.svg)

Liquid Nanosをリリースします。Liquid Nanosは、350M〜1.6Bパラメーター規模のファンデーションモデルのファミリーで、電話・ノートパソコン・組み込みデバイス上で直接動作しながら、特殊なエージェントタスクをフロンティアモデル並みの品質で実行します。
パートナーとの評価では、Nanosは何百倍も大きいモデルと競合できる性能を示しました。その結果、クラウドに依存しない経済性を備えた地球規模のAIエージェントが実現します。
なぜNanosなのか、そしてなぜ今なのか?ここ数年のAIの進歩は、かつてないほど大規模なモデルと巨大なデータセンターによって支えられてきました。
しかし現実には、コスト・エネルギー・遅延・プライバシーといった制約があります。すべてのトークンをクラウドに送信する方式では、多くのユースケースをすべての人に提供することは困難です。
Nanosはこの導入モデルを転換します。データをフロンティアモデルに移すのではなく、コンパクトで高性能なインテリジェンスをデバイスに届けます。これにより、スピード、レジリエンス、プライバシー、そしてスケーラブルなコスト構造が実現します。
Liquid Nanosとは
Liquid Nanosは、100MB~2GBのRAMを使用する低レイテンシのタスク専用Liquid Foundation Models(LFM2ファミリー)です。高度な事前トレーニングと特殊なポストトレーニングを組み合わせることで、エージェントAIの基盤となるタスクにおいてフロンティアグレードの結果を実現します。
対応タスクは以下のとおりです:
- 正確なデータ抽出と構造化出力の生成
- 多言語理解
- 長文コンテキストでの検索拡張生成(RAG)
- 数学と推論
- エージェントワークフローにおけるツール/関数呼び出し
数億〜10億規模のパラメーターという小さなフットプリントながら、設計されたタスクにおいては大規模な汎用モデルに匹敵、またはそれに近い品質を実現します。さらに、最新のスマートフォンやPC上で完全にオンデバイスで動作します。
