.svg)
本日、私たちはこれまでで最小のモデル LFM2.5-230M をリリースします。これは、開発者がファインチューニングし、エージェント型ワークフローにデプロイするための、高速かつ軽量な基盤モデルです。
LFM2アーキテクチャをベースに構築されており、非常に高速な推論を実現し、クラウドGPUから低コストCPUまで、あらゆる環境で動作します(Galaxy S25 Ultraで213 tok/sのデコード速度、Raspberry Pi 5で42 tok/s)。小規模なモデルでありながら、ツール利用やデータ抽出タスクにおいて驚くほど高い能力を発揮します。
ベースモデル LFM2.5-230M-Base とポストトレーニング済みモデル LFM2.5-230M は、本日よりHugging Faceで利用可能です。ローカル環境での実行方法やファインチューニング方法については、私たちのドキュメントをご覧ください。
トレーニングとファインチューニング
このモデルは、32Kコンテキスト拡張フェーズを含む 19Tトークン で事前学習されました。私たちは、開発者が自分たちの下流アプリケーションに合わせて活用できる柔軟性を保つため、軽量なポストトレーニング手法を適用しています。
この手法は、次の3段階で構成されています。
(1)LFM2.5-350M からの蒸留を用いた教師ありファインチューニング、
(2)直接選好最適化、
(3)マルチドメイン強化学習です。
最終チェックポイントは、すぐに使える高い能力と、下流タスクへの専門化に向けた適応性のバランスを取りながら、より大規模なモデルに対しても競争力を維持しています。
