.svg)

We’re launching Liquid Nanos — a family of 350M–2.6B parameter foundation models that deliver frontier‑model quality on specialized, agentic tasks while running directly on phones, laptops, and embedded devices. In our evaluations with partners, Nanos perform competitively with models hundreds of times larger. The result: planet‑scale AI agents with cloud‑free economics.
Why Nanos, and why now? The last few years of AI progress have been powered by ever‑larger models—and ever‑larger data centers. But the real world has constraints: cost, energy, latency, and privacy. Shipping every token to the cloud makes many use cases hard to scale to everyone.
Nanos flip the deployment model. Instead of moving all the data to a frontier model, we ship compact, highly capable intelligence to the device. That unlocks speed, resilience, privacy, and a cost profile that finally scales.
What are Liquid Nanos? Liquid Nanos are low-latency task‑specific Liquid Foundation Models (LFM2 family) that occupy RAM space of 100Mb to 2GB, trained with advanced pre‑training and a specialized form of post‑training to deliver frontier‑grade results on the building blocks of agentic AI:
- Precise data extraction and structured output generation
- Multilingual language understanding
- Retrieval‑augmented generation (RAG) over long contexts
- Math & reasoning
- Tool / function calling for agent workflows
Despite their small footprint (hundreds of millions to ~1B parameters), Nanos match or approach the quality of vastly larger generalist models on the tasks they’re designed for, and they run fully on‑device on modern phones and PCs.
Today, we are releasing the first series of experimental task‑specific Nanos today, with more on the way:
- LFM2-Extract – A 350M and 1.2B multilingual models for data extraction from unstructured text, like turning invoice emails into JSON objects.
- LFM2‑350M‑ENJP‑MT – A 350M model for bidirectional English ↔ Japanese translation.
- LFM2‑1.2B‑RAG – A 1.2B model optimized for long‑context question answering in RAG pipelines.
- LFM2‑1.2B‑Tool – A 1.2B model built for function calling and agentic tool use.
- LFM2‑350M‑Math – A 350M reasoning model for solving mathematical problems.
- Luth-LFM2 – An additional community-driven series of French fine-tunes to enable general-purpose assistants for on-device chat.
Liquid Nanos
Most edge AI applications require models that excel in one particular task, such as translation or function calling. Typically, this requires fine-tuning general-purpose models for a given task. However, fine-tuning remains a challenge for many users due to a lack of time, data, or compute. To address this gap, we created a model library with a collection of task-specific LFM2 models. These specialized checkpoints offer very high-quality outputs with a tiny memory footprint. All the models in this growing library are available on Hugging Face and directly compatible with LEAP and Liquid Apollo.
Deploy with LEAP today

Download Liquid Apollo, now FREE on the App Store and Google Play
While the AI landscape is dominated by a race toward ever-larger models, the practical reality is that small, fine-tuned models can match or exceed the performance of >100B models on specific tasks. These small specialized models unlock AI applications in environments where cost, latency, privacy, and connectivity requirements make cloud models impractical or impossible.
LFM2-Extract
LFM2-350M-Extract and LFM2-1.2B-Extract are designed to extract important information from a wide variety of unstructured documents (such as articles, transcripts, or reports) into structured outputs like JSON, XML, or YAML. They’re compatible with English, Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish inputs.
-Lightmode.png)
Use cases:
- Extracting invoice details from emails into structured JSON.
- Converting regulatory filings into XML for compliance systems.
- Transforming customer support tickets into YAML for analytics pipelines.
- Populating knowledge graphs with entities and attributes from unstructured reports.
Using LFM2-Extract only requires an input document and an optional schema template. We recommend providing this schema template in the system prompt to improve accuracy, especially on documents that are particularly long and complex.
The data used for training these models was primarily synthetic, which allowed us to ensure a diverse data mix. We used a range of document types, domains, styles, lengths, and languages. We also varied the density and distribution of relevant text in the documents. In some cases, the extracted information was clustered in one part of the document; in others, it’s spread throughout. We applied the same approach of ensuring diversity when creating synthetic user requests and designing the structure of the model outputs. The data generation process underwent many iterations, incorporating ideas and feedback from across the Liquid AI team.
