.svg)
現在 AI アプリケーションを構築するには、クラウド推論を利用する必要があり、その結果としてレイテンシー、コスト、プライバシーといった課題がつきまといます。もし、ユーザーのノート PC 上で強力な AI モデルを直接実行し、100ms 未満の応答時間を実現できるとしたらどうでしょうか?
本日、私たちはエッジ AI プラットフォームである LEAP を日常的な PC やノート PC に展開する方法を発表します。第一弾として、AMD Ryzen プロセッサ上で動作する LFM モデルを提供します。
ハードウェア断片化の課題
エッジ AI の展開には大きな複雑性が伴います。x86 と ARM アーキテクチャ、複数の GPU ベンダー、そして Windows・macOS・Linux という 3 大 OS がそれぞれ異なる要件を持っているからです。すべての組み合わせにネイティブ対応するには、膨大なエンジニアリングリソースと時間が必要になります。
私たちは「コミュニティ第一」のアプローチを取ります。ゼロからすべてを構築するのではなく、すでに本番環境で開発者が利用している確立されたツールと連携します。
llama.cpp を基盤に
最初の統合対象は llama.cpp です。これはコンシューマーハードウェア上で効率的な推論を行う事実上の標準であり、成熟したエコシステムと活発なコミュニティによって、多くの重要な最適化課題がすでに解決されています。
推論エンジンとして llama.cpp を採用することで、LEAP は既存のワークフローにシームレスに統合されます。
- Python 開発者は既存のツールチェーンと並行してバインディングを利用可能
- Node.js 開発者は C++ の複雑さなしにネイティブパフォーマンスを享受
- llama.cpp エコシステム全体のツールと最適化がそのまま利用可能
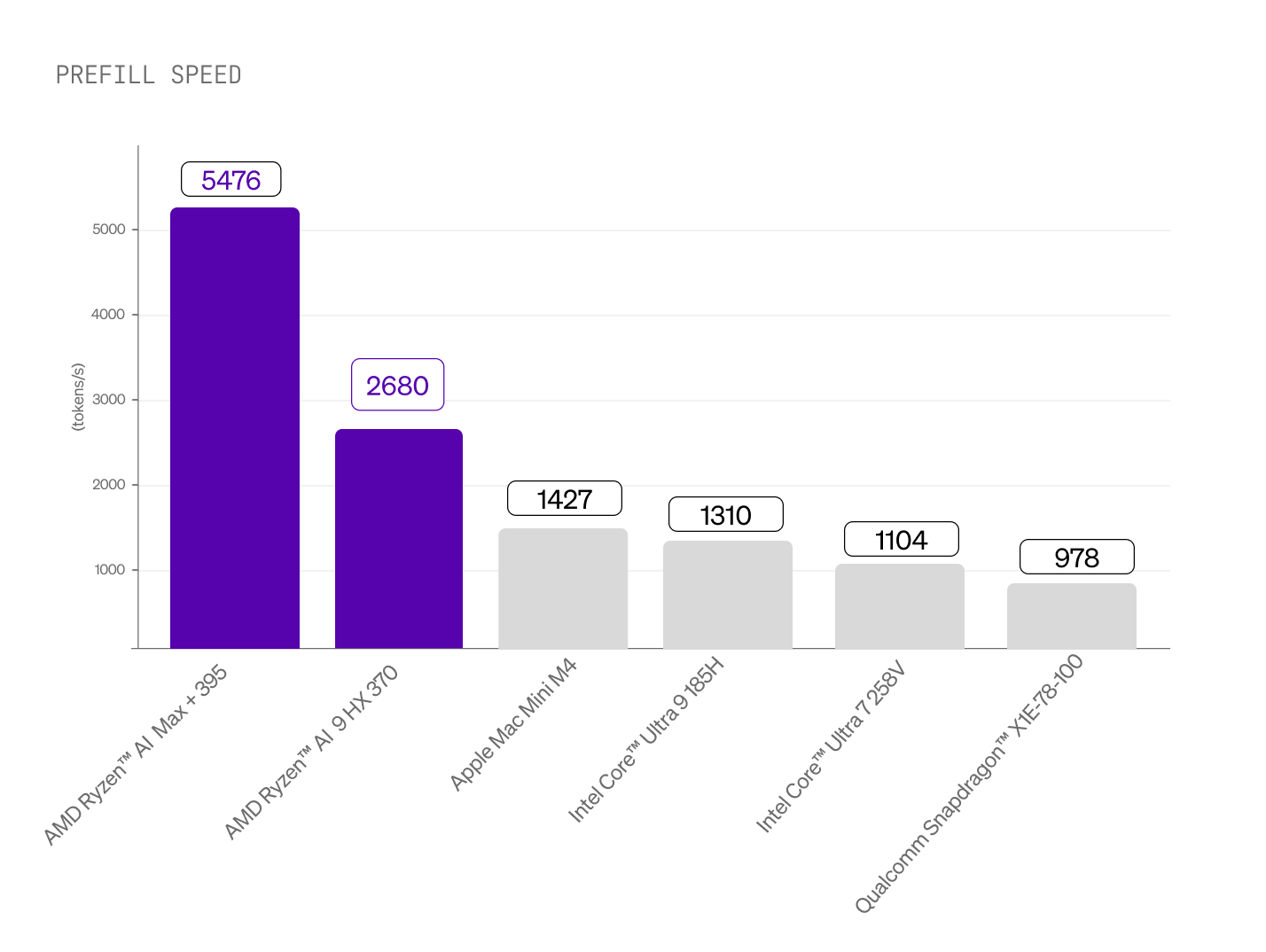
