.svg)
本日、LFM2.5-350Mをリリースします。これは、追加の事前学習(10兆トークンから28兆トークンへ)と大規模な強化学習を施した、350Mモデルの改良版です。LFM2アーキテクチャに基づいて構築されており、非常に高速な推論を実現し、クラウドGPUから低コストなCPUまで、あらゆる環境で動作します。ツールの使用、データ抽出、構造化出力に優れており、350Mパラメータでありながら、大規模なデータ処理やエッジでの関数呼び出しに特化して設計されています。
開発者が利用している環境に対応するため、当社のモデルはCPU、NPU、GPUにわたる好みの推論エンジンやハードウェア上でシームレスに動作することを保証しています。私たちは、Zetic、RunAnywhere、MiraiをローカルAIエコシステムに迎え入れることを大変嬉しく思います。これにより、AMD、Qualcomm Technologies、Intel、LM Studio、Cactus Computeとともに、自動車、スマートフォン、ノートパソコン、IoT、組み込みシステム全体にわたる強力なエッジデプロイメントを推進します。さらに、Distil Labsとの新たな協業により、チームはモデルのトレースのみを使用して、高価で低速なLLMを置き換えるために、非常に効率的なLFMモデルを簡単にファインチューニングできるようになります。
ベースモデル(LFM2.5-350M-Base)およびポストトレーニング済みモデル(LFM2.5-350M)は、本日よりHugging Face、LEAP、そして当社のPlaygroundで利用可能です。ローカルでの実行およびファインチューニング方法については、ドキュメントをご確認ください。
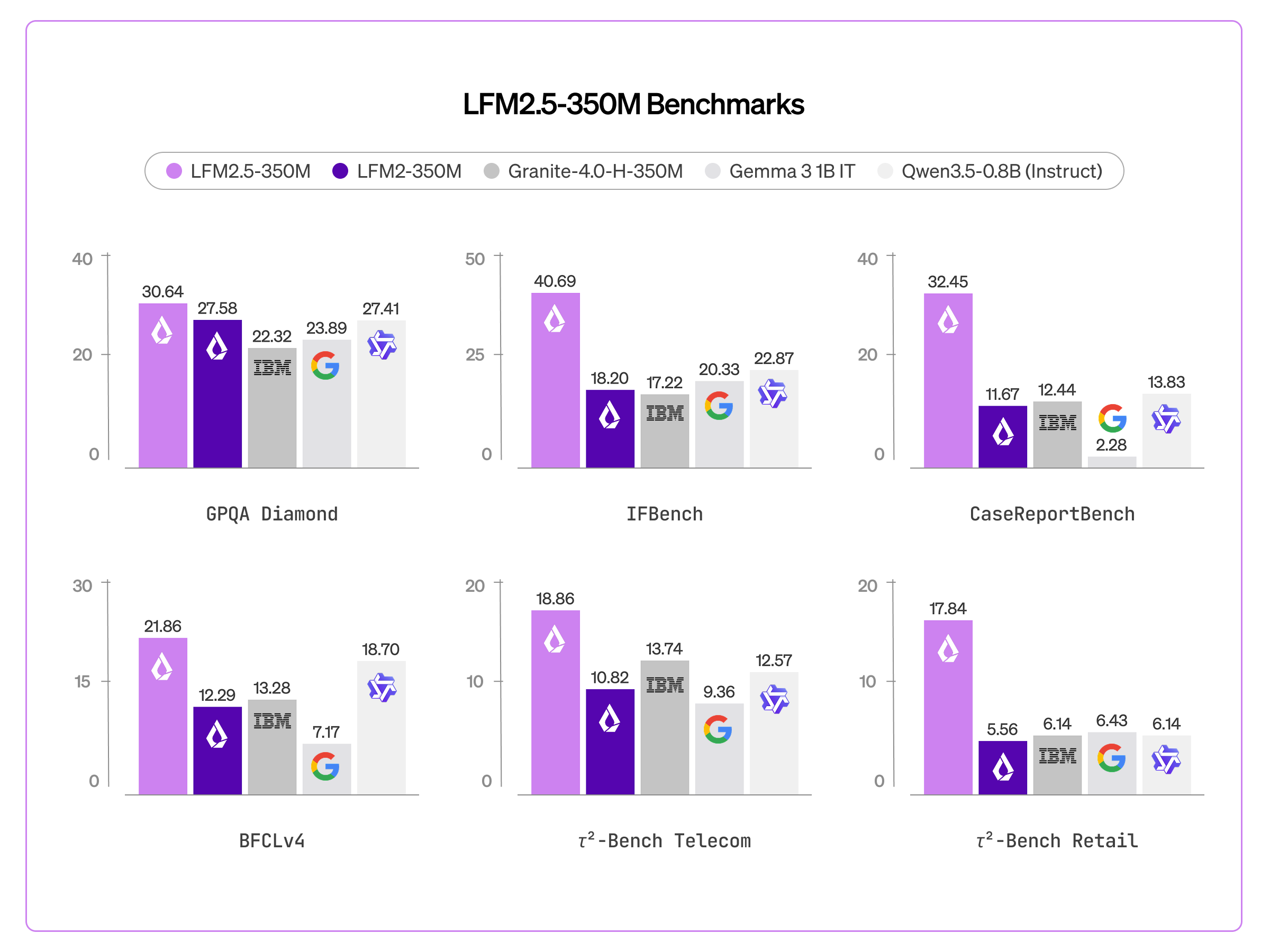
ベンチマーク
LFM2.5-350Mは、コア能力および応用タスクにわたる10種類のベンチマークで評価されました。知識(GPQA Diamond、MMLU-Pro)や指示追従(IFEval、IFBench、Multi-IF)といったコア能力において、またデータ抽出(CaseReportBench)やツール使用(BFCLv3、BFCLv4、𝜏²-Bench TelecomおよびRetail)といった特定のタスクにおいても、自身の2倍以上のサイズのモデルを上回る性能を示しています。
LFM2-350Mと比較して、3つの能力で大幅な改善が見られます:指示追従(IFBench 18.20 → 40.69)、データ抽出(CaseReportBench 11.67 → 32.45)、ツール使用(BFCLv3 22.95 → 44.11)。
これにより、LFM2.5-350Mは大規模なデータ抽出パイプラインや、軽量なオンデバイスのエージェント型パイプラインを支える理想的なソリューションとなります。ただし、数学、コード、クリエイティブライティングのようなタスクには推奨されません。
あらゆる環境での高速推論
LFM2.5-350Mは、リリース初日から推論エコシステム全体に対応しています:
- LEAP — iOSおよびAndroidデプロイのためのLiquidのエッジAIプラットフォーム