We evaluated LFM2-Extract on a dataset of 5,000 documents, covering over 100 topics with a mix of writing styles, ambiguities, and formats. We used a combination of five metrics to capture a balanced view on syntax, accuracy, and faithfulness:
- Syntax score: Checks whether outputs parse cleanly as valid JSON, XML, or YAML.
- Format accuracy: Verifies that outputs match the requested format (e.g., JSON when JSON is requested).
- Keyword faithfulness: Measures whether values in the structured output actually appear in the input text.
- Absolute scoring: A judge LLM scores quality on a 1-5 scale, assessing completeness and correctness of extractions.
- Relative scoring: We ask a judge LLM to choose the best answer between the extraction model’s output and the ground-truth answer.
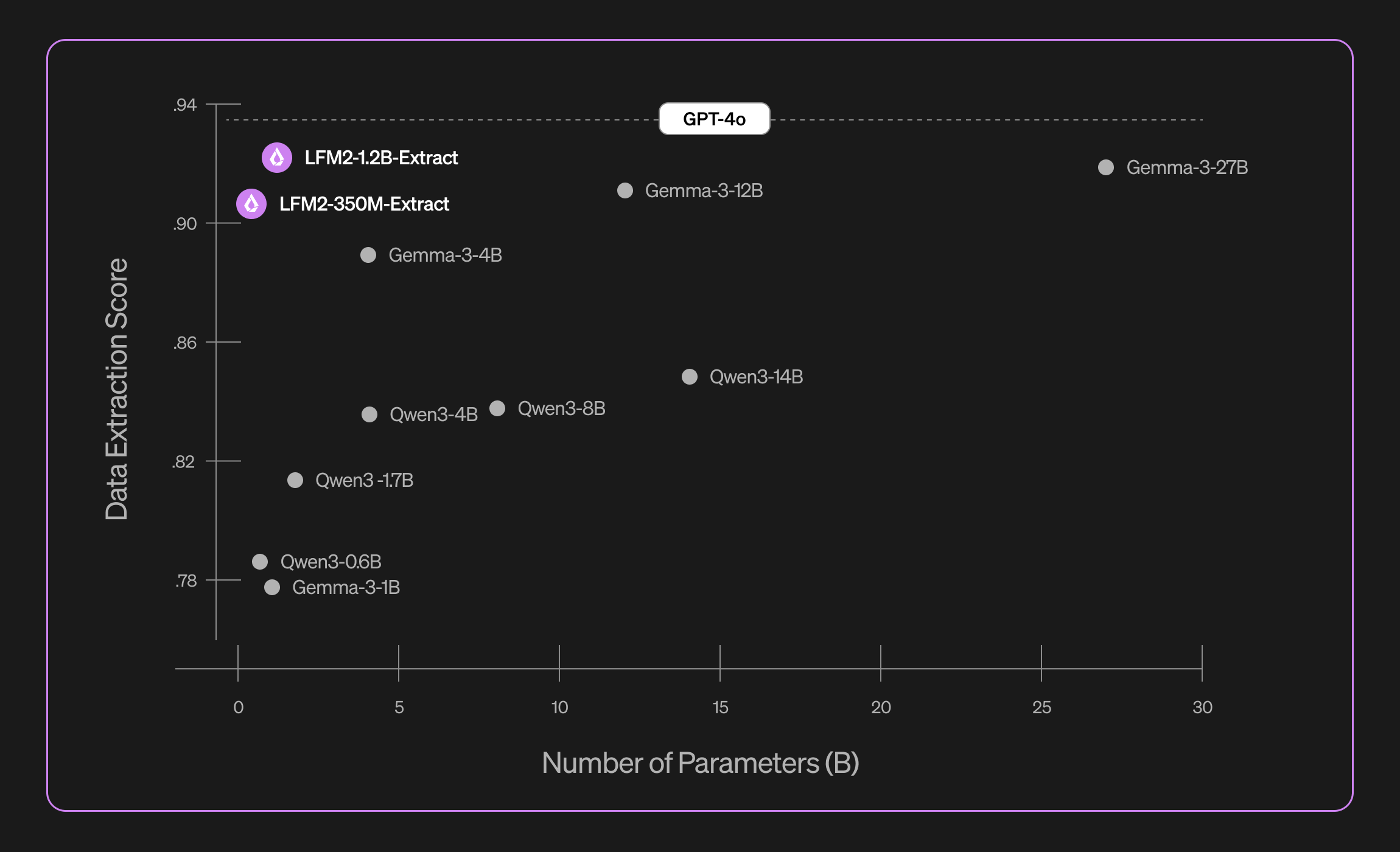
Our data extraction models provide a significant boost in validity, accuracy, and faithfulness. For instance, LFM2-1.2B-Extract can output complex objects in different languages on a level higher than Gemma 3 27B, a model 22.5 times its size.