本日、実験的なタスク専用Nanosの第1シリーズを公開します。今後さらに追加予定です。
- LFM2-Extract — 非構造化テキストからのデータ抽出用の350Mおよび1.2B多言語モデル(例:請求書メールをJSONオブジェクトに変換)。
- LFM2-350M-ENJP-MT — 英語 ↔ 日本語の双方向翻訳用350Mモデル。
- LFM2-1.2B-RAG — RAGパイプラインでの長文コンテキスト質問応答に最適化された1.2Bモデル。
- LFM2-1.2B-Tool — 関数呼び出しやエージェントツール利用のために構築された1.2Bモデル。
- LFM2-350M-Math — 数学的問題を解決するための350M推論モデル。
- Luth-LFM2 — デバイス上でのチャット用汎用アシスタントを可能にする、コミュニティ主導のフランス語ファインチューニングシリーズ。
リキッドナノ
ほとんどのエッジAIアプリケーションには、翻訳や関数呼び出しなど、特定のタスクで優れた性能を発揮するモデルが必要です。通常、そのためには特定のタスクに合わせて汎用モデルを微調整する必要があります。しかし、時間、データ、または計算資源の不足により、微調整は多くのユーザーにとって依然として課題となっています。このギャップを解消するため、タスク固有の LFM2 モデルを収録したモデルライブラリを作成しました。これらの専用チェックポイントは、ごく小さなメモリフットプリントで非常に高品質な出力を提供します。この拡大を続けるライブラリに含まれるすべてのモデルは Hugging Face で入手可能で、LEAP および Liquid Apollo とも直接互換性があります。

AI分野では、より大規模なモデルを追求する競争が主流ですが、実際には、小規模で微調整されたモデルが特定のタスクにおいて1,000億パラメータを超えるモデルの性能と同等、あるいはそれ以上を実現することもあります。こうした小規模な専用モデルは、コスト、レイテンシー、プライバシー、接続要件などの制約によりクラウドモデルの利用が現実的でない、あるいは不可能な環境でも AI アプリケーションを可能にします。