- llama.cpp — 効率的なエッジ推論のためのGGUFチェックポイント
- MLX — Apple Silicon向けに最適化された推論
- vLLM — 本番環境のスループットに対応するGPUアクセラレーションサービング
- SGLang — 本番環境のスループットに対応するGPUアクセラレーションサービング
- ONNX — 多様なアクセラレータに対応するクロスプラットフォーム推論
- OpenVino — Intelハードウェア向けの最適化およびデプロイツールキット
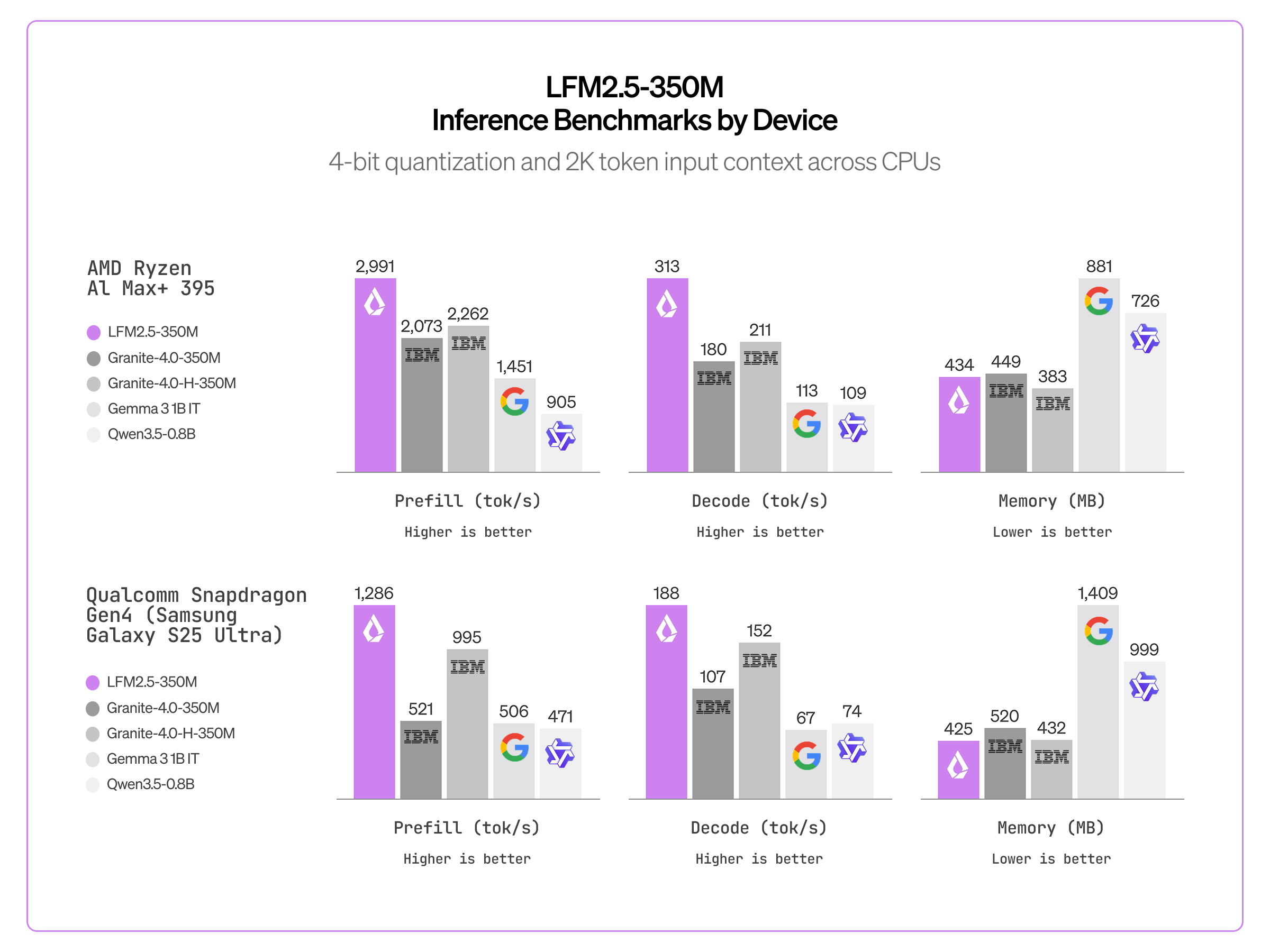
CPU推論。効率的なLFM2アーキテクチャにより、LFM2.5-350Mは、SSMハイブリッド(Granite-4.0-H-1B)やGated Delta Networks(Qwen3.5-0.8B)を含む同サイズのモデルと比較して、大幅に高速です。
GPU推論。ビッグデータ処理を可能にするため、vLLMやSGLangのような高スループット推論エンジンをサポートしています。出力スループット(総出力トークン数/経過時間)は、単一のNVIDIA H100 SXM5 GPU上で、持続負荷設定を用いて測定されます:各同時実行レベルにおいて、処理中リクエスト数を常に一定に維持し(1つのリクエストが完了すると即座に別のリクエストが送信されて置き換えられます)。

各モデルは、SGLang 0.5.9を用いて、同時実行レベル1から4,096までベンチマークされています。1,024入力トークンと最大256出力トークン(max_tokens=256)、BF16精度を使用しています。各実験は3回繰り返され、平均スループットが報告されます。LFM2.5-350Mは、このサイズカテゴリのモデルの中で最も高いピークスループットを達成し、高い同時実行時に毎秒40.4K出力トークンに達します。これは、単一のH100で1日あたり35億トークン以上に相当します。
Liquidのパートナーエコシステム拡大
.png)
LFM2.5ファミリーが必要なあらゆる場所で効率的かつ効果的に動作することを保証するために、私たちはハードウェアおよびソフトウェアのエコシステムを急速に拡大しています。本日、Mirai、Zetic、Runanywhereのようなシリコンリーダーや最適化ランタイムから、Distil Labsのようなカスタマイズパートナーまで、多様なパートナーグループを迎え入れることを大変嬉しく思います。特定のワークフロー向けにファインチューニングする場合でも、モバイルNPUやエッジデバイスにデプロイする場合でも、当社のエコシステムは開発者が好みの環境を選択し、すぐに開発を開始できるよう支援します。
本番環境向けのカスタマイズ:Distil Labs
新しい350Mモデルの限界を押し広げるために、私たちはDistil Labsと提携し、実世界のエージェントワークフローでLFM2.5のベンチマークを実施しました。スマートホーム、バンキング、ターミナルベースのユースケースにおけるマルチターンのインタラクション向けにモデルをファインチューニングすることで、ツール呼び出しの信頼性が大幅に向上し、対話全体を通じて95%以上の精度を達成しました。この結果は、LFM2.5が単に高速であるだけでなく、本番レベルのAIエージェントに求められる高度なやり取りにも十分対応できる能力を持っていることを示しています。