LFM2-350-ENJP-MT
LFM2-350M-ENJP-MT is a 350M parameter model for bidirectional English/Japanese translation. Its translation quality is superior to that of generalist models more than 10 times its size.
Use cases:
- A low-latency, low-memory, private, and offline translation model running locally on your phone, tablet, or laptop.
- A part of an efficient agentic pipeline that requires high-throughput English ↔ Japanese translation.
Using LFM2-350M-ENJP-MT requires providing one of two system prompts (“Translate to English.” or “Translate to Japanese.”) and the text to translate as a user prompt.
-Lightmode.png)
We evaluated LFM2-350M-ENJP-MT using the public llm-jp-eval benchmark. It primarily consists of short translations like 1-2 sentence articles from Wikipedia and single-sentence news items. Our model has been trained on a much broader range of text, including chat-like messages, multi-paragraph news articles, technical papers, and formal writing.
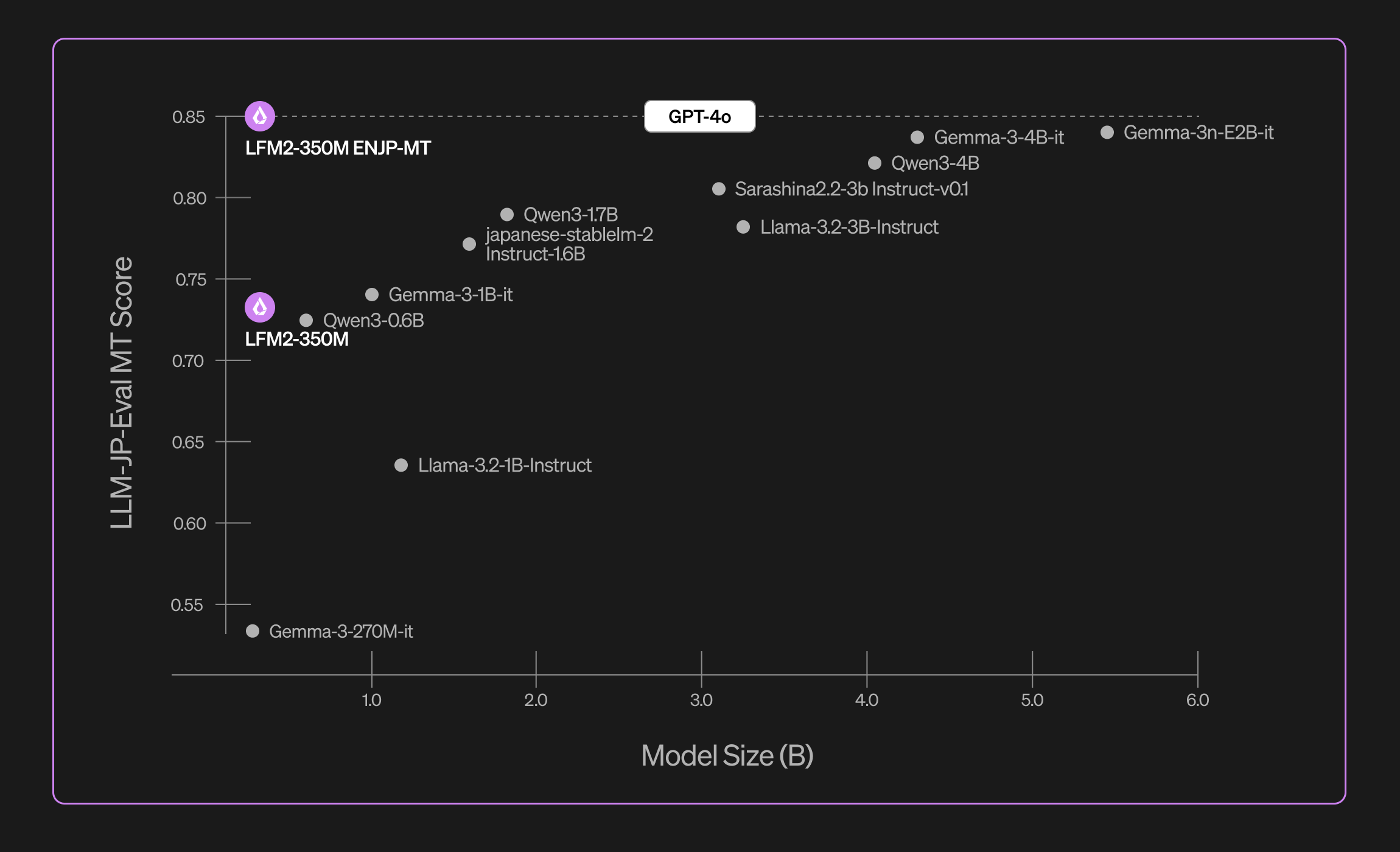
Thanks to this comprehensive training, our model delivers strong out-of-the-box general-purpose translation capabilities competitive against GPT-4o.
