
LFM2-24B-A2B: Scaling Up the LFM2 Architecture
Today, we release an early checkpoint of LFM2-24B-A2B, our largest LFM2 model. This sparse Mixture of Experts (MoE) model has 24 billion total parameters with 2 billion active per token, showing that the LFM2 architecture scales effectively to larger sizes.
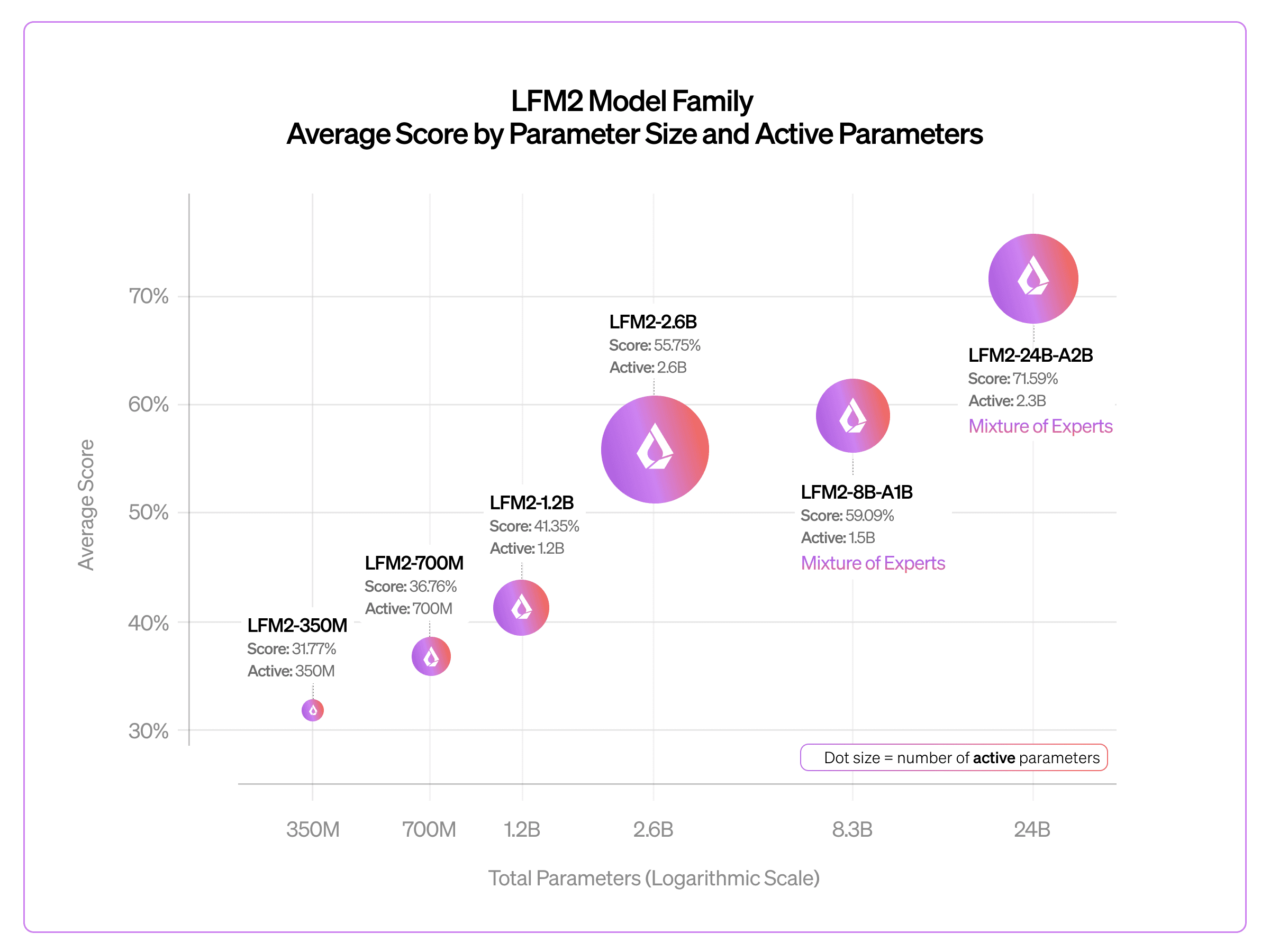
With this release, the LFM2 family spans nearly two orders of magnitude: from LFM2-350M to LFM2-24B-A2B. Each step up in scale has brought consistent quality gains on standard benchmarks. We designed LFM2-24B-A2B to fit in 32GB of RAM, making it deployable across cloud and edge environments, including consumer laptops and desktops with integrated GPUs (iGPU) and dedicated NPUs.
LFM2-24B-A2B is open-weight and available now on Hugging Face. Check out our docs on how to run or fine-tune it locally, or simply test it on our Playground.
