.svg)
LFM2.5リトリーバー:高速な多言語検索のための双方向LFM
本日、新しい多言語検索モデル「LFM2.5-ColBERT-350M」と「LFM2.5-Embedding-350M」の2つをリリースします。どちらも350Mパラメータのモデルで、3月に公開したLFM2.5-350M-Baseを基盤とする、LFMファミリー初の双方向メンバーです。11言語にわたる高速で信頼性の高い多言語・クロスリンガル検索向けに構築されており、ほぼどこでも実行できるほど小さなフットプリントを備えています。
これらは特に、短いコンテキストの検索に適しています。製品カタログ、FAQナレッジベース、サポートドキュメント、そして言語をまたいで迅速・低コスト・高信頼に検索する必要があるその他のコレクションに適しています。
2つのモデルは、異なるニーズに対応します:
- LFM2.5-Embedding-350Mは、各ドキュメントを単一のベクトルに変換します。最速の検索と、最小で最も低コストのインデックスが必要な場合に選択してください。
- LFM2.5-ColBERT-350Mは、各ドキュメントにつき単一のベクトルではなく、各トークンをベクトルに変換します。これにより、クエリを単語ごとに照合でき、より高い精度と優れた汎化性能が得られますが、インデックスは大きくなります。ストレージよりも精度を重視する場合に選択してください。