シリコンおよびソフトウェア最適化パートナー
LFM2.5をエッジに展開するために、私たちは主要なシリコンおよびソフトウェアパートナーと協力し、CPU、GPU、NPU全体でモデルの最適化を行いました。
AMD:AMDとのパートナーシップにより、LFM2.5-350Mは同社のRyzen™ AIハードウェア向けに完全に最適化されています。Ryzen™ AI推論エンジンを活用することで、CPU、GPU、NPU全体で高効率なローカル体験を提供します。
「AMDはLFM2.5-350MのDay 0サポートを提供できることを誇りに思います。当社のRyzen™ AIプロセッサは、このコンパクトでありながら強力なモデルのローカルデプロイに理想的なプラットフォームを提供します。」 - AMD AIプロダクトマネジメント コーポレートバイスプレジデント Ramine Roane
Qualcomm Technologies:QualcommのSoCの能力を最大限に活用するために、私たちはQualcomm Technologies、Zetic、Runanywhereと提携しました。ZeticのMelange実行レイヤーは、Qualcomm Snapdragon®デバイス上でLFM2.5 350MのDay 0サポートを提供します。これにより、開発者はカスタム最適化を必要とせずに、QualcommのCPU、GPU、NPUを即座に活用して高速なオンデバイス推論を実現できます。Zeticに加えて、RunAnywhereはSnapdragon対応をさらに拡張し、Hexagonアーキテクチャ向けに最適化されたシームレスな実行環境を提供します。
「LiquidAIがLFM2.5-350Mモデルで達成したことは、Qualcomm Technologiesで構築してきたオンデバイスAIアプローチの強力な検証です」と、Qualcomm Technologies, Inc. プロダクトマネジメント担当副社長兼Gen AI/ML責任者のVinesh Sukumarは述べています。「同社のアーキテクチャはモバイルおよびエッジデプロイの制約に独自に適しており、Qualcomm® Hexagon™ NPU上で実行すると、その性能が数値として現れます——低レイテンシ、低メモリ使用量、そしてサイズが数倍のモデルと競合する推論品質。この発表は、効率的なAIと高性能なAIがもはやトレードオフではないことを明確に示しています。」
Intel:IntelはネイティブなOpenVINO最適化により、LFM2.5 350Mに高速なパフォーマンスをもたらします。Intelハードウェア上での推論速度を最大化するよう設計されたこれらの即時実行可能なモデルは、現在Hugging Faceで利用可能です。