現在進行中の取り組みの初期例として、私たちは LFM2.5-230M を Unitree G1 ヒューマノイドロボット上にデプロイしました。このモデルは、オンボードの NVIDIA Jetson Orin 上で完全にオンデバイスで動作します。
ここでモデルは、スキル選択レイヤーとして機能します。単一の自然言語指示を受け取り、NVIDIAの SONIC フレームワークが提供する事前学習済みの低レベルスキルを呼び出す、一連のツールコールへと分解します。
このタスク向けに短時間のファインチューニングを行うことで、モデルは次のような自由形式のコマンドを、
「2秒間静止し、その後、秒速1メートルで3メートル前進し、片膝を前に出した片脚膝立ち姿勢を5秒間保持し、秒速0.5メートルで3メートル後退する」
ターゲット速度での時間指定歩行や片脚膝立ちといったスキルを連結する、構造化された複数ステップの計画へと変換します。
現段階では動作は意図的にシンプルなものですが、私たちはこれを非常に有望な兆候だと考えています。つまり、230Mパラメータのモデルでも、短時間でファインチューニングし、オンデバイスにデプロイすることで、ヒューマノイド向けの自然言語制御インターフェースとして機能できるということです。
https://www.youtube.com/shorts/CuMOWa2y1Ho
ベンチマーク
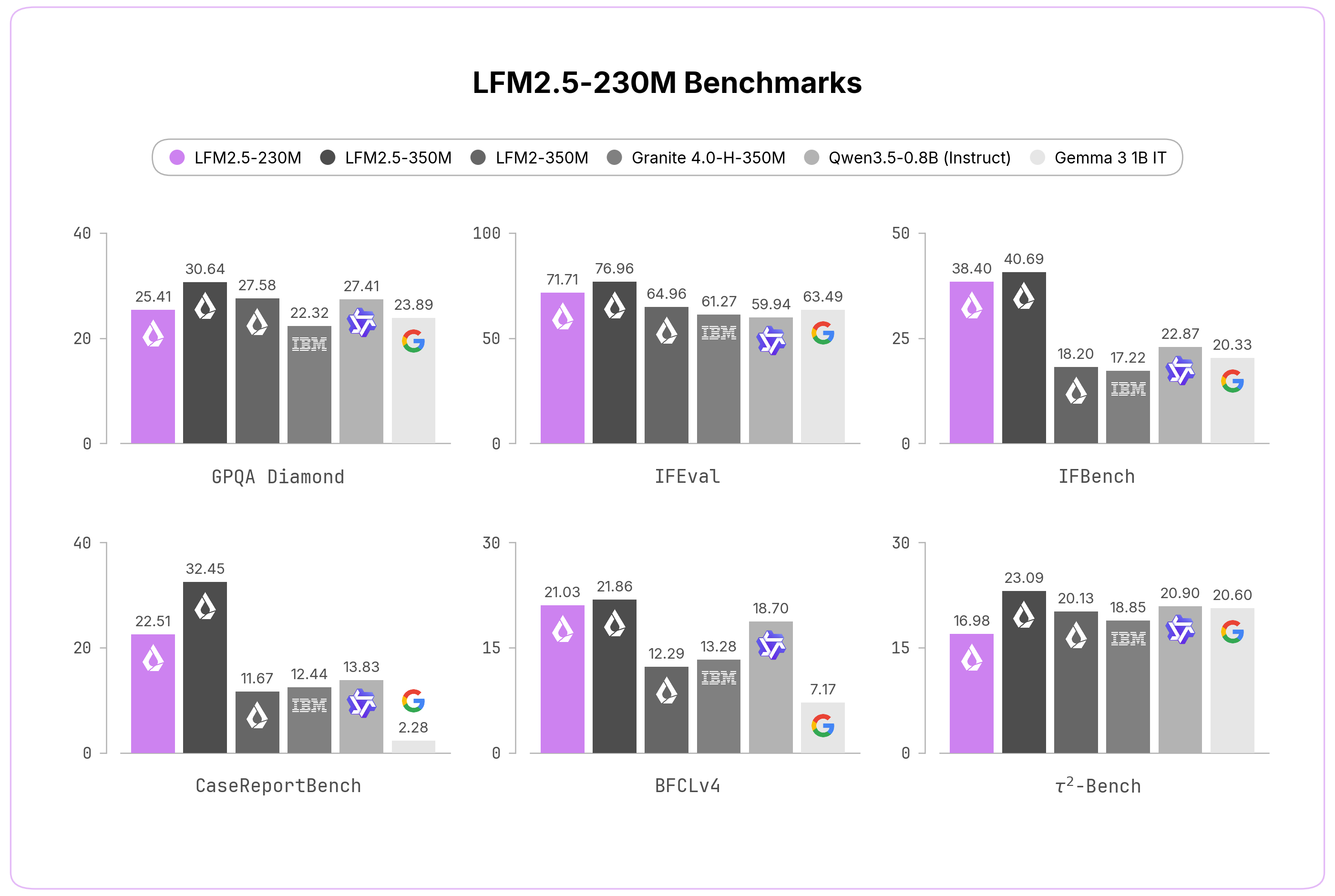
私たちは、コア能力と応用タスクの両方を対象とする10種類のベンチマークで LFM2.5-230M を評価しました。