LFM2-Extract
LFM2-350M-Extract と LFM2-1.2B-Extract は、さまざまな非構造化文書(記事、トランスクリプト、レポートなど)から重要な情報を JSON、XML、YAML といった構造化出力に抽出するように設計されています。英語、アラビア語、中国語、フランス語、ドイツ語、日本語、韓国語、ポルトガル語、スペイン語の入力に対応しています。
-Lightmode.png)
ユースケース:
- メールから請求書の詳細を構造化された JSON に抽出する。
- 規制関連書類をコンプライアンスシステム用の XML に変換する。
- カスタマーサポートチケットを分析パイプライン用の YAML に変換する。
- ナレッジグラフに非構造化レポートのエンティティと属性を追加する。
LFM2-Extract を使用するには、入力ドキュメントとオプションのスキーマテンプレートのみが必要です。特に長くて複雑な文書の精度を向上させるために、このスキーマテンプレートをシステムプロンプトに含めることをお勧めします。
これらのモデルのトレーニングに使用されたデータは主に合成データであり、多様なデータを組み合わせることができました。文書タイプ、ドメイン、スタイル、長さ、言語を幅広く使用しました。また、文書内の関連テキストの密度や分布も変化させました。抽出された情報が文書の一部に集中している場合もあれば、文書全体に分散している場合もあります。合成ユーザーのリクエストを作成し、モデル出力の構造を設計するときも、多様性を確保するという同じアプローチを採用しました。データ生成プロセスは Liquid AI チーム全体からのアイデアとフィードバックを取り入れて何度も繰り返されました。
LFM2-Extract は、記述スタイル、あいまいさ、形式が混在する 100 を超えるトピックをカバーする 5,000 のドキュメントのデータセットで評価しました。5 つの指標を組み合わせて、構文、正確さ、忠実性についてバランスの取れた評価を行いました。