アーキテクチャの更新
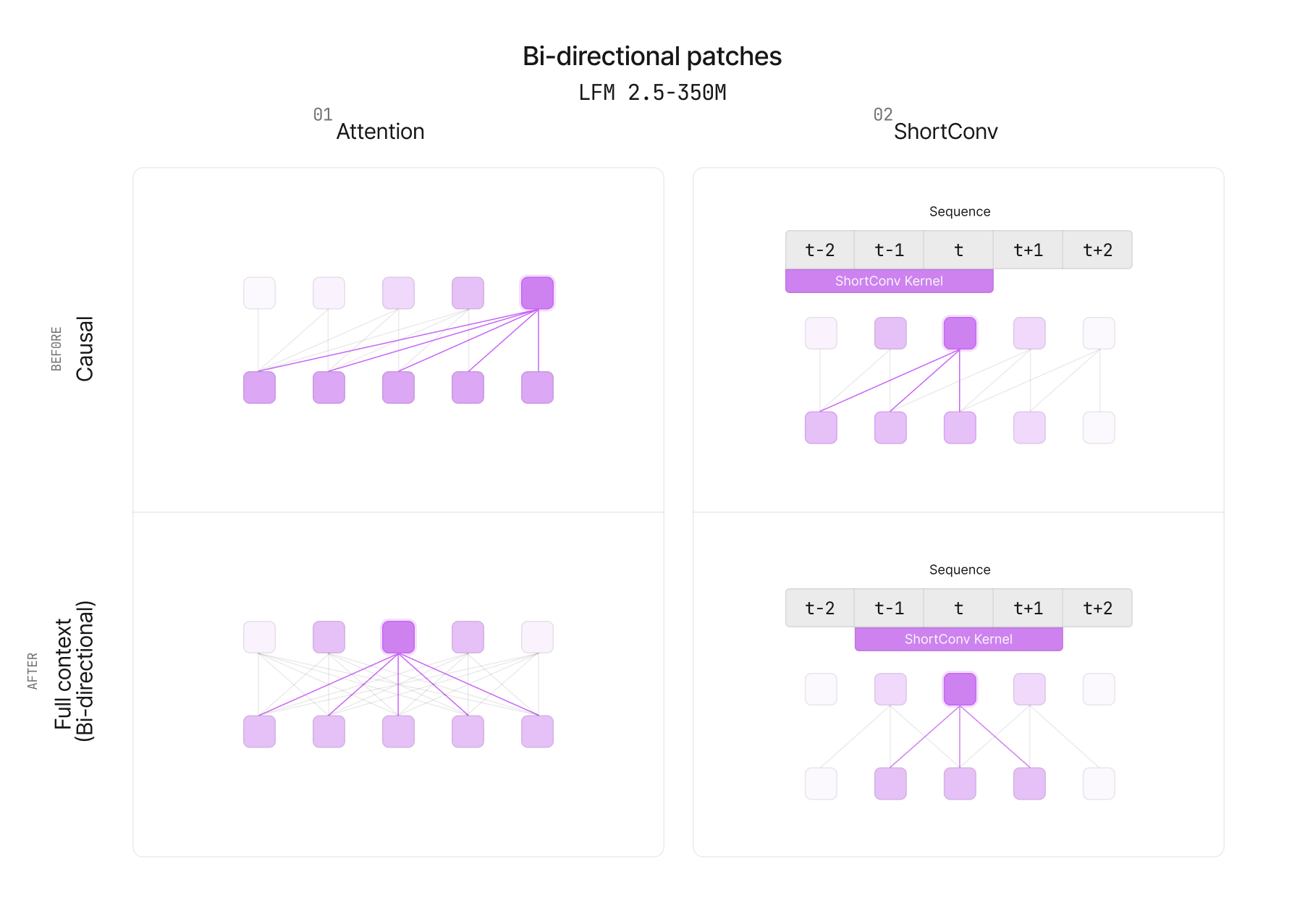
両モデルは、中間学習済みの汎用チェックポイントであるLFM2.5-350M-Baseをベースに構築されています。LFM2アーキテクチャに少数の双方向パッチを適用し、因果デコーダから双方向エンコーダへ適応させています。
因果型の設定では、各トークンは自身とその前にあるトークンの情報しか利用できません。これは左から右への生成には理想的ですが、検索にはあまり自然ではありません。私たちは因果注意マスクを双方向マスク(下図の左側)に置き換え、すべてのトークンが左右両方の文脈に注意を向けられるようにしています。また、LFM2の短い畳み込みを非因果型(下図の右側)にし、過去からの情報だけでなく、各トークンの周囲のローカル情報を対称的に混合できるようにしています。これにより、LFM2バックボーンの効率性を維持しつつ、検索タスクに必要なフルコンテキスト表現を生成します。
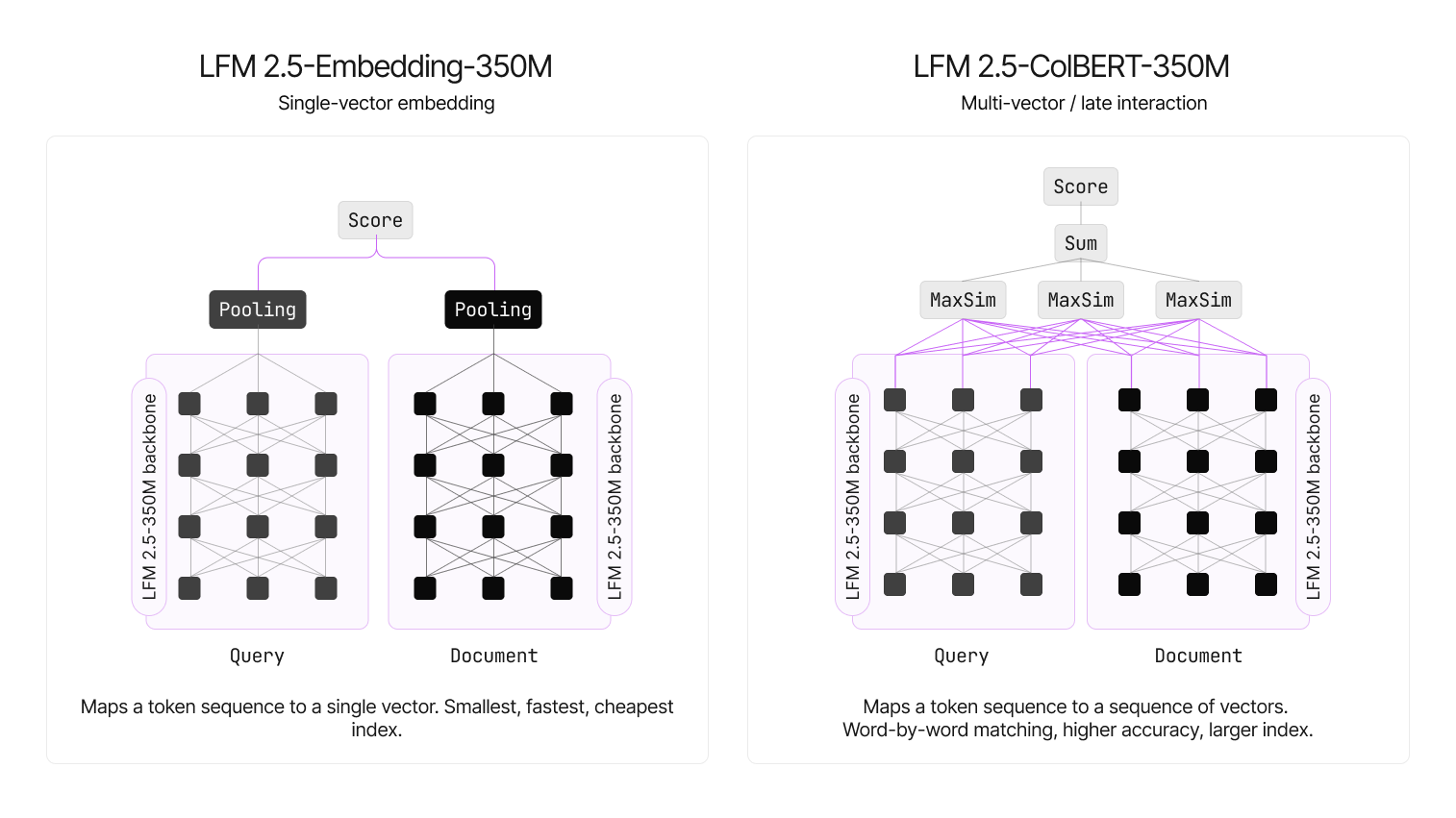