その小さなサイズにもかかわらず、このモデルは2倍以上の規模を持つモデルと競合し、多くの場合それらを上回っています。評価対象には、知識能力(GPQA Diamond、MMLU-Pro)、指示追従(IFEval、IFBench、Multi-IF)、データ抽出(CaseReportBench)、ツール利用(BFCLv3、BFCLv4、τ²-Bench TelecomおよびRetail)が含まれます。
これにより、LFM2.5-230M は、大規模なデータ抽出パイプラインや、軽量なオンデバイスのエージェント型ワークロードを支える理想的なソリューションとなります。一方で、コンパクトなサイズであることを踏まえると、高度な数学、コード生成、クリエイティブライティングのような、推論負荷の高いワークロードには推奨していません。
どこでも高速推論
LFM2.5-230M は、推論エコシステム全体でリリース初日からサポートされています。
llama.cpp — 効率的なエッジ推論のためのGGUFチェックポイント
MLX — Apple Silicon向けに最適化された推論
vLLM — 本番環境のスループットに対応するGPUアクセラレーション推論サービング
SGLang — 本番環境のスループットに対応するGPUアクセラレーション推論サービング
ONNX — 多様なアクセラレータに対応するクロスプラットフォーム推論
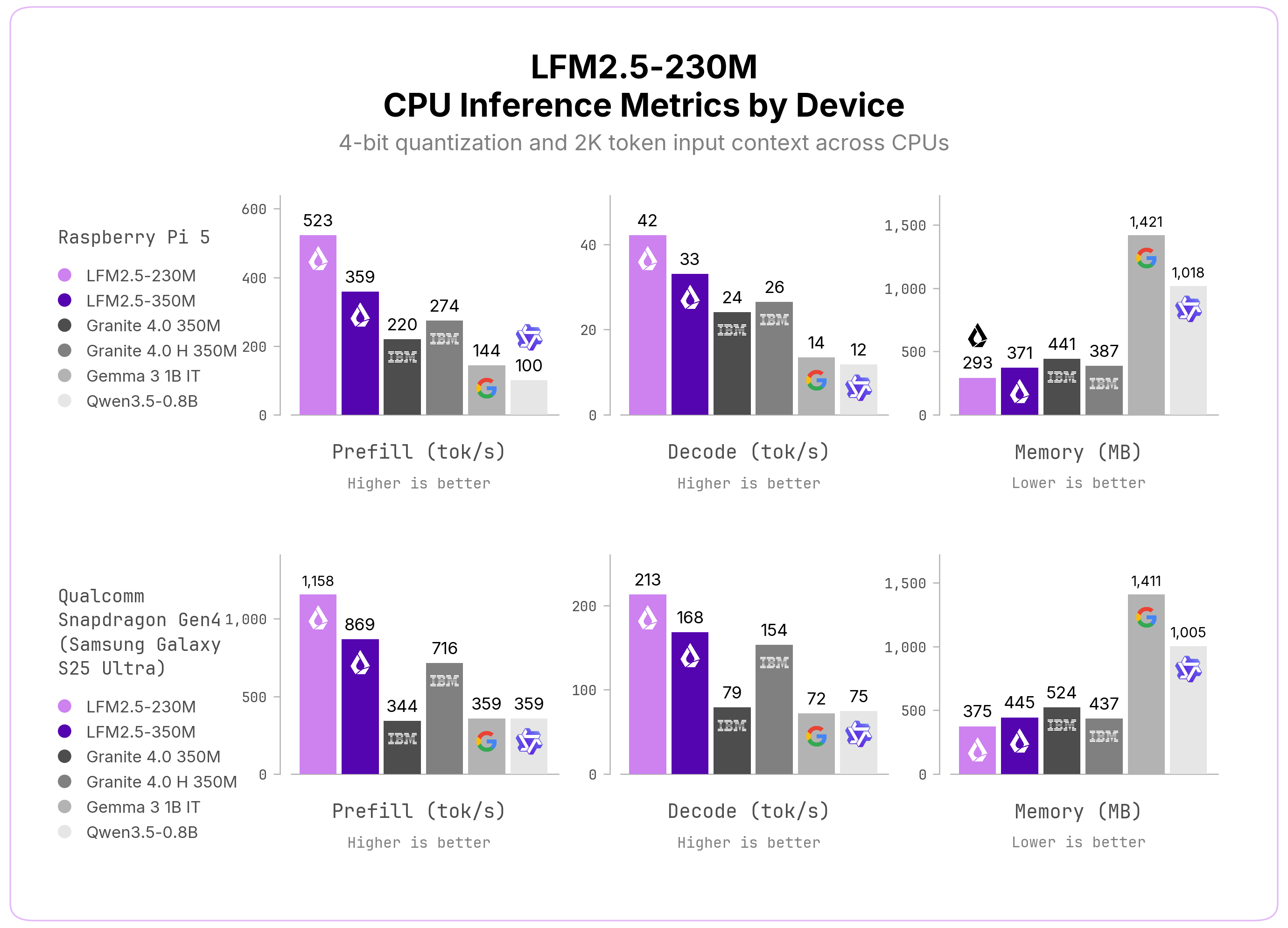
CPU推論。 効率的なLFM2アーキテクチャにより、LFM2.5-230M は、SSMハイブリッドやGated Delta Networksを含む同規模モデルと比べて、かなり高速です。Raspberry Pi 5とQualcomm Snapdragon Gen4(Samsung Galaxy S25 Ultra)のどちらにおいても、同クラスで最高のプリフィルおよびデコードスループットを実現しながら、メモリフットプリントは最小に抑えています。