- 構文スコア: 出力が有効な JSON、XML、または YAML として正しく解析されるかどうかを確認します。
- フォーマット精度: 出力が要求された形式(JSON が要求された場合は JSON など)と一致することを確認します。
- キーワード忠実性: 構造化出力の値が実際に入力テキストに現れるかどうかを測定します。
- 絶対得点: ジャッジ LLM が抽出の完全性と正確性を評価し、1〜5 のスケールで品質を採点します。
- 相対スコア: ジャッジ LLM に、抽出モデルの出力とグラウンドトゥルース回答のどちらが優れているかを選ばせます。
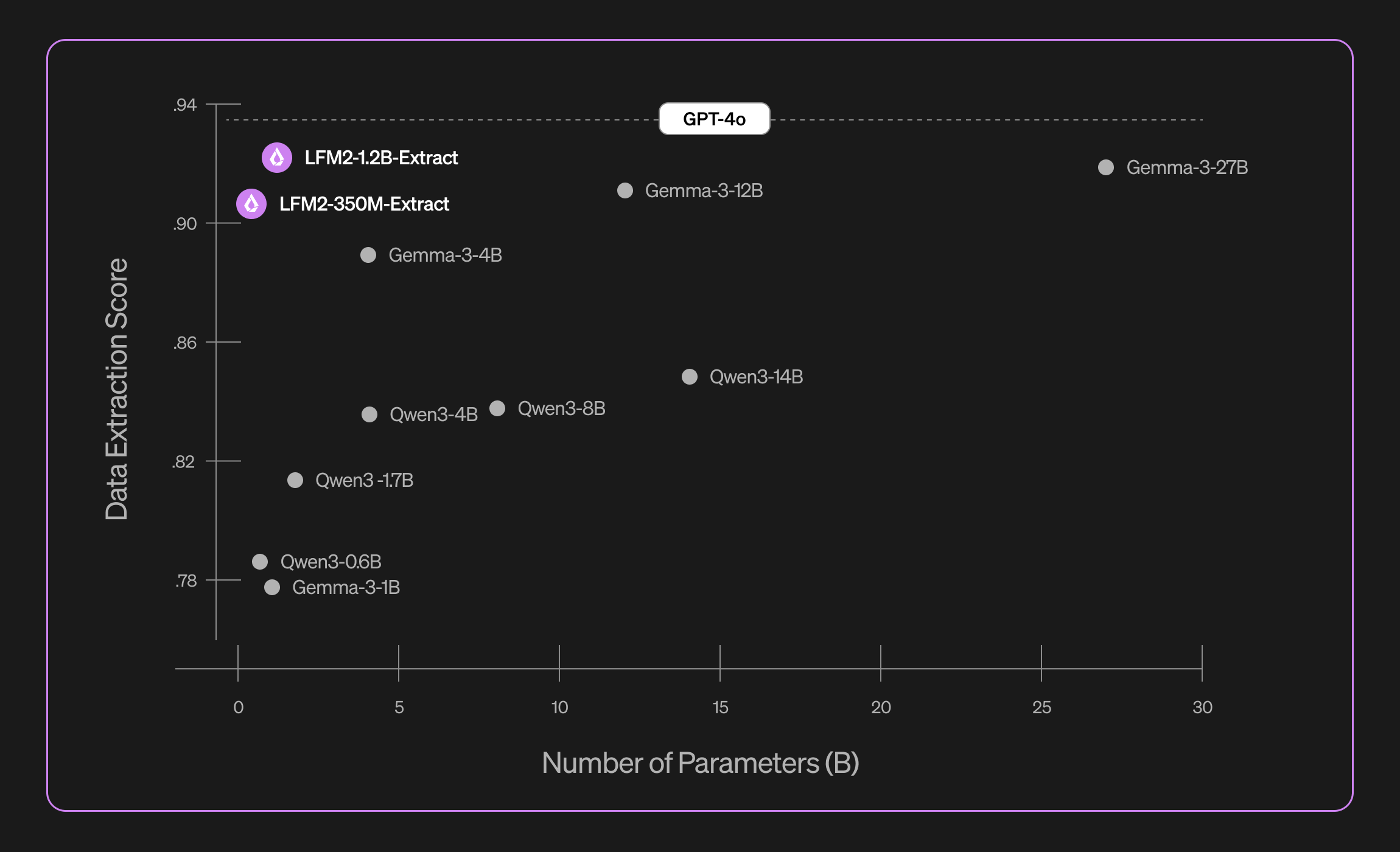
当社のデータ抽出モデルは、有効性、正確性、忠実性を大幅に向上させます。例えば、LFM2-1.2B-Extract は、そのサイズの 22.5 倍である Gemma 3 27B よりも高いレベルで、多言語にわたり複雑なオブジェクトを出力できます。
LFM2-350-ENJP-MT
LFM2-350M-ENJP-MT は、英語と日本語の双方向翻訳用に設計された 3 億 5,000 万パラメータのモデルです。翻訳品質は、サイズが 10 倍以上大きいジェネラリストモデルを上回ります。
ユースケース:
- スマートフォン、タブレット、ラップトップでローカルに実行される、低レイテンシー・低メモリでプライベートかつオフライン動作する翻訳モデル。
- 高スループットの英語 ↔ 日本語翻訳が求められる効率的なエージェントパイプラインの一部。
LFM2-350M-ENJP-MT を使用するには、「英語に翻訳」または「日本語に翻訳」という 2 種類のシステムプロンプトのいずれかと、翻訳対象のテキスト(ユーザープロンプト)を入力する必要があります。
-Lightmode.png)
