.svg)
課題:ハイブリッドアーキテクチャ向け推論エンジンの探索
2025 年初頭、Liquid AI で第 1 世代のオープンウェイトモデル LFM2 の開発を開始した際、私たちは重大な課題に直面しました。それは、既存の推論エンジンでは、同時にプロファイリングが必要となる多様なアーキテクチャを十分に扱えなかったことです。
私たちの目標は、デバイス上で実行可能な第 1 世代の超高効率言語モデルを構築することでした。LFM2 を設計・選定する過程では、さまざまな注意機構、畳み込み層、複数タイプのリカレント構造など、多岐にわたるモデル、層、演算を評価する必要がありました。これらの多くは、現実的なトークン生成プロファイリングを行うためにハイブリッドキャッシュを必要とします。
当初はいくつかの一般的な推論エンジンを検討しましたが、すぐに限界に直面しました。多くのエンジンは標準的な Transformer モデル向けに最適化されており、私たちのアーキテクチャが必要とするハイブリッドキャッシュ機構を十分にサポートしていなかったのです。適切な推論エンジンがなければ、革新的なアーキテクチャを妥協するか、デプロイ先をクラウド限定にせざるを得ないリスクがありました。
私たちには、オンデバイス AI アプリケーションに求められる性能と効率性を維持しながら、ハイブリッドなモデル構造を処理できるソリューションが必要でした。
ソリューション:ExecuTorch のエンタープライズグレード自動化
エンタープライズ向けの自動化オプションを検討した結果、私たちは PyTorch ExecuTorch を採用しました。そして、この選択はすぐに成果をもたらしました。
ExecuTorch が提供する ハイブリッドキャッシュのサポートは非常に魅力的で、LFM2 独自のアーキテクチャを初期段階から効率的に実行できました。しかし、ExecuTorch を真に際立たせていたのは、自動化されたエンタープライズグレードのデプロイアプローチです。
単一のコマンドライン命令で、エクスポート可能な計算グラフを、ウェイト、メタデータ、実行グラフを含む自己完結型バンドルに変換できます。モデルの実行に必要なすべてが 1 つにまとめられています。