See sample translations from the following links:
LFM2-1.2B-RAG
LFM2-1.2B-RAG is a 1.2B model specialized in answering questions based on provided contextual documents, for use in RAG (retrieval augmented generation) systems.
Use cases:
- Chatbot to ask questions about the documentation of a particular product.
- Custom support with an internal knowledge base to provide grounded answers.
- Academic research assistant with multi-turn conversations about research papers and course materials.
RAG systems enable AI solutions to include new, up-to-date, and potentially proprietary information in LLM responses that was not present in the training data. When a user asks a question, the retrieval component locates and delivers related documents from a knowledge base, and then the RAG generator model answers the question based on facts from those contextual documents.
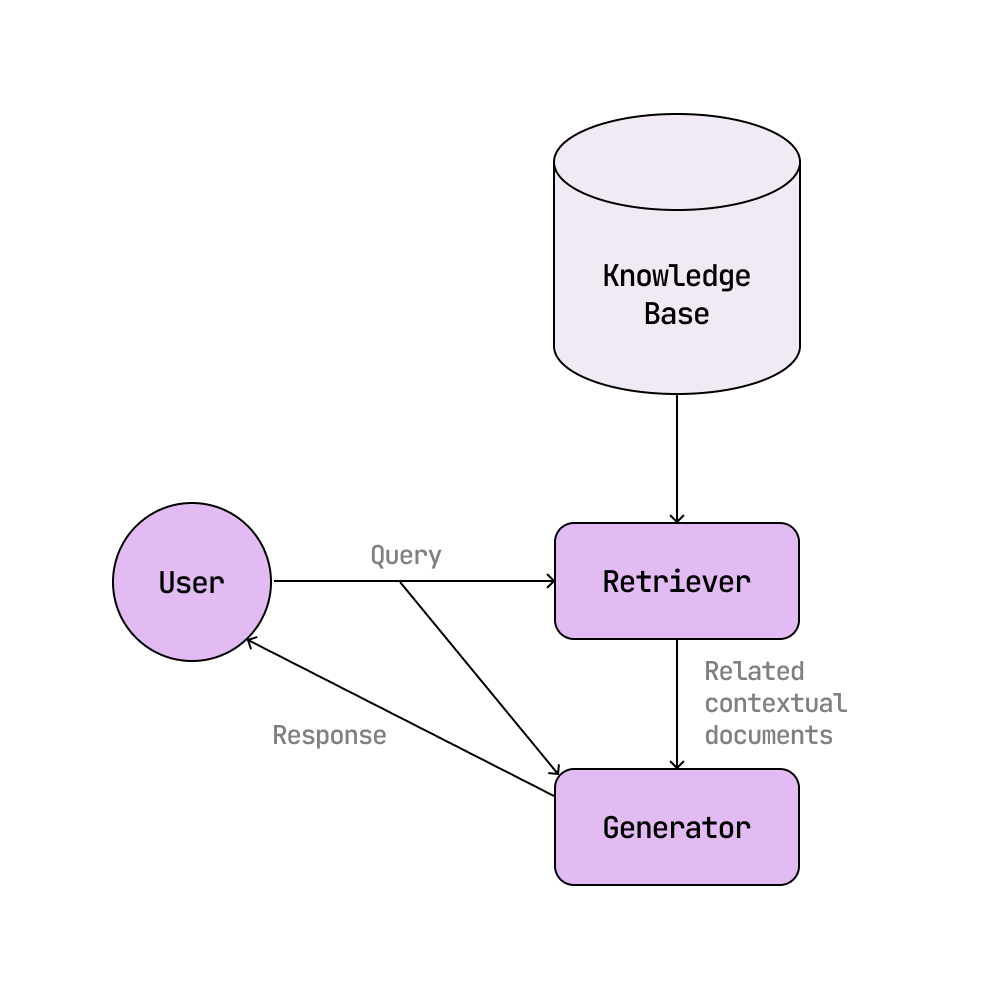
_Lightmode.png)
We fine-tuned the LFM2-1.2B-RAG model on a dataset that includes 1M+ samples of multi-turn interactions and multi-document samples consisting of a mix of curated open source documents as well as generated synthetic ones. The dataset spans 9 different languages: Arabic, Chinese, English, French, German, Japanese, Korean, Portuguese, and Spanish.