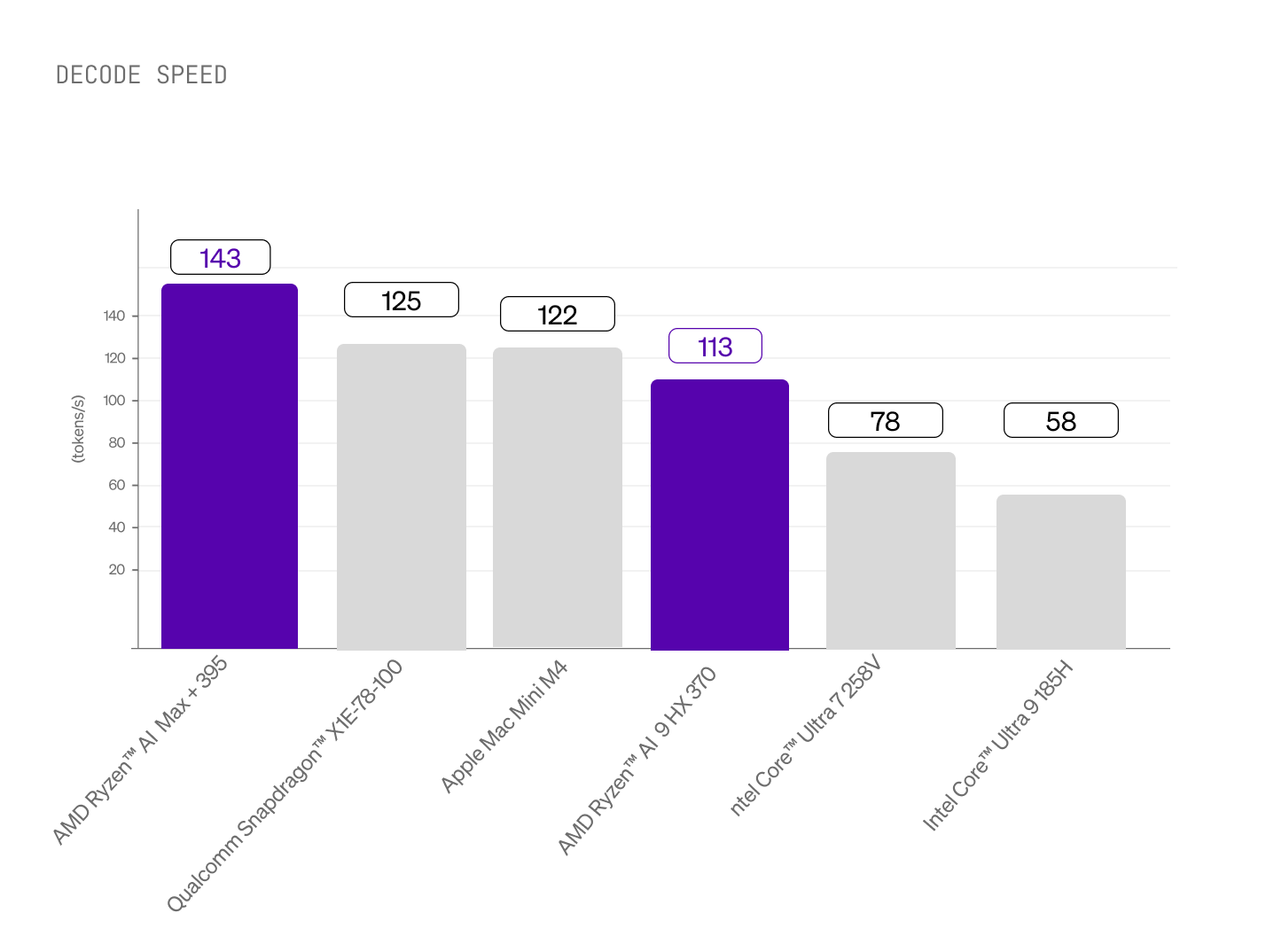
コンシューマーハードウェア全体で徹底的なベンチマークを行った結果、AMD Ryzen AI プロセッサは LEAP の展開において最高のパフォーマンスを発揮しました。図1では、プリフィル(プロンプト処理)およびデコード(トークン生成)操作における性能をトークン毎秒で比較しています(数値が高いほど良い)。公平な比較のため、公式 llama.cpp GitHub リポジトリで公開されている llama-bench 実行ファイルを使用し、利用可能なすべての GPU バックエンドを含め、CPU バックエンドについてはスレッド数(4、8、12)を変えて測定し、それぞれのハードウェアで観測された最大値を報告しています。
プロンプト処理における統合 Radeon グラフィックス
統合 GPU がプロンプト処理を担当し、ディスクリート GPU に匹敵する速度を実現します。追加のコスト、電力消費、統合の複雑さはありません。これにより、本当の意味でリアルタイムなアプリケーション体験が可能になります。
優れた CPU デコード性能
トークン生成は AMD の Zen 5 アーキテクチャと高度なベクター命令セットを活用し、コンシューマーハードウェアで測定された中でも最速クラスのデコード/生成速度を実現します。この組み合わせにより、プロンプト処理には GPU アクセラレーション、ストリーミング生成には最適化された CPU 性能を提供し、すべてを 1 つのチップで実現します。そしてそのチップは、すでに数百万台のデバイスに搭載されています。
LEAP で構築する
AMD ハードウェア上で llama.cpp を介してローカル実行される LEAP により、開発者は次のような構築が可能になります:
- 機密データをデバイス上に保持するプライバシー重視のアプリケーション