LFM2-350M-ENJP-MT は、公開されている llm-jp-eval ベンチマークで評価しました。主に、ウィキペディアの 1~2 文の記事や 1 文のニュース記事などの短い翻訳で構成されています。私たちのモデルは、チャットのようなメッセージ、複数段落のニュース記事、技術論文、正式な文章など、はるかに幅広いテキストでトレーニングされています。
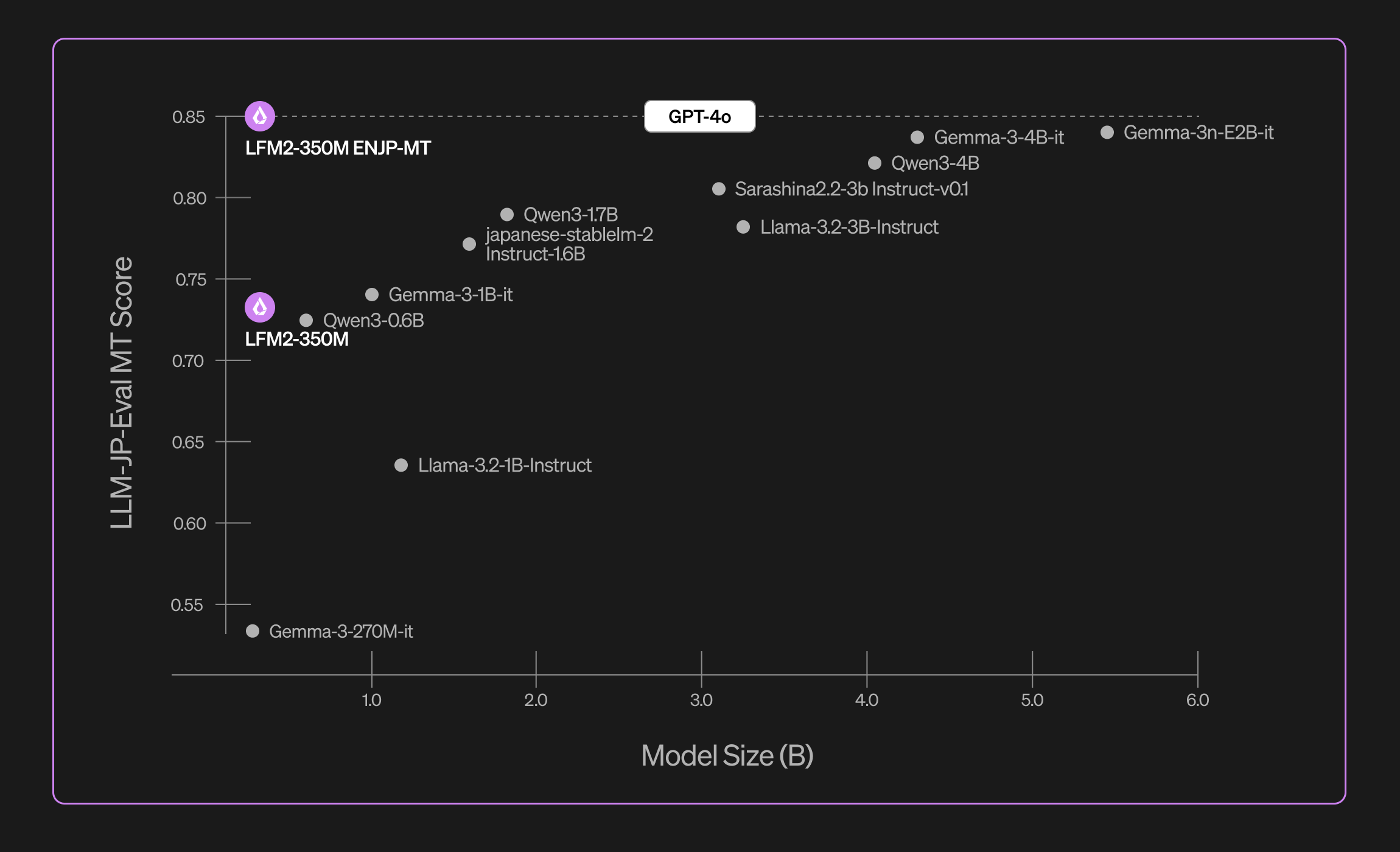
この包括的なトレーニングにより、私たちのモデルは GPT-4o に匹敵する、即戦力の強力な汎用翻訳機能を提供します。
次のリンクからサンプル翻訳を参照してください。
LFM2-1.2B-RAG
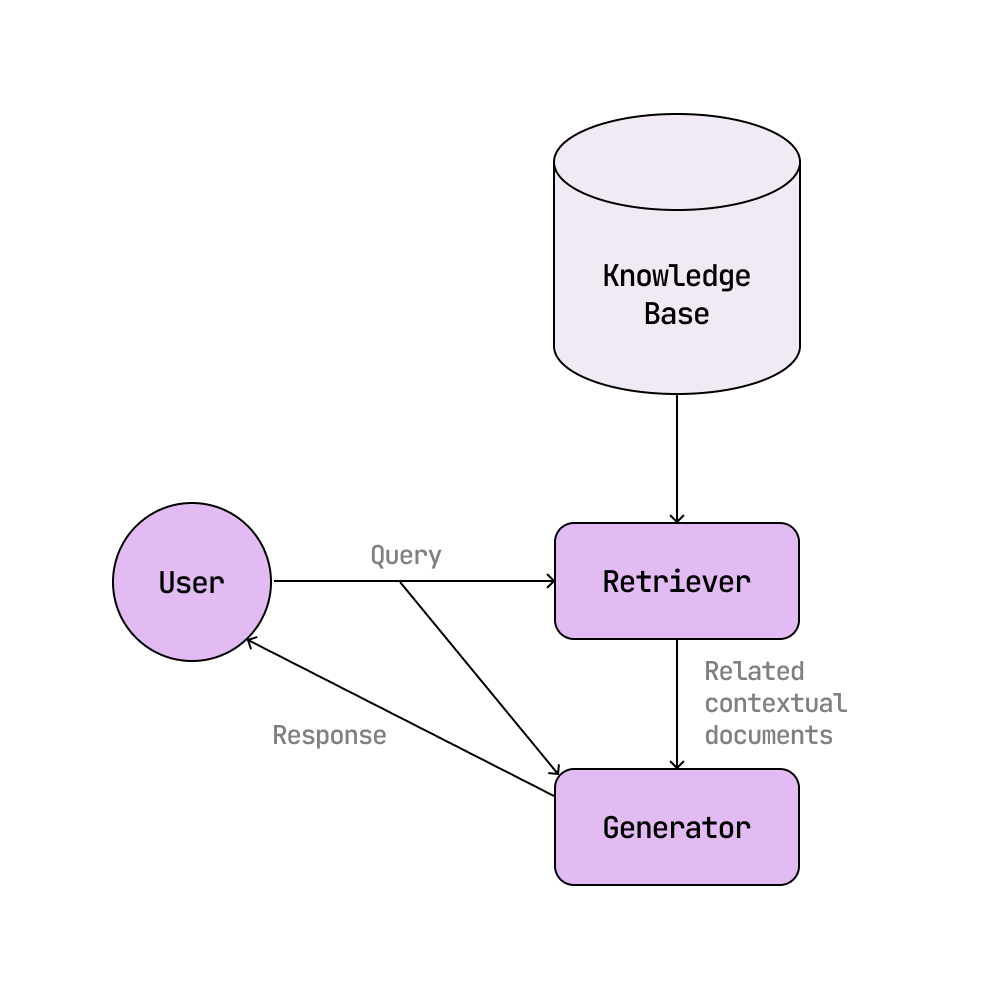
LFM2-1.2B-RAG は、RAG(検索拡張生成)システムで使用するために設計された、提供されたコンテキストドキュメントに基づいて質問に回答することに特化した 12 億パラメータのモデルです。RAG システムにより、AI ソリューションはトレーニングデータに含まれていない新しい情報、最新情報、さらには独占的な情報を LLM の回答に組み込むことができます。ユーザーが質問すると、検索コンポーネントがナレッジベースから関連ドキュメントを取得し、RAG ジェネレーターモデルがそれらのコンテキストドキュメントに基づいて回答します。
_Lightmode.png)
LFM2-1.2B-RAG モデルは、100 万以上のマルチターン対話サンプルと、厳選されたオープンソース文書および生成された合成文書を組み合わせたマルチドキュメントサンプルを含むデータセットで微調整されました。データセットは、アラビア語、中国語、英語、フランス語、ドイツ語、日本語、韓国語、ポルトガル語、スペイン語の 9 言語にわたります。
LLM を用いた評価に基づき、3 つの指標を考慮した内部ベンチマークでモデルを評価し、同規模の 4 つのオープンソースモデルと比較しました。
- グラウンデッド性: 応答は提供されたコンテキスト文書の情報のみに基づいており、幻覚を避けているか。
- 関連性: モデルはユーザーの質問に簡潔かつ適切に答えているか。すべての回答内容が無駄なく最終回答に貢献しているか。