We evaluated the model on an internal benchmark that considers 3 metrics using LLMs as a judge, comparing against 4 similarly-sized open-source models:
- Groundedness: Does the model’s responses consist entirely of information from the provided contextual documents and avoid hallucinations?
- Relevance: Does the model answer the user’s question concisely? Does all of the response content contribute to the final answer without inclusion of unnecessary fluff?
- Helpfulness: Overall, how well did the model assist with the user’s query?
LFM2-1.2B-RAG achieves competitive performance in all 3 metrics compared to Qwen3-1.7B, Gemma-3-1B-it, Llama-3.2-1B-Instruct, and Pleias-1B-RAG.
LFM2-1.2B-Tool
LFM2-1.2B-Tool is another task-specific model designed for concise and precise tool calling. The key challenge was designing a non-thinking model that outperforms similarly sized thinking models for tool use.
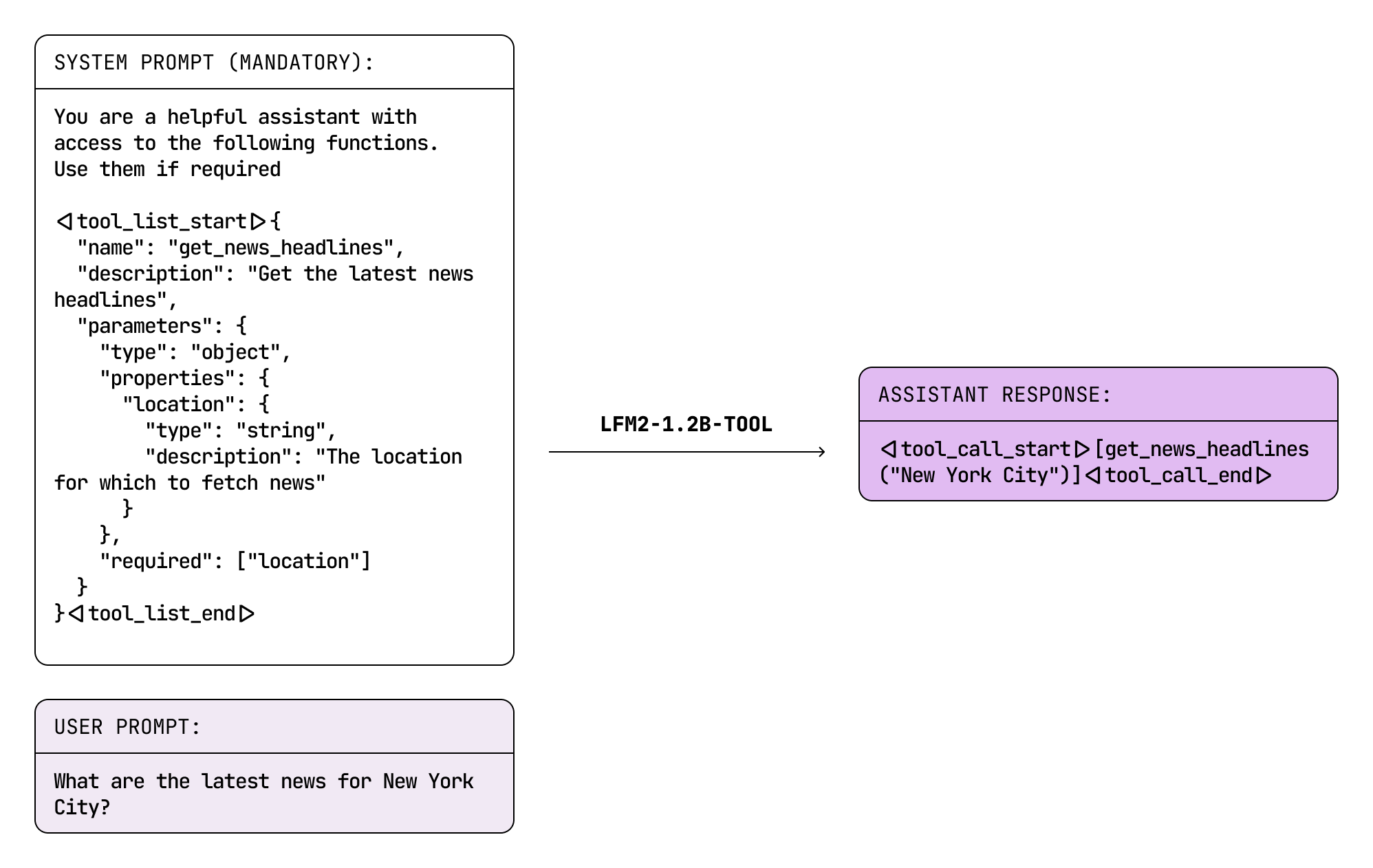
Use cases:
- Mobile and edge devices requiring instant API calls, database queries, or system integrations without cloud dependency.
- Real-time assistants in cars, IoT devices, or customer support, where response latency is critical.
- Resource-constrained environments like embedded systems or battery-powered devices needing efficient tool execution.