- 一貫して 100ms 未満のレイテンシーを実現するリアルタイム AI 機能
- インターネット接続がなくても動作するオフライン対応ソフトウェア
- クラウド推論コストを排除した費用対効果の高いソリューション
同じコードが llama.cpp をサポートするあらゆる環境で動作するため、ベンダーロックインは発生しません。
はじめに
LEAP プラットフォームの包括的なドキュメントを用意しました。内容は以下を含みます:
- llama.cpp バックエンドを使用した LEAP のインストール
- LFM-2 モデルのロードと実行
- Python および Node.js アプリケーションとの統合
- AMD Ryzen ハードウェア向けのパフォーマンス最適化
SDK は本日より利用可能で、ベンチマークや実装例も提供しています。
次のステップ
今回の AMD 統合は、強力な AI をエッジデバイスで普及させるための第一歩です。直近のロードマップには次が含まれます:
- LFM-2-VL サポート:テキストと画像の両方をローカルで処理できるマルチモーダルアプリケーションを可能にするビジョン・ランゲージモデルをエッジデバイスへ展開
- さらなるメモリおよび電力最適化:GPU と NPU を活用
- llama.cpp 以外の推論エンジンとの統合
AI の未来はデータセンターの外に広がり、ユーザーがすでに所有するデバイスへと拡張されます。私たちは、その未来をすべての開発者に届けるためのインフラを構築しています。
提供状況
AMD アクセラレーションに対応した LEAP SDK は本日から利用可能で、LFM-2 モデルファミリーをサポートしています。開発者は leap.liquid.ai でツール、ベンチマーク、ドキュメントを確認できます。
はじめる方法
エッジ展開のカスタムソリューションにご関心がある場合は、弊社セールスチーム(sales@liquid.ai)までお問い合わせください。

