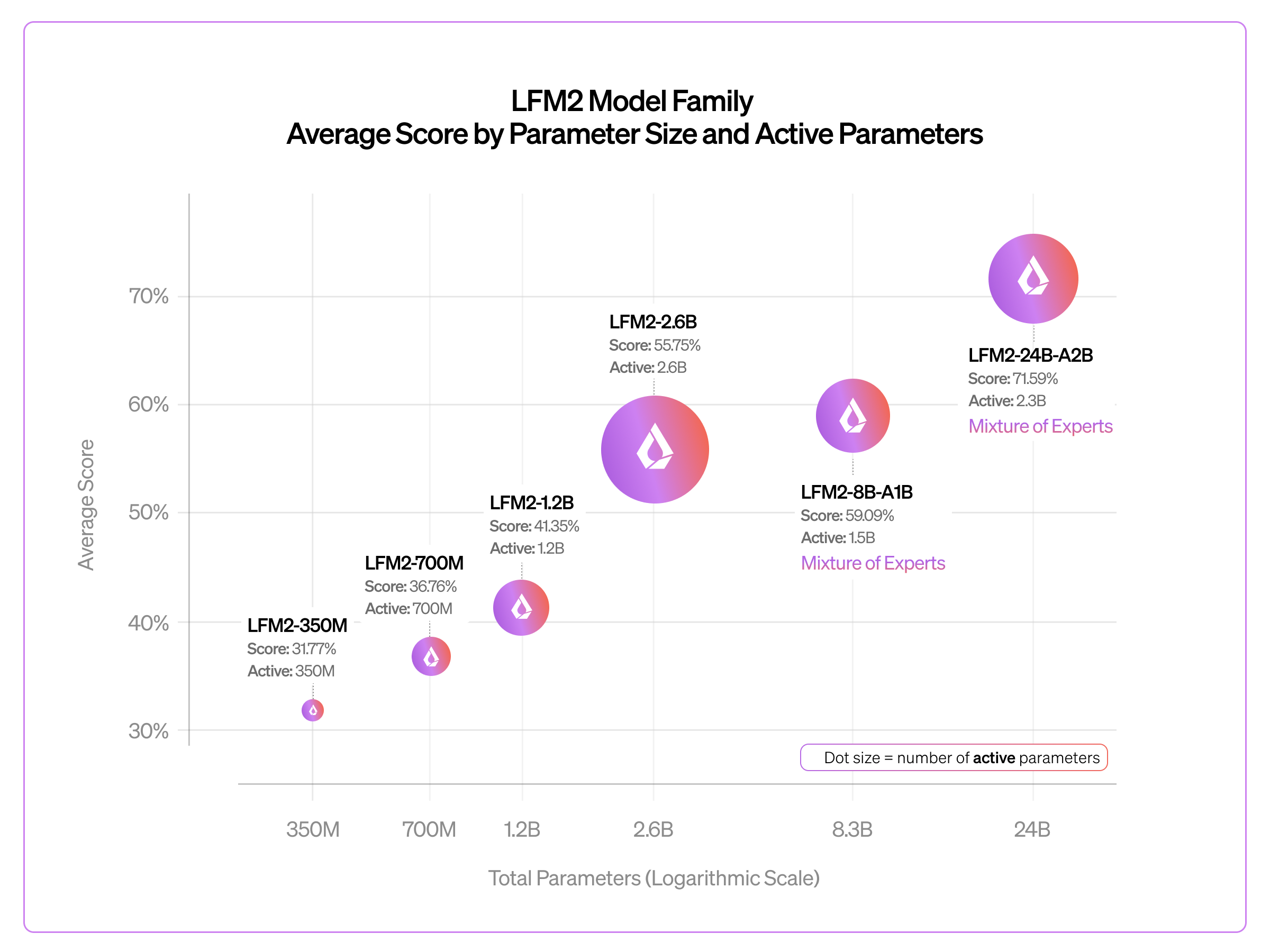
GPQA Diamond、MMLU-Pro、IFEval、IFBench、GSM8K、MATH-500 を含む各種ベンチマークにおいて、総パラメータ数を 350M から 24B へとスケールさせるにつれて、品質は対数線形的に向上します。この約100倍のパラメータ範囲は、LFM2 ハイブリッドアーキテクチャが予測可能なスケーリング挙動に従い、小規模モデルサイズで性能の頭打ちに達しないことを示しています。
高速・ユビキタス推論
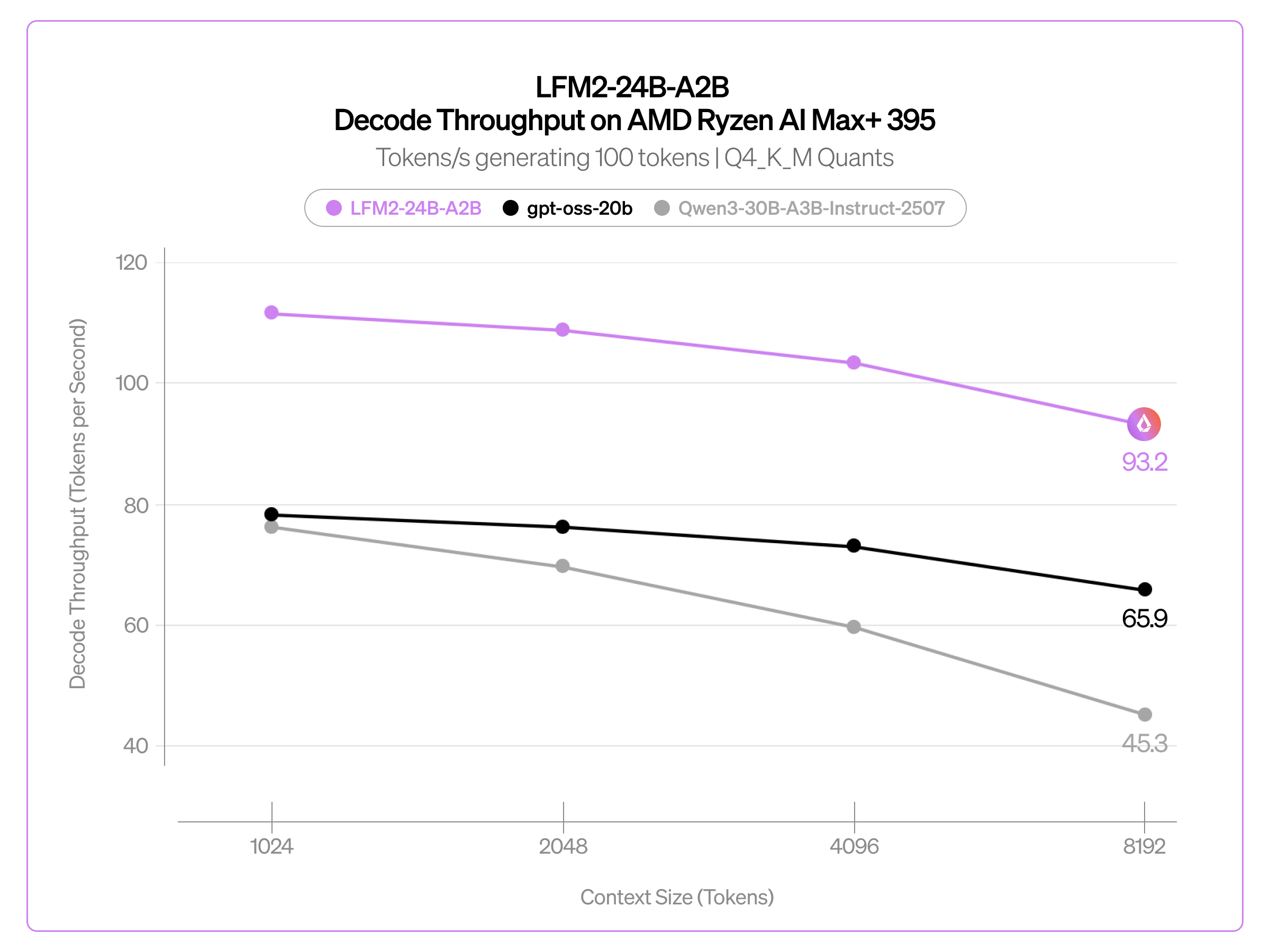
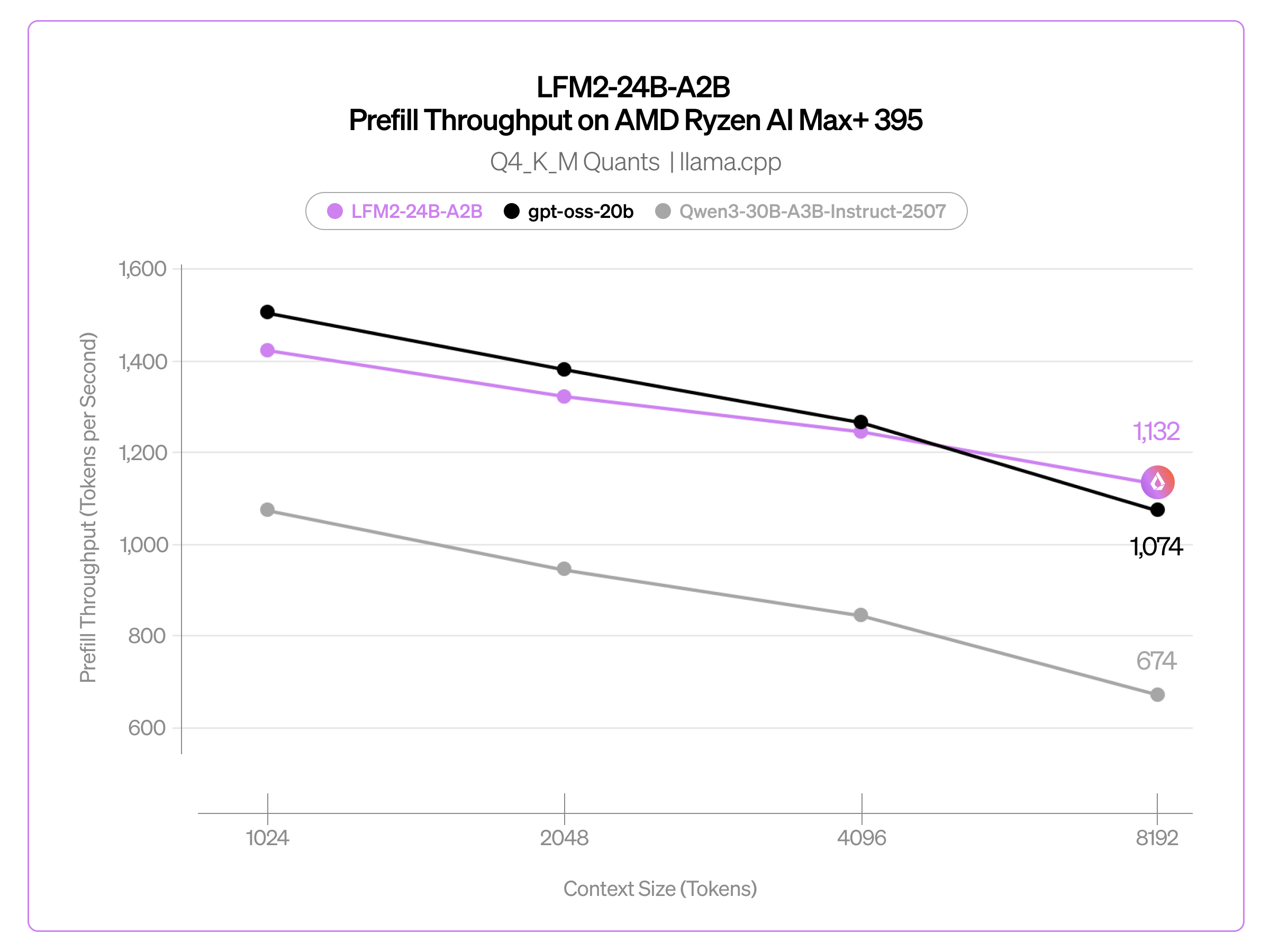
LFM2-24B-A2Bは、llama.cpp、vLLM、SGLangによる推論を初日からサポートしています。