Scaling Up LFM2 MoE
LFM2 is a hybrid architecture that pairs efficient gated short convolution blocks with a small number of grouped query attention (GQA) blocks. This design, developed through hardware-in-the-loop architecture search, gives LFM2 models fast prefill and decode at low memory cost. LFM2-24B-A2B applies this backbone in a Mixture of Experts configuration: with 24B total parameters but only 2.3B active per forward pass, it punches far above the cost of a 2B dense model at inference time.
We use a similar recipe to LFM2-8B-A1B. The model keeps the same hidden dimension (2048) and attention configuration as LFM2-8B-A1B, but scales along two axes: depth and expert count. It goes from 24 layers to 40, and from 32 experts to 64 experts per MoE block, while keeping top-4 routing. To stay within a 2B active parameter budget, each expert is slightly narrower (intermediate size 1536 vs. 1792 in the 8B). The first two layers remain dense for training stability, and the attention-to-convolution ratio holds at roughly 1:3 (10 attention layers out of 40), preserving the fast prefill and low memory characteristics of the LFM2 backbone.
The scaling recipe is: go deeper, add more experts, keep each expert and the active path lean. More layers let the model build richer representations across both convolution and GQA blocks, while doubling the expert count enables finer-grained routing and more room for specialization. Crucially, none of these changes inflate the per-token compute path; the active parameter count grows only ~1.5x (1.5B → 2.3B) against a 3x increase in total parameters (8.3B → 24B). By concentrating capacity in total parameters rather than active parameters, the model stays edge-friendly: inference latency and energy consumption track the small active path, making it deployable on a range of laptops and desktops.
Benchmarks
We took a lightweight post-training approach to ship LFM2-24B-A2B as a traditional instruct model without reasoning traces. We chose this route because it was faster to post-train an instruct version, and instruct models tend to be more popular than thinking variants.
Below we show average benchmark scores across the LFM2 family, from the 350M dense model up to the 24B MoE.
Across benchmarks including GPQA Diamond, MMLU-Pro, IFEval, IFBench, GSM8K, and MATH-500, quality improves log-linearly as we scale from 350M to 24B total parameters. This near-100x parameter range confirms that the LFM2 hybrid architecture follows predictable scaling behavior and does not hit a ceiling at small model sizes.
Fast Everywhere Inference
LFM2-24B-A2B has day-zero support for inference through llama.cpp, vLLM, and SGLang. You can run it on CPU or GPU out of the box, with multiple quantization options (Q4_0, Q4_K_M, Q5_K_M, Q6_K, Q8_0, F16) available in GGUF format for llama.cpp.
We compared LFM2-24B-A2B against two popular MoE models of similar size: Qwen3-30B-A3B-Instruct-2507 (30.5B total, 3.3B active parameters) and gpt-oss-20b (21B total, 3.6B active parameters). We measured both prefill and decode throughputs with Q4_K_M versions of these models using llama.cpp on AMD Ryzen AI Max+ 395.
Decode throughput (in tokens/s) when generating 100 tokens across different context sizes (in tokens):
Prefill throughput (in tokens/s) across different context sizes (in tokens):
We also report throughput (total tokens / wall time) achieved with vLLM on a single H100 SXM5 GPU. High-throughput serving is critical for both cost-efficient deployment and rollout generation during RLVR workloads. Our measurements use a realistic interleaved prefill-and-decode setup representative of production-scale serving and RL workloads.
We benchmarked LFM2-24B-A2B against gpt-oss-20b and Qwen3-30B-A3B-Instruct-2507. On a single H100 SXM5 with vLLM, LFM2-24B-A2B reached approximately 26.8K total tokens per second at 1,024 concurrent requests (1,024 max input tokens / 512 max output tokens), surpassing both comparably sized MoE models under continuous batching and demonstrating the favorable throughput scaling of the LFM2 architecture.
In addition, we are working with hardware partners to bring NPU support for LFM2 models on mobile devices and edge hardware. The MoE design with only 2B active parameters per token makes this model a strong candidate for on-device deployment, even at 24B total parameters.
What's Next
LFM2-24B-A2B has been trained on 17T tokens so far, and pre-training is still running. When pre-training completes, expect an LFM2.5-24B-A2B with additional post-training and reinforcement learning.
In the meantime, download the weights, run it on your laptop or in the cloud, and let us know what you think!
- Download weights: Hugging Face
- Build Today: LFM Docs
- Try it now: Playground
The LFM2 family has crossed over 10 million downloads on Hugging Face! Join the action and download our open weights today to start building.
Citation
Please cite this article as:
Liquid AI, "LFM2.5-24B-A2B: Scaling Up the LFM2 Architecture", Liquid AI Blog, Feb 2026.
@article{liquidAI202624B,
author = {Liquid AI},
title = {LFM2.5-24B-A2B: Scaling Up the LFM2 Architecture},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/},
}