- 有用性: 全体として、このモデルはユーザーの問い合わせにどの程度役立ったか。
LFM2-1.2B-RAG は、Qwen3-1.7B、Gemma3-1B-It、Llama-3.21B-Instruct、Pleias-1B-RAG と比較して、3 つの指標すべてにおいて競争力のある性能を示しました。
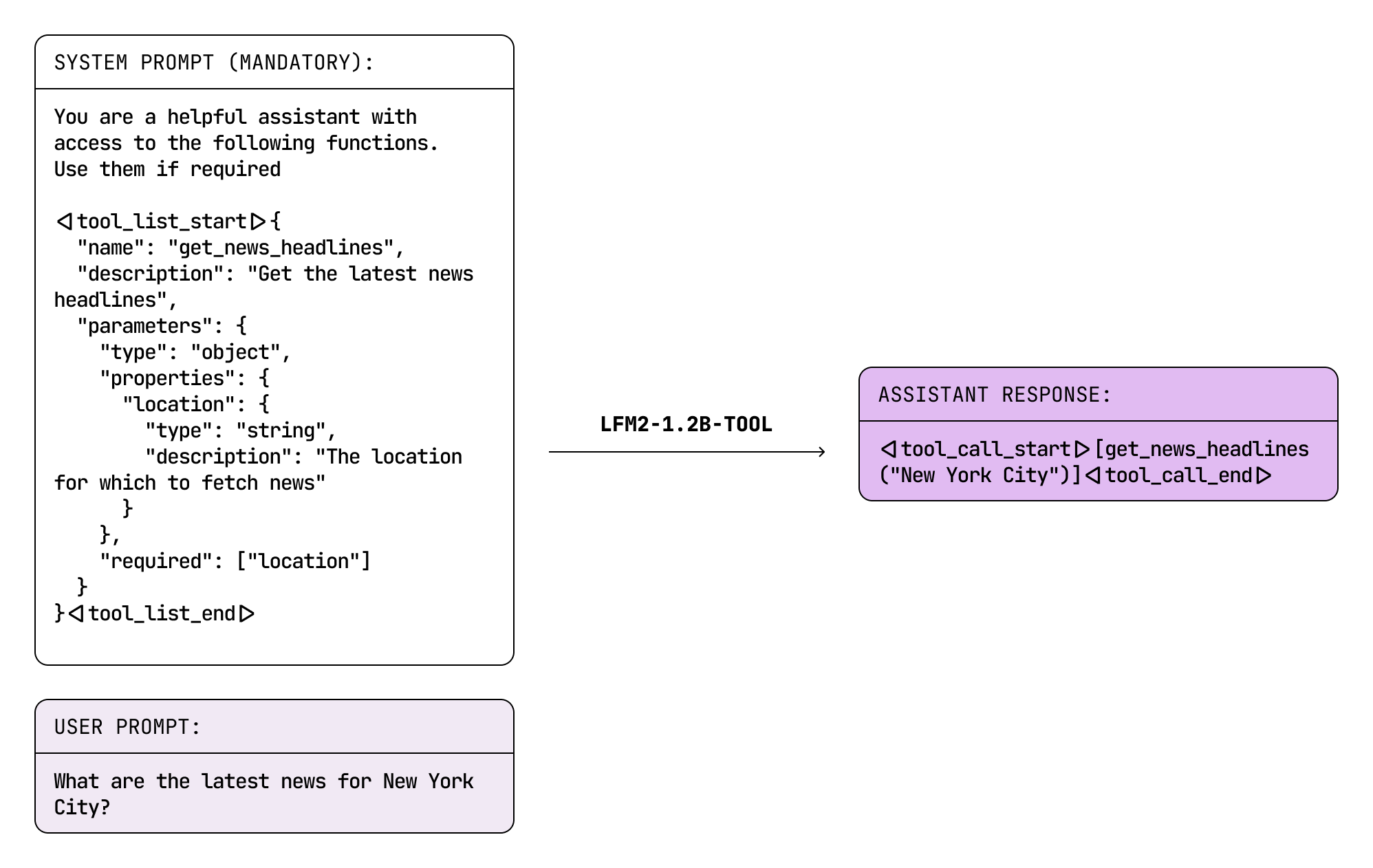
LFM2-1.2B-Tool
LFM2-1.2B-Tool は、簡潔かつ正確なツール呼び出しのために設計されたタスク専用モデルです。主な課題は、同程度のサイズの推論モデルよりも優れた非推論モデルを設計することでした。
ユースケース:
- モバイルデバイスやエッジデバイスで、クラウドに依存しない即時の API 呼び出し、データベースクエリ、またはシステム統合を行う。
- 自動車、IoT デバイス、カスタマーサポートなど、応答遅延が重要となるリアルタイムアシスタント。
- 組み込みシステムやバッテリー駆動デバイスなど、リソース制約のある環境で効率的にツールを実行する。
エッジ推論では、シームレスで満足のいくユーザーエクスペリエンスを提供する上で、遅延は重要な要素です。推論ステップを増やすと精度は向上しますが、関数呼び出しのレイテンシーが長くなり、最終的にはユーザーエクスペリエンスを損ないます。したがって、目標は推論モデルと競合しながらも、社内の思考連鎖プロセスなしで動作するツール呼び出しモデルを開発することでした。
.png)
データ汚染を防ぐために特別に設計した独自のベンチマークで各モデルを評価しました。このベンチマークにより、パフォーマンス指標がトレーニングデータに記憶されたパターンではなく、実際のツール呼び出し能力を反映していることを確認しています。
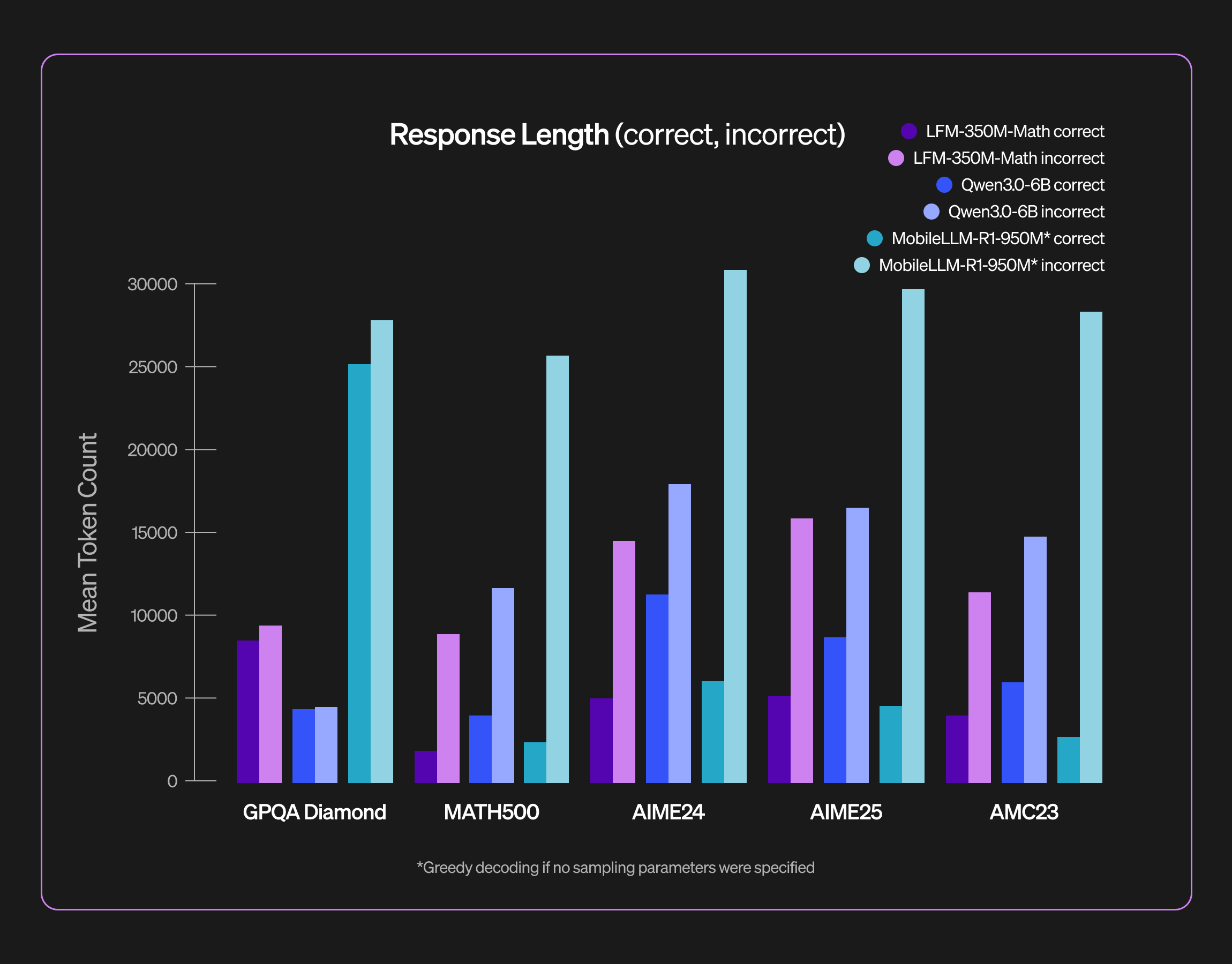
LFM2-350M-Math