CPUまたはGPU上でそのまま実行でき、llama.cpp向けのGGUF形式では複数の量子化オプション(Q4_0、Q4_K_M、Q5_K_M、Q6_K、Q8_0、F16)が利用可能です。私たちはLFM2-24B-A2Bを、同規模の人気MoEモデルであるgpt-oss-20b(総パラメータ21B、アクティブパラメータ3.6B)およびQwen3-30B-A3B-Instruct-2507(総パラメータ30.5B、アクティブパラメータ3.3B)と比較しました。AMD Ryzen AI Max+ 395上でllama.cppを使用し、これらのモデルのQ4_K_Mバージョンにおけるprefillおよびdecodeスループットの両方を測定しました。
異なるコンテキストサイズ(トークン数)において、100トークンを生成する際のdecodeスループット(トークン/秒):
異なるコンテキストサイズ(トークン数)におけるprefillスループット(トークン/秒):
また、単一の H100 SXM5 GPU 上で vLLM を使用して達成したスループット(総トークン数/実行時間)についても報告します。高スループットなサービングは、コスト効率の高いデプロイメントおよび RLVR ワークロードにおけるロールアウト生成の両方において極めて重要です。私たちの測定は、本番規模のサービングおよび RL ワークロードを想定した、現実的なプリフィルとデコードを交互に行うセットアップで実施しています。
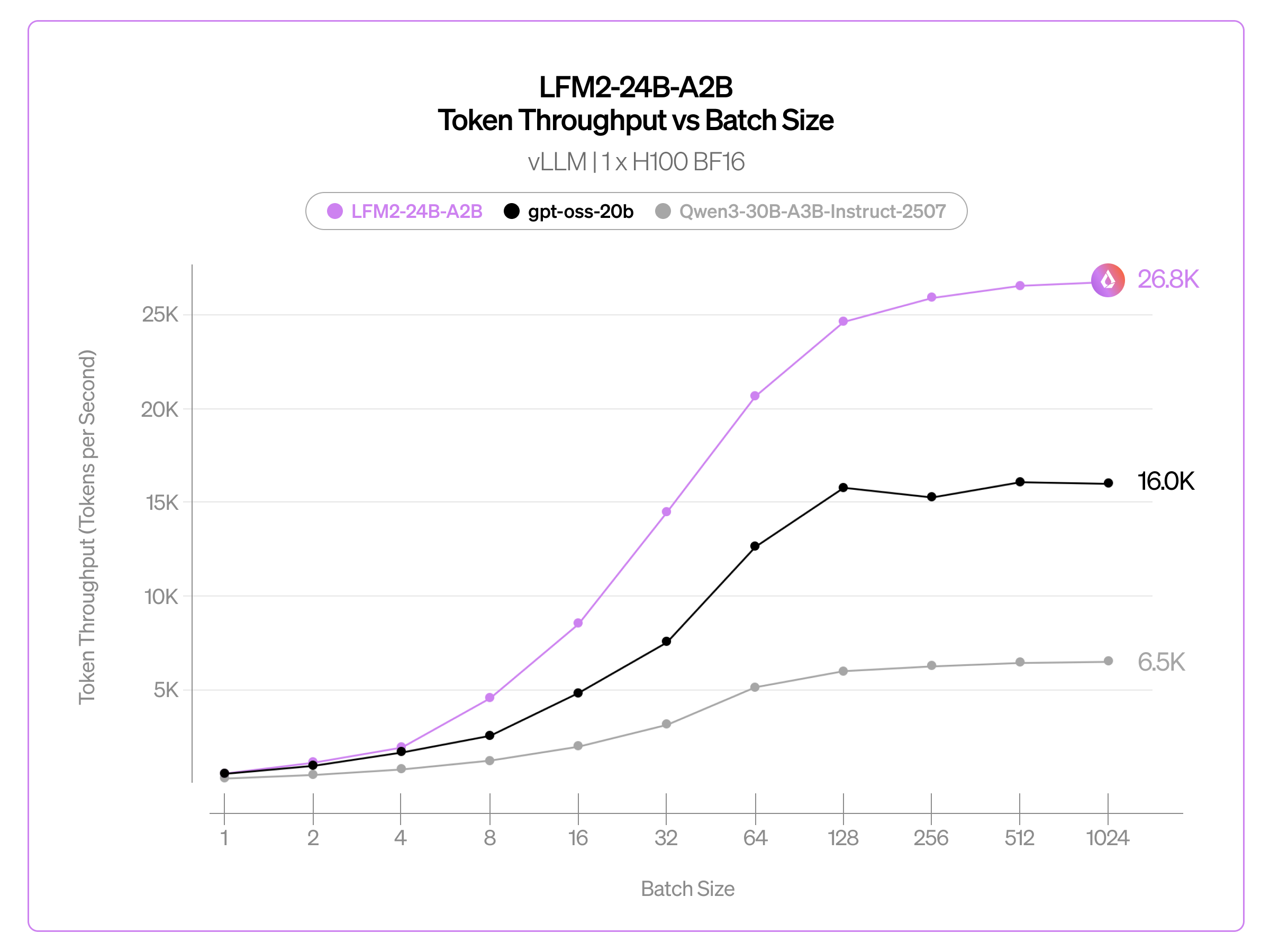
私たちは、LFM2-24B-A2B を gpt-oss-20b(mxfp4 で提供)および Qwen3-30B-A3B-Instruct-2507 と比較ベンチマークしました。単一の H100 SXM5 上で vLLM を使用した場合、LFM2-24B-A2B は 1,024 同時リクエスト(最大入力トークン 1,024/最大出力トークン 512)において約 26.8K トークン/秒を達成しました。