For edge inference, latency is a crucial factor in delivering a seamless and satisfactory user experience. Consequently, while test-time-compute inherently provides more accuracy, it ultimately compromises the user experience due to increased waiting times for function calls. Therefore, the goal was to develop a tool calling model that is competitive with thinking models, yet operates without any internal chain-of-thought process.
.png)
We evaluated each model on a proprietary benchmark that was specifically designed to prevent data contamination. The benchmark ensures that performance metrics reflect genuine tool-calling capabilities rather than memorized patterns from training data.
LFM2-350M-Math
Our LFM2-350M-Math is a tiny reasoning model designed for tackling tricky math problems. Reasoning enables models to better structure their thought-process, explore multiple solution strategies and self-verify their final responses. Augmenting tiny models with extensive test-time compute in this way allows them to even solve challenging competition-level math problems. Our benchmark evaluations demonstrate that LFM2-350M-Math is highly capable for its size.
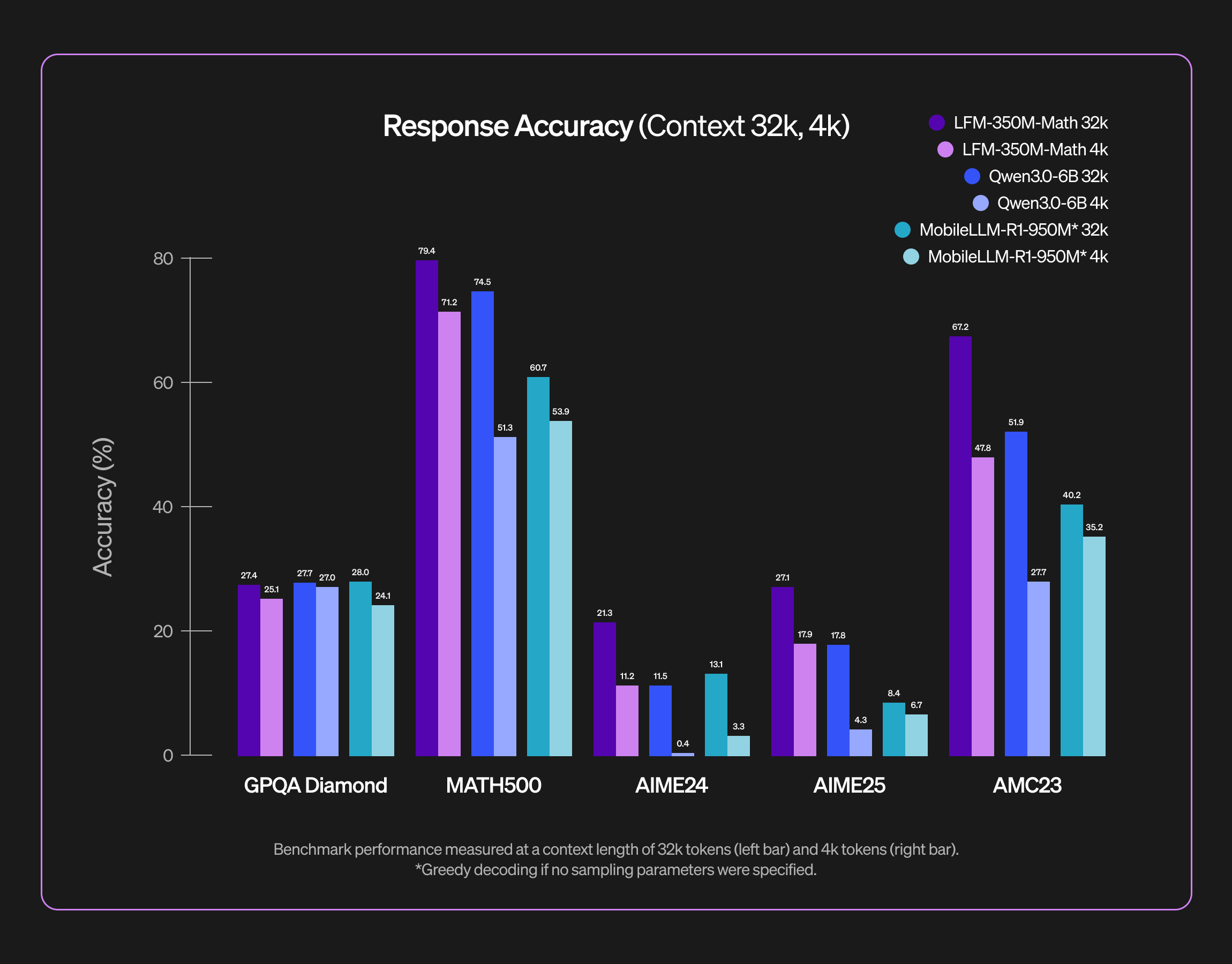
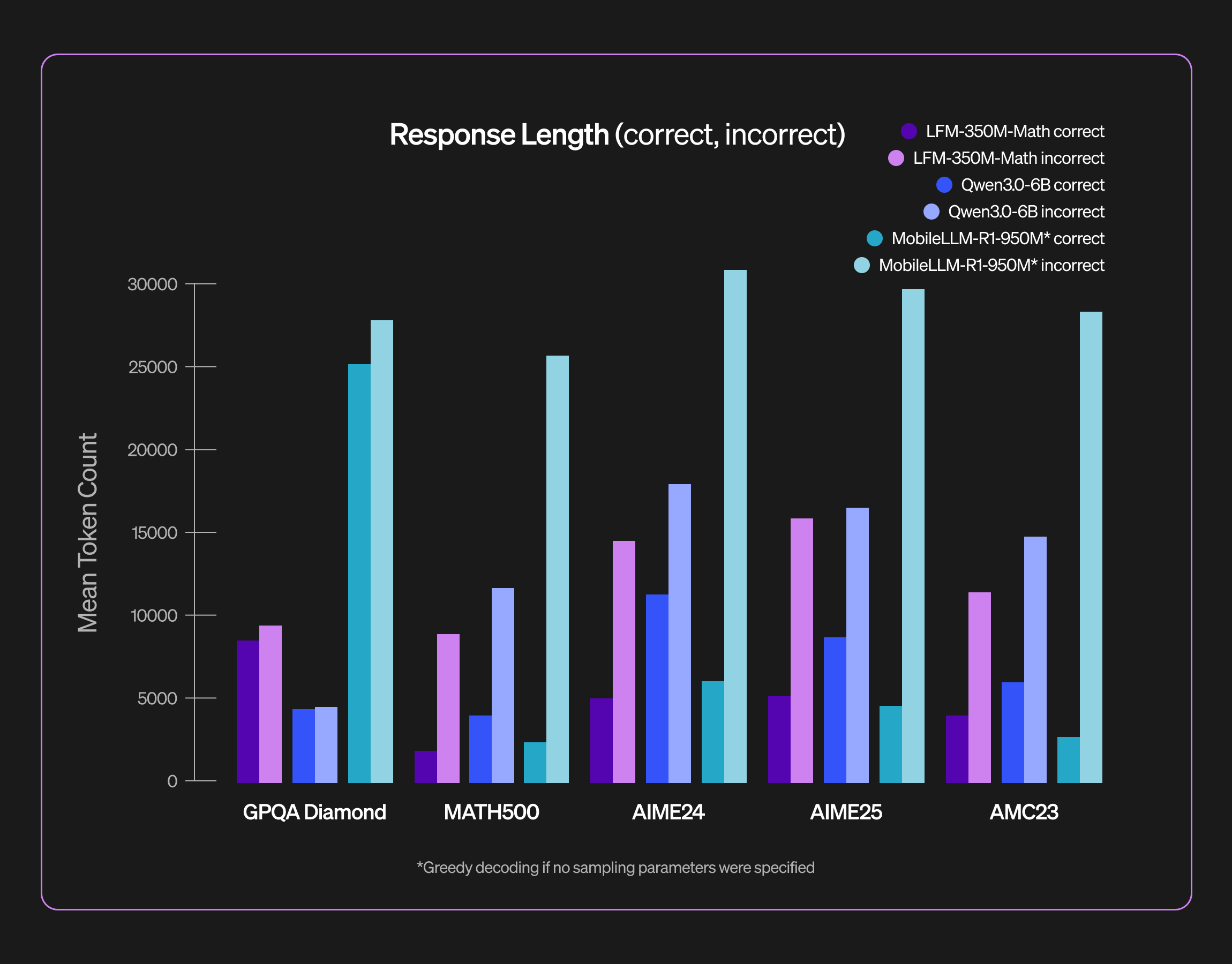