当社の LFM2-350M-Math は、難しい数学の問題に取り組むために設計された小さな推論モデルです。推論により、モデルは思考プロセスをより適切に構造化し、複数の解法戦略を模索し、最終的な回答を自己検証することができます。このように小規模なモデルに対してテスト時に大規模な計算資源を投入することで、競技レベルの難しい数学問題も解けるようになります。当社のベンチマーク評価では、LFM2-350M-Math はそのサイズに対して非常に高い能力を備えていることが実証されています。
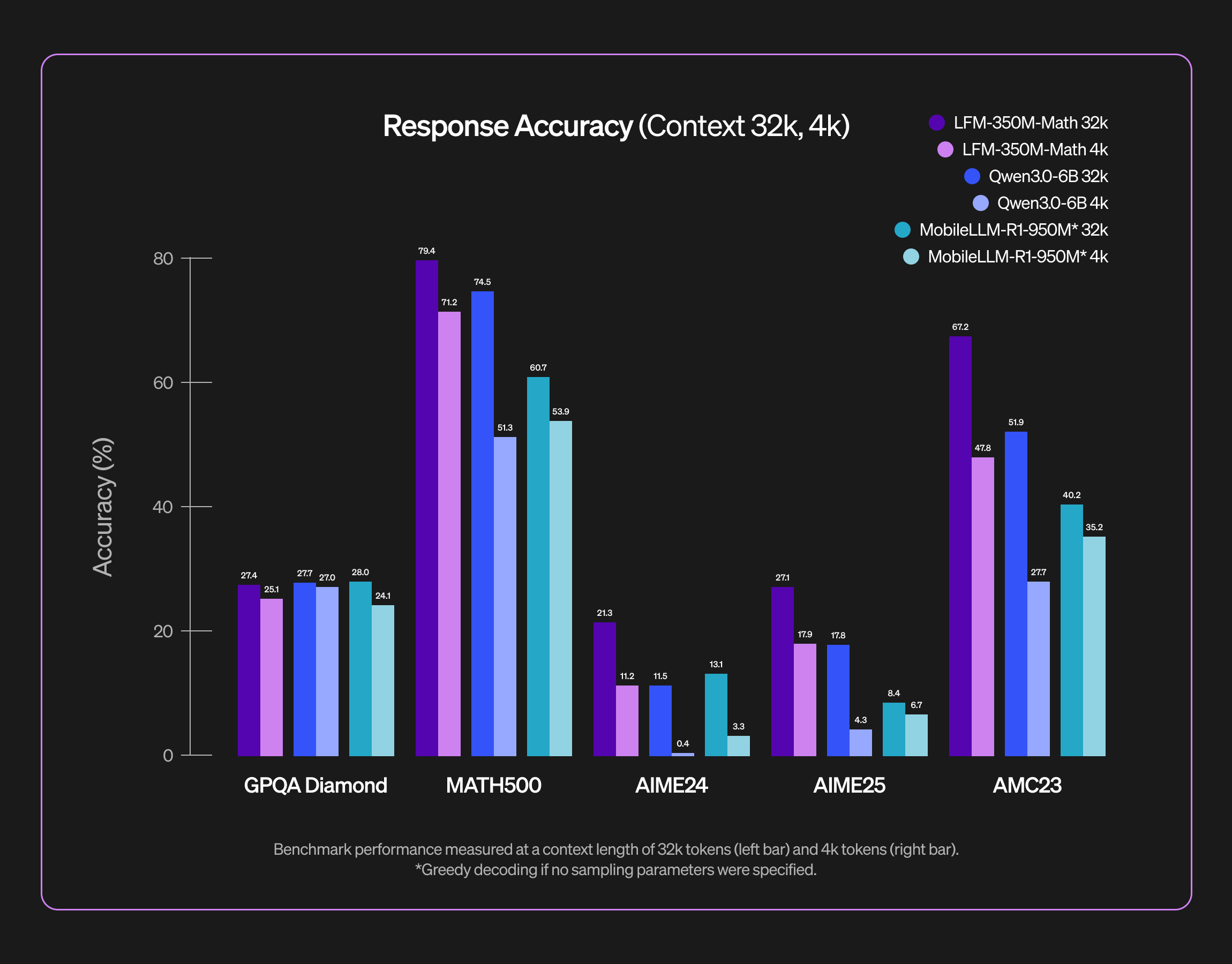
私たちはエッジ環境への展開を重視しているため、目標はメモリ消費とレイテンシを抑えることです。トレーニング後のレシピでは、強化学習を活用し、望ましくない応答の冗長性を明示的に抑制しています。そのために、推論予算 を明示的に設定し、難易度に応じたアドバンテージの再重み付けを組み合わせています。詳細なトレーニング後レシピについては、別のブログ投稿をご参照ください。
Luth-LFM2
また、オープンソースコミュニティによって作成された高品質なモデルにも注目したいと思います。Luth-LFM2-1.2B、Luth-LFM2-700M、Luth-LFM2-350M です。これらは Sinoué Gad 氏と Maxence Lasbordes 氏によって開発され、英語の能力を維持しつつ、特化したフランス語バージョンを提供します。
これらのモデルは、Luth-SFT データセットを用いた完全なファインチューニングによって開発されました。Luth-SFT には、フランスのバカロレア試験および CPGE 試験の数学・物理・科学知識の問題から作成された Scholar データセット が含まれています。
ユースケース:
- モバイルデバイス、タブレット、ラップトップ上でローカルに実行される低遅延のフランス語処理
- データパイプラインや分析システムにおけるフランス語文書の高スループット・バッチ処理
- クラウド接続が制限されるプライバシー重視のアプリケーション向けオフライン・フランス語 AI アシスタント