この共有双方向エンコーダから、2つのモデルはテキストの表現方法だけが異なります。LFM2.5-Embedding-350MはCLSスタイルのプーリングを使用して単一の密な埋め込みを生成する一方、LFM2.5-ColBERT-350MはMaxSimの後期相互作用のためにコンパクトなトークンごとの埋め込みを保持します。
LFM2.5-ColBERT-350Mと比較すると、今回のリリースでは、より新しいLFM2.5チェックポイントを使用し、対応言語を拡大し、明示的な多言語およびクロスリンガル検索トレーニングを追加しています。また、同じバックボーンとレシピに基づくコンパニオンのバイエンコーダも導入します。
トレーニングとデータ
両モデルは同じ3段階のトレーニングレシピに従っています:(1) 英語での大規模な対照事前学習、(2) 強力な教師モデルからの多言語およびクロスリンガル蒸留(対応する全11言語にわたって)、(3) ハードマイニングされたネガティブを用いた最終ファインチューニング。段階的な構成は、広範な対照事前学習を後続の専門化段階から分離しているLightOnのLateOnおよびDenseOnのリリースからも着想を得ています。
LFM2.5-Embedding-350Mは、LFM2.5-ColBERT-350Mよりもやや多くのクロスリンガルデータを受け取ります。これは、クロスリンガル検索が後期相互作用の設定ではより自然に現れ、追加の教師ありデータの恩恵が比較的小さいためです。
トレーニングデータは、キュレーションされた社内データとオープンソースの英語検索データセットを組み合わせたものです。第2および第3のトレーニングフェーズで使用する多言語およびクロスリンガルのペアを拡張するため、クエリとドキュメントのLLMベースの翻訳を活用しています。
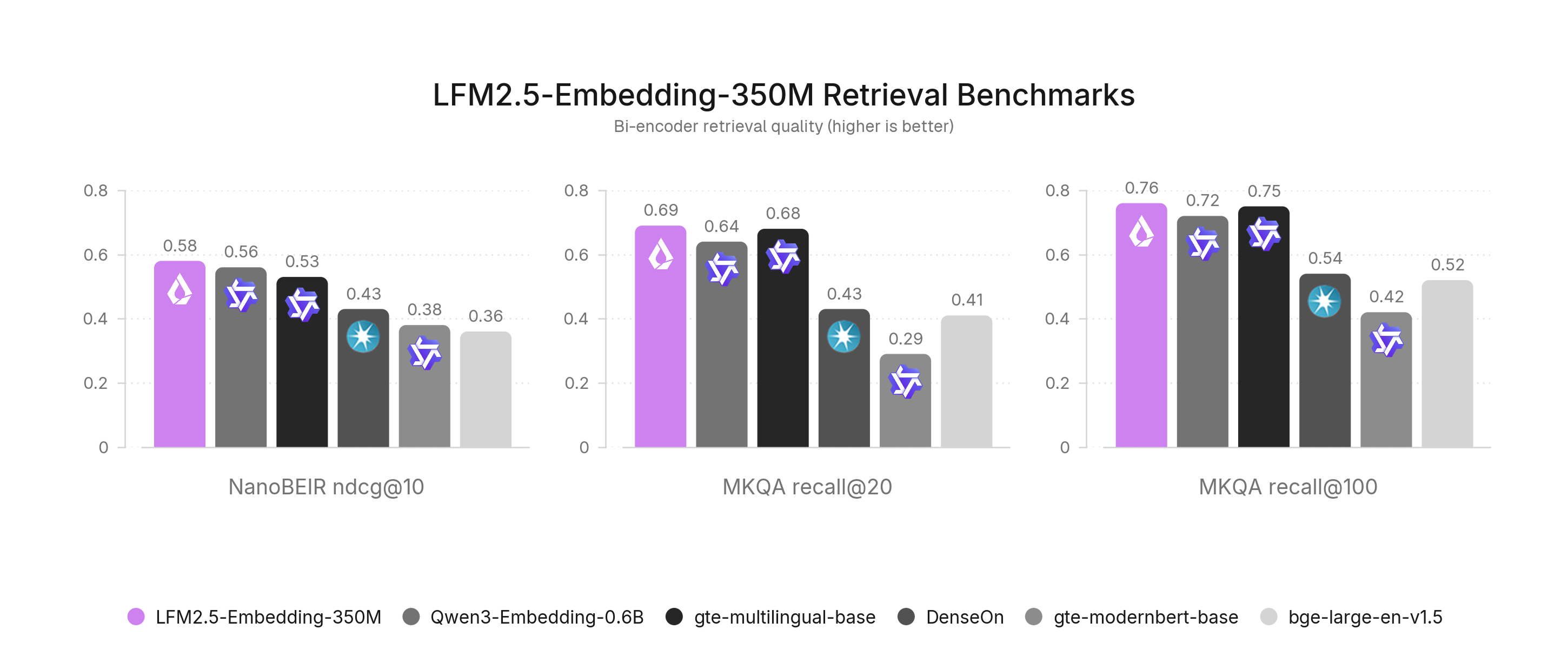
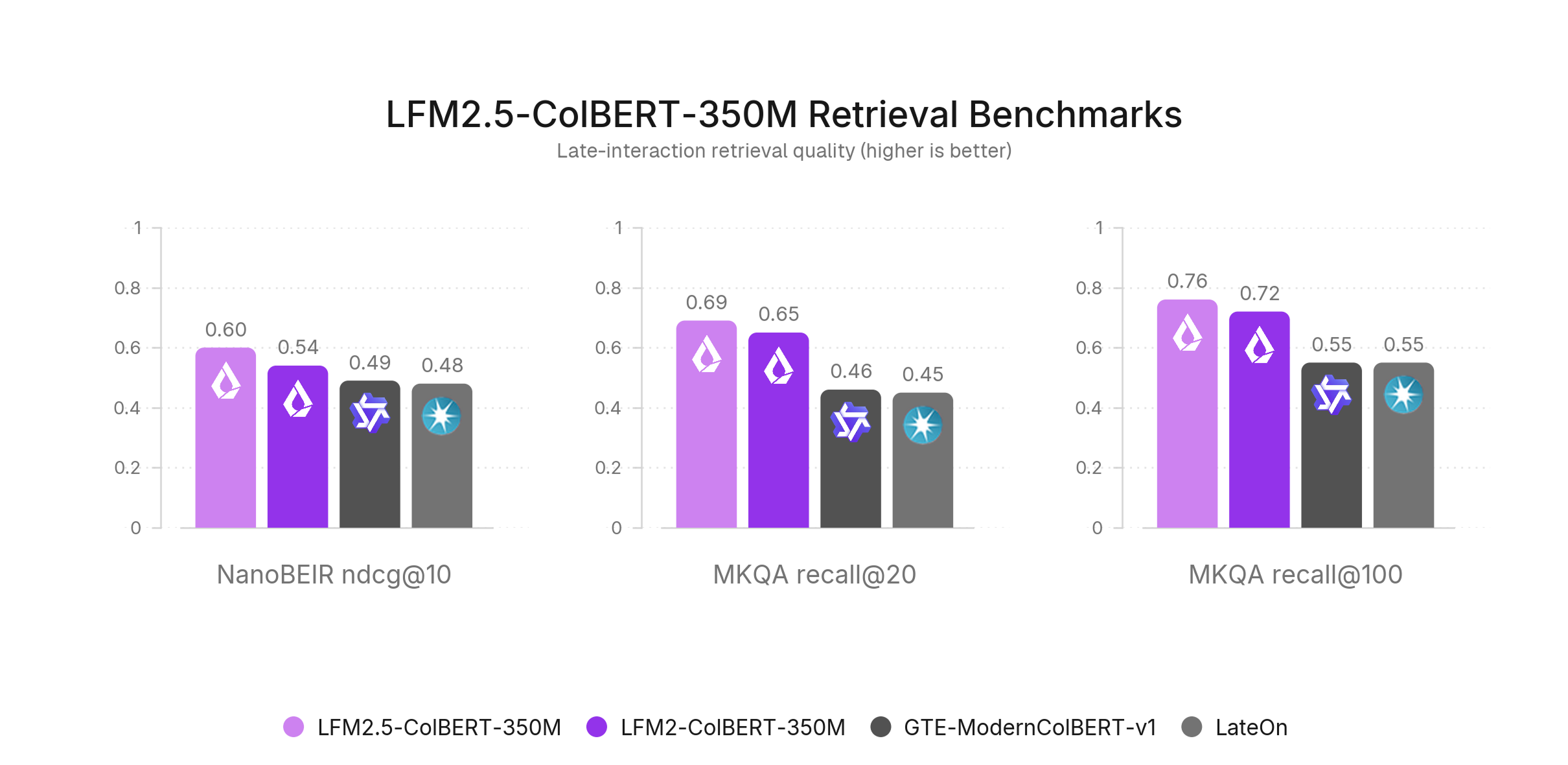
ベンチマーク
対応する全11言語(アラビア語、ドイツ語、英語、スペイン語、フランス語、イタリア語、日本語、韓国語、ノルウェー語、ポルトガル語、およびスウェーデン語)にわたる詳細なベンチマーク結果を報告します。評価では、NanoBEIRによる多言語検索と、MKQA-11によるクロスリンガルなオープンドメインQAという2つの能力に焦点を当てています。これらを組み合わせることで、モデルが言語内および言語境界を越えて関連ドキュメントを検索できるかを検証します。