「Liquid AIのLFM 2.5 350MのパワーをIntelエコシステムにもたらすことを嬉しく思います。ネイティブなOpenVINO最適化を統合することで、IntelベースのエッジおよびAI PC環境全体で、卓越した推論速度と効率的なメモリ管理を実現できるようになります。」 - Intel AI PCソフトウェアエンジニアリング担当副社長 Sudhir Tonse Udupa
Apple Siliconエコシステム:Miraiエンジンによって駆動されるLiquidAIのLFM2.5-350Mは、Apple Siliconエコシステム全体で超高速のオンデバイス推論を実現します。ベンチマークでは、モバイル向けのA18 ProチップからデスクトップクラスのM1〜M5 Maxプロセッサまで、幅広いハードウェアで優れた生成速度が示されています。
低メモリエッジデバイス:高性能には高価なハードウェアが必須ではないことを示すために、Cactus ComputeはiPhone 13 Mini、Google Pixel 6a、Raspberry Pi 5のような300ドル未満のデバイス上で、LFM2.5 350Mが非常に高速に動作することを実証しました。Cactus Engineは、制約のあるエッジ環境向けにRAM使用量を大幅に最適化することでこれを可能にしています。
ユニバーサルなローカルデプロイ:最後に、LM StudioはLFM2.5 350MのDay 0サポートを提供します。開発者は、LM Studioのヘッドレスデーモンであるllmsterを使用して、このモデルをローカルのエッジデバイス上でシームレスに実行でき、ローカルでの実験とデプロイを容易に行うことができます。
LFM2.5-350Mの推論速度ベンチマーク
使い始める です
開始する本日からLFM2.5-350MおよびLFM2.5-350M-Baseを使って構築を始めましょう。これらは以下で利用可能です
.svg)

LFM2.5により、私たちはどこでも動作するAIというビジョンを実現しています。これらのモデルは次の特長を備えています:
- オープンウェイト — 制限なくダウンロード、ファインチューニング、デプロイが可能
- 初日から高速 — Apple、AMD、Qualcomm、Nvidiaのハードウェア全体で、llama.cpp、NexaSDK、MLX、vLLMをネイティブサポート
- 完全なファミリー — カスタマイズ用のベースモデルから、音声やビジョンに特化したバリアントまで、1つのアーキテクチャで多様なユースケースをカバー
エッジAIの未来はすでにここにあります。皆さんが何を構築するのか楽しみにしています。
引用
本記事を引用する場合は、以下のように記載してください:
Liquid AI, "LFM2.5-350M: No Size Left Behind", Liquid AI Blog, Mar 2026.または、以下のBibTeX引用をご利用ください:
@article{liquidAI2026350M,
author = {Liquid AI},
title = {LFM2.5-350M: No Size Left Behind},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/lfm2-5-350m-no-size-left-behind},
}