これらのモデルは、英語能力を維持または強化しながら、フランス語ベンチマークにおいて大幅な性能向上を示しました。たとえば Luth-LFM2-1.2B は、MATH-500-fr のスコアを 35.80 から 47.20 に改善すると同時に、英語の数学パフォーマンスも 44.60 から 50.20 に向上させました。これは、モデル統合による言語特化が、言語間の性能を損なうことなく最先端の成果を達成できることを示しています。

評価プロセスでは LightEval とカスタムのフランス語ベンチマークを使用し、IFEval-fr、GPQA-fr、MMLU-fr、Hellaswag-fr 全体で大幅な改善を達成しつつ、競争力のある英語性能も維持しました。すべてのトレーニングコード、評価スクリプト、そして Luth-SFT データセット(3億3,800万トークン) は GitHub 上で公開されており、フランス語 NLP 研究のさらなる発展に活用できます。
アベイラビリティとライセンス
Liquid Nano は本日より、Liquid Edge AI プラットフォーム (LEAP) 上で iOS、Android、ラップトップ向けに提供されています。開発者はすぐに利用できるほか、SDK を介して統合したり、エージェントに組み込んだりできます。モデルは Hugging Face でも入手可能です。私たちは、研究者、開発者、中小企業向けにオープンライセンスのもとで幅広く利用できるようにしています。すでに複数のフォーチュン500企業と提携し、家電、自動車、eコマース、金融分野向けにタスク特化型のカスタマイズされた Nano を提供しています。
Nano で構築
- LEAP (iOS、Android、デスクトップ) や Hugging Face でモデルを探索・ダウンロードしてください。
- Extract、RAG、Tool モデルをワークフロー内で試してみてください。
- Nano を組み合わせることで、最先端のパフォーマンスとデバイス上での低コスト/低レイテンシーを備えた完全なエージェントシステムを構築できます。