全体として、LFM2.5-Embedding-350MとLFM2.5-ColBERT-350Mはいずれも、多言語およびクロスリンガル性能でクラス最高水準を示しています。結果は対応する全11言語で一貫して競争力があり、英語を超えた検索品質の堅牢性を示しています。
LightOnの研究とは異なり、NanoBEIR Englishは十分な評価シグナルを提供すると考えています。評価したモデル全体で、NanoBEIR Englishとより高コストなフルBEIRは高い相関を保っており、NanoBEIRのスコアはほぼ一定して約15%高くなります。そのため、トレーニング実行を反復する際には、NanoBEIRをフルBEIRの実用的な代理指標として使用しています。
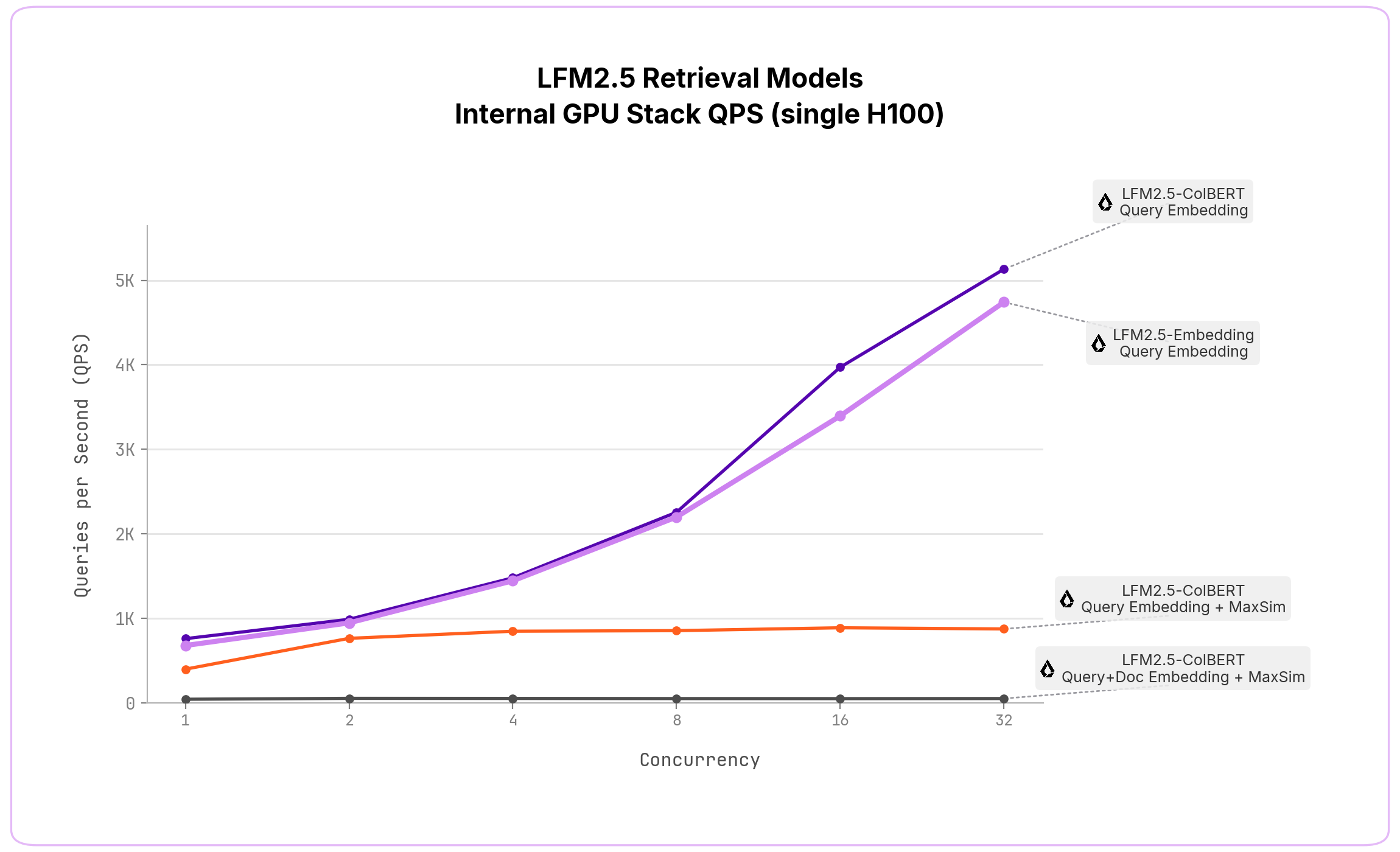
推論
実運用で重要となる検索レジームにおいて、エンドツーエンドのレイテンシを評価します。具体的には、キャッシュ済みドキュメントを用いたクエリ埋め込み、クエリ埋め込み+MaxSim、そしてドキュメントがキャッシュされていない場合のクエリ埋め込み+ドキュメント埋め込み+MaxSimです。
ポータブルなデプロイメント向けに、LFM2.5-ColBERT-350M-GGUFとLFM2.5-Embedding-350M-GGUFをllama.cpp向けにリリースします。これにより、モデルはほぼあらゆる環境(CPU、ラップトップ、エッジデバイス)で、ほぼゼロコストかつ魅力的なレイテンシで実行できます。
大規模な本番品質のエンタープライズデプロイメント向けには、高いインバウンド負荷の下で極めて低レイテンシなサービングを実現する社内GPUスタックも開発しています。
独自モデルのトレーニング
これらのモデルはそのままでも高い性能を発揮しますが、ドメイン固有の検索に合わせて、いずれかのモデルを独自データでファインチューニングすることをお勧めします。特にLFM2.5-Embedding-350Mについては、Hugging Faceのモデルカードにsentence-transformersを使用した簡単なファインチューニングスニペットが用意されているため、ファインチューニングを推奨します。
はじめに
LFM2.5-ColBERT-350MとLFM2.5-Embedding-350Mのモデルは、本日よりHugging Face。エンタープライズ規模で検索をデプロイしたいチームは、詳細についてお問い合わせください。