これは、同程度の規模の MoE モデルを連続バッチ処理下で上回る性能であり、LFM2 アーキテクチャの優れたスループットスケーリング特性を示しています。
さらに、私たちはハードウェアパートナーと連携し、モバイルデバイスやエッジハードウェア向けに LFM2 モデルの NPU 対応を進めています。トークンあたり 2B のアクティブパラメータのみを使用する MoE 設計により、総パラメータ数が 24B であっても、本モデルはオンデバイス展開に適した有力な候補となっています。
今後の予定
LFM2-24B-A2B はこれまでに 17 兆トークンでトレーニングされており、事前学習は現在も進行中です。事前学習が完了すると、追加のポストトレーニングおよび強化学習を施した LFM2.5-24B-A2B の公開を予定しています。その間に、重みをダウンロードし、ノートパソコンやクラウド上で実行して、ぜひご意見をお聞かせください!
- 重みのダウンロード: Hugging Face
- エッジでのデプロイ: LEAP
- 今すぐ試す: Playground
LFM2 ファミリーが Hugging Face で 1,000 万ダウンロードを突破したことを嬉しくお知らせします!
-%20blog.png)
引用
本記事を引用する場合は、以下の形式をご使用ください。
Liquid AI, "LFM2.5-24B-A2B: Scaling Up the LFM2 Architecture", Liquid AI Blog, Feb 2026.または、以下の BibTeX 引用をご利用ください:
@article{liquidAI202624B,
author = {Liquid AI},
title = {LFM2.5-24B-A2B: Scaling Up the LFM2 Architecture},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/},
}