As we are excited about edge deployment, our goal is to limit memory consumption and latency. Our post-training recipe leverages reinforcement learning to explicitly bring down response verbosity where it is not desirable. To this end, we combine explicit reasoning budgets with difficulty-aware advantage re-weighting. Please refer to our separate blog post for a detailed post-training recipe.
Luth-LFM2
We also want to highlight high-quality models made by the open-source community with Luth-LFM2-1.2B, Luth-LFM2-700M, and Luth-LFM2-350M. Developed by Sinoué Gad and Maxence Lasbordes, these fine-tunes provide specialized French versions that maintain English capabilities.
These models were developed through full fine-tuning on the Luth-SFT dataset, which includes the Scholar dataset created from French Baccalauréat and CPGE exam questions covering mathematics, physics, and scientific knowledge.
Use cases:
- Low-latency French language processing running locally on mobile devices, tablets, or laptops
- High-throughput batch processing of French documents in data pipelines and analytics systems
- Offline French AI assistants for privacy-sensitive applications where cloud connectivity is restricted
The models demonstrate remarkable performance improvements on French benchmarks while maintaining or enhancing English capabilities. For example, Luth-LFM2-1.2B improved MATH-500-fr scores from 35.80 to 47.20 while also boosting English math performance from 44.60 to 50.20. This confirms that targeted language specialization through model merging can achieve state-of-the-art results without compromising cross-lingual performance.

The evaluation process used LightEval with custom French benchmark tasks, demonstrating significant gains across IFEval-fr, GPQA-fr, MMLU-fr, and Hellaswag-fr while preserving competitive English performance. All training code, evaluation scripts, and the Luth-SFT dataset (338 million tokens) are openly available on GitHub to support further French NLP research.
Availability & licensing
Liquid Nanos are available today on the Liquid Edge AI platform (LEAP) for iOS, Android, and laptops. Developers can use them out of the box, integrate via SDKs, or compose them into agents. Models are also available on Hugging Face. We’re making them broadly accessible under an open license for academics, developers, and small businesses. We’re already partnering with multiple Fortune 500s to deliver customized task‑specific Nanos across consumer electronics, automotive, e‑commerce, and finance.
Build with Nanos
- Explore and download models on LEAP (iOS, Android, and desktop) and Hugging Face.
- Try the Extract, RAG, and Tool models in your workflow.
- Combine Nanos to compose full agent systems with frontier‑grade performance and on‑device cost/latency.