各プラットフォームでプリフィル性能を最大化するため、デバイスごとにflash-attentionフラグを調整しています。Raspberry Pi 5では有効(-fa 1)、Snapdragon Gen4では無効(-fa 0)にしています。
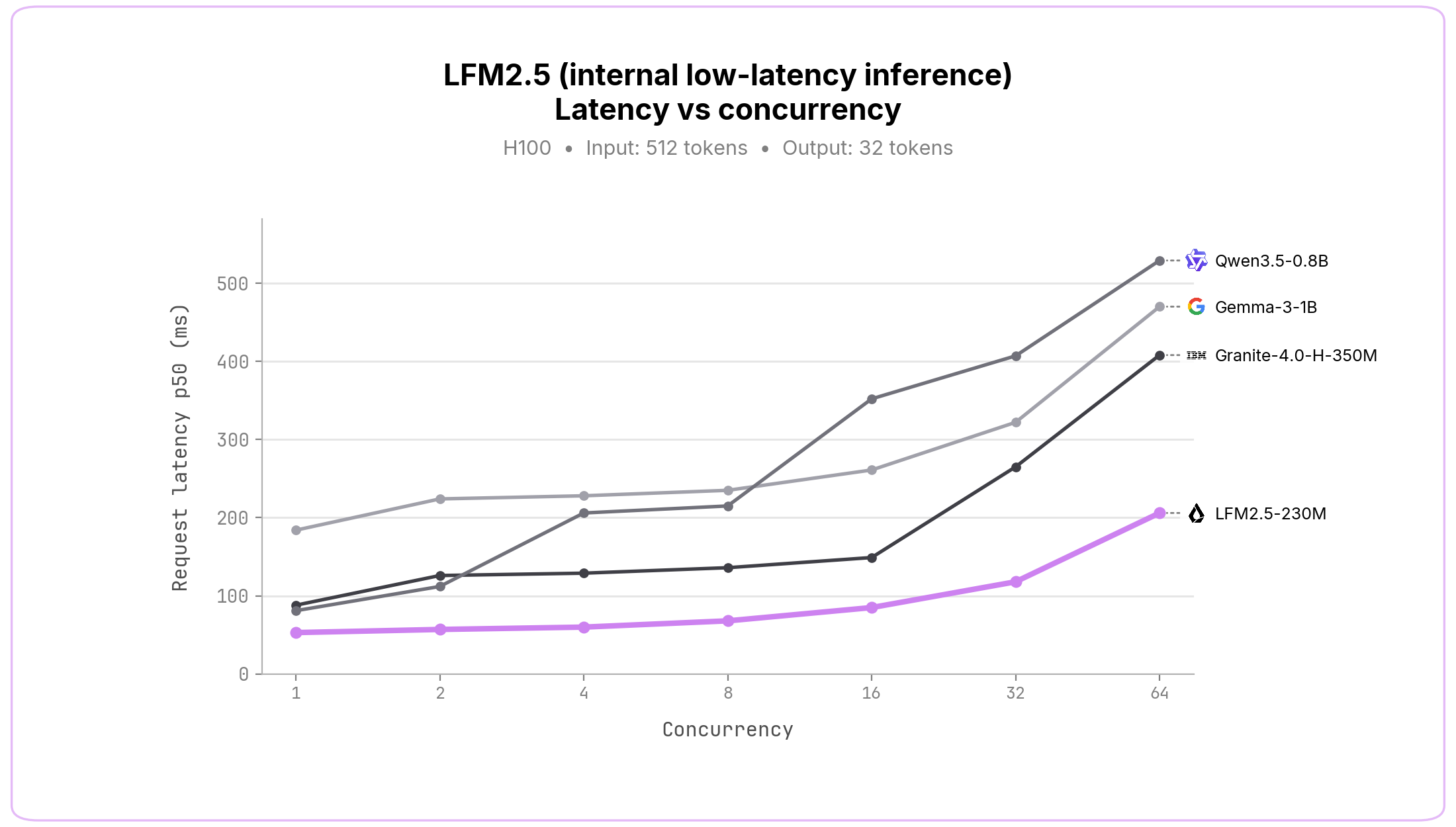
GPU推論。 本番レベルのエンタープライズデプロイメント向けに、私たちは極めて低レイテンシなサービングを実現する社内GPU推論スタックも開発しました。これを、SGLang上で動作する他の小型モデルと比較してベンチマークしたところ、すべての同時実行レベルにおいて、LFM2.5 モデルはエンドツーエンドのレイテンシを大幅に低く抑えることができました。
はじめる
Hugging Faceで利用可能な LFM2.5-230M と LFM2.5-230M-Base を使って、今すぐ開発を始めましょう。
LFM2.5 によって、私たちは「どこでも動作するAI」というビジョンを実現しています。これらのモデルは、次の特徴を備えています。
- オープンウェイト — 制約なくダウンロード、ファインチューニング、デプロイが可能
- 初日から高速 — Apple、AMD、Qualcomm、Nvidiaハードウェア全体で、llama.cpp、NexaSDK、MLX、vLLMをネイティブサポート
- 完全なファミリー — カスタマイズ向けのベースモデルから、音声・ビジョンに特化したバリアントまで、ひとつのアーキテクチャが多様なユースケースをカバー
エッジAIの未来は、すでにここにあります。皆さんが何を作るのか、楽しみにしています。