この合理化されたワークフローは、実装とモデル情報を分離し、開発者がコンポーネントごとに互換性のあるランタイムを個別に管理しなければならない他の推論エンジンとは対照的でした。その結果、反復サイクルが短縮され、デプロイの複雑さに費やす時間を大幅に削減できました。
もちろん、統合は完全にシームレスではありませんでした。LFM2 に含まれる一部のカスタム演算では、モデルをエクスポート可能にするために 約 2〜3 週間のグラフ修正が必要でした。しかし、この初期のエンジニアリング投資を終えると、ExecuTorch の自動化アプローチが大きな効果を発揮し始めました。
2025 年 7 月までに、LFM2 はオンデバイスで安定して動作する状態となり、世界に向けてリリースされました。
特に価値があったのは、初期段階の問題解決において非常に助けとなった ExecuTorch メンテナーからのサポートです。彼らの協力的な姿勢は、新しいモデルアーキテクチャに新しいインフラを導入する際に避けられない課題を乗り越えるうえで、大きな支えとなりました。
次のセクションでは、ExecuTorch 上で動作する LFM2 の推論ベンチマーク結果を紹介します。
結果:デバイス全体で確認された定量的なパフォーマンス向上
ExecuTorch を搭載したモデルを、以下の 2 つのハードウェアプラットフォームでテストしました。
- AMD Ryzen AI 9 HX 370
- Samsung Galaxy S24
350M から 4B パラメータまで、複数の LFM2 モデルサイズにおいて、一貫したパフォーマンス向上が確認されました。
- 低レイテンシーな プリフィルフェーズおよびデコードフェーズにより、リアルタイムアプリケーションを実現
- メモリフットプリントの削減により、メモリ制約のあるデバイスへの展開が可能
- モデルファイルサイズの縮小により、ダウンロードおよびインストールを高速化
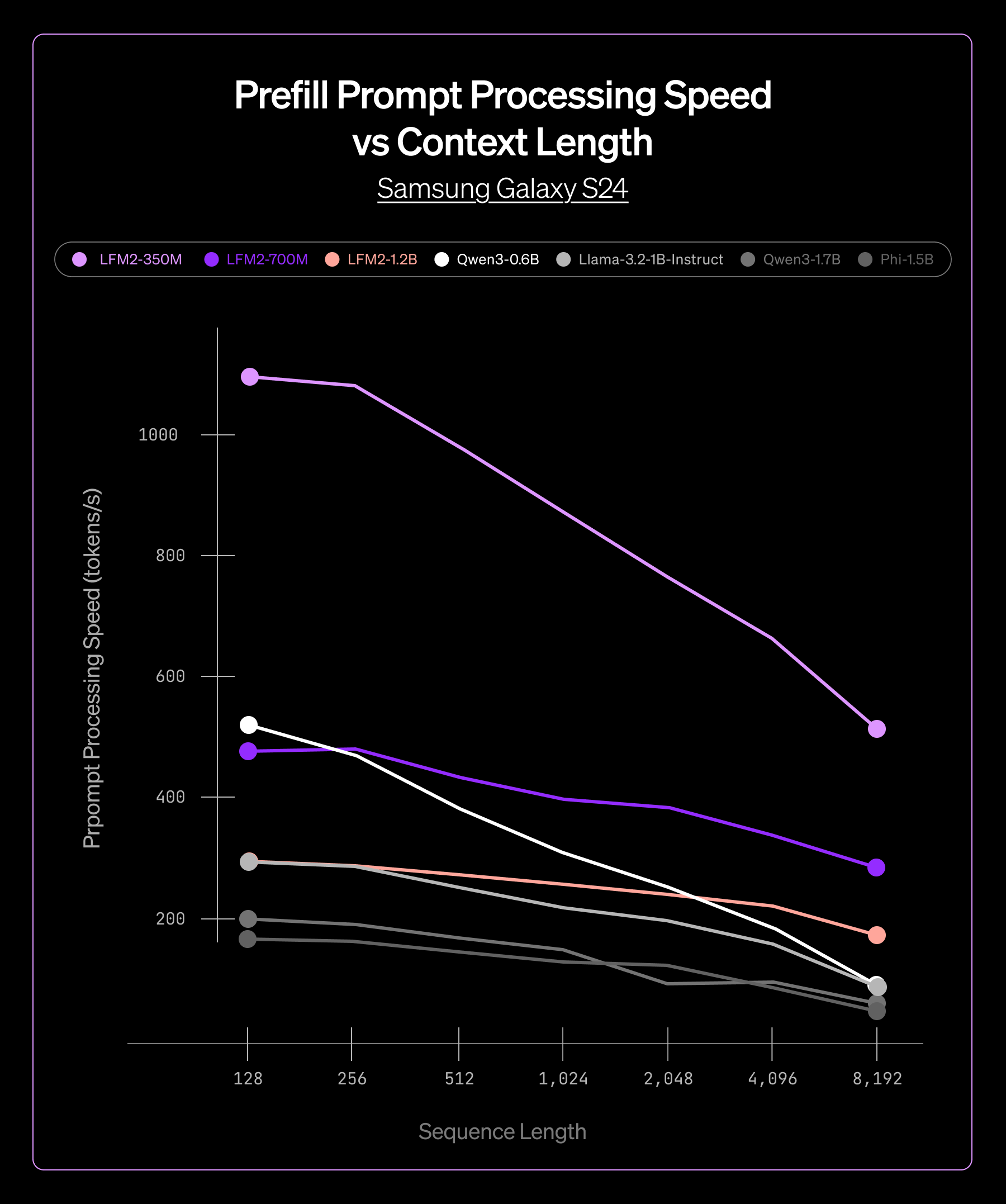
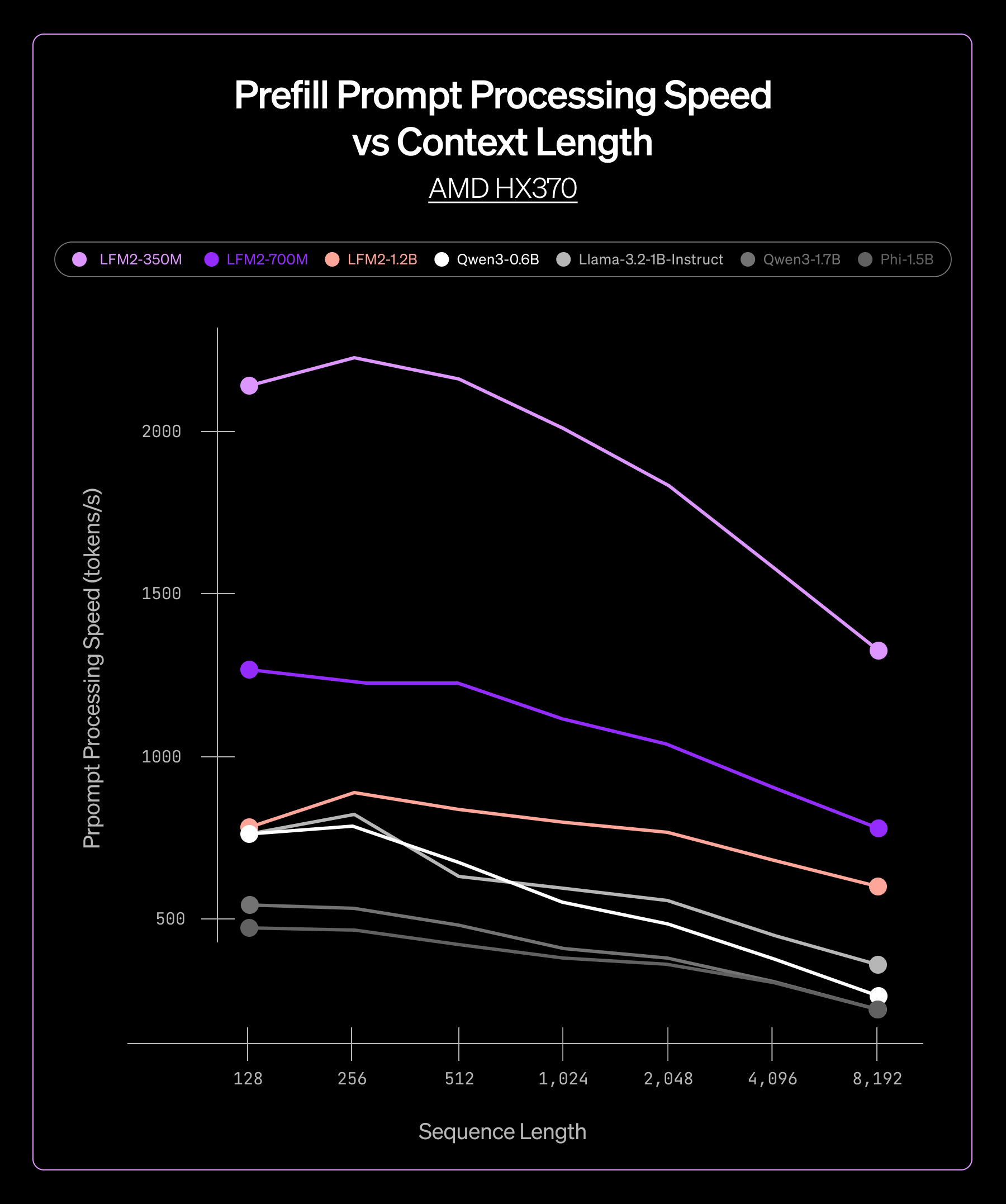

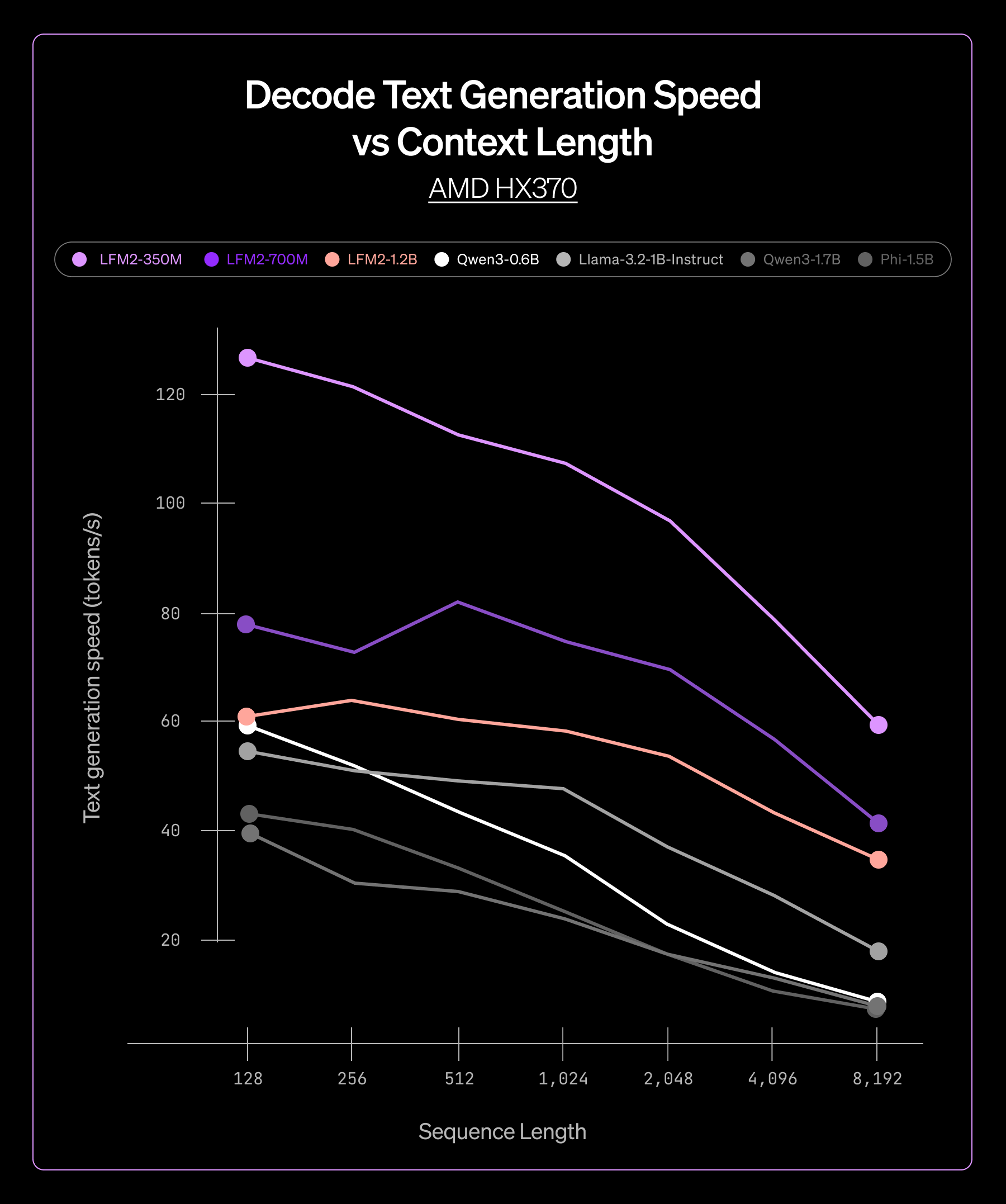
この一貫性により、モデルサイズやターゲットハードウェアに依存せず信頼性の高い性能を提供できることが確認でき、ExecuTorch を製品ライン全体に自信を持って導入することができました。
