
LFM-1B-Math: Can Small Models Be Concise Reasoners?
Takeaways
- We show a principled post-training recipe for augmenting small chat models with mathematical reasoning capabilities, based on a 1.3B Liquid Foundation Model (LFM).
- Extensive supervised fine-tuning on curated chain-of-thought data unlocks strong reasoning, while targeted reinforcement learning makes reasoning chains concise.
- The resulting model, LFM-1.3B-Math, enables strong performance on a limited response budget, an ideal trade-off for resource-constrained deployment onto edge devices.
Reasoning models have popularized new training paradigms based on chains of thought and reinforcement learning (RL) to solve complex problems. This allows even small models to perform tasks that would typically require much larger LLMs. However, most of the scientific literature focuses on a limited set of base models, making it difficult to disentangle the effectiveness of reasoning recipes from inherent model characteristics, like pre-training data or architecture.
In this blog post, we share insights based on our exploration of reasoning recipes for small language models, with the example of LFM-1.3B [1]. We demonstrate how a general chat model, without any math-specific pre-training, can acquire concise reasoning abilities through a combination of extensive fine-tuning and short-horizon reinforcement learning. By sharing our findings with our model, pre-training mix, and architecture, we aim to broaden the understanding of how to effectively instill reasoning abilities into small language models suitable for edge deployment.
Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) is a popular approach to augment traditional models with the ability to leverage reasoning behaviors by training on curated Chain-of-Thought (CoT) traces [2]. Offline distillation-style SFT from a strong teacher model is particularly effective for small reasoning models, where pure reinforcement learning tends to be more challenging.
Instruction data mixture
While recent studies suggest effective training with as few as 1k samples [3], we find that leveraging large-scale open-source datasets (over 1M samples) yields particularly strong performance. We speculate that findings related to highly constrained data regimes may correlate with model size and math- or reasoning-specific pre-training data (see also [4]).
This observation aligns with the practices of similar strong, small reasoning models. For example, DeepSeek-R1-Distill-Qwen-1.5B [2] was trained on approximately 1M samples, with Nvidia’s OpenMath-Nemotron-1.5B [5] further training this model on an additional 3M samples.
We found Nvidia’s OpenMathReasoning [5] and Llama Nemotron Post-Training [6] datasets particularly effective among other openly available datasets, including Hugging Face’s Open-R1 [7] and Bespoke Lab’s OpenThoughts (e.g., OpenThoughts2-1M) [8]. We selected OpenMathReasoning, which we found to yield strong empirical results on math problems, and combined it with the science subset of Llama Nemotron Post-Training and SCP-116K [9] to enable applicability to science problems. This resulted in a total of around 4.5M samples.
Dataset | Category | # Samples |
|---|---|---|
nvidia/OpenMathReasoning [5] | Math | 3.2M (72%) |
nvidia/Llama-Nemotron-Post-Training-Dataset (Science) [6] | Science | 709k (16%) |
EricLu/SCP-116K [9] | Science + Math | 2 × 274k (12%) |
Table 1. Composition of the instruction dataset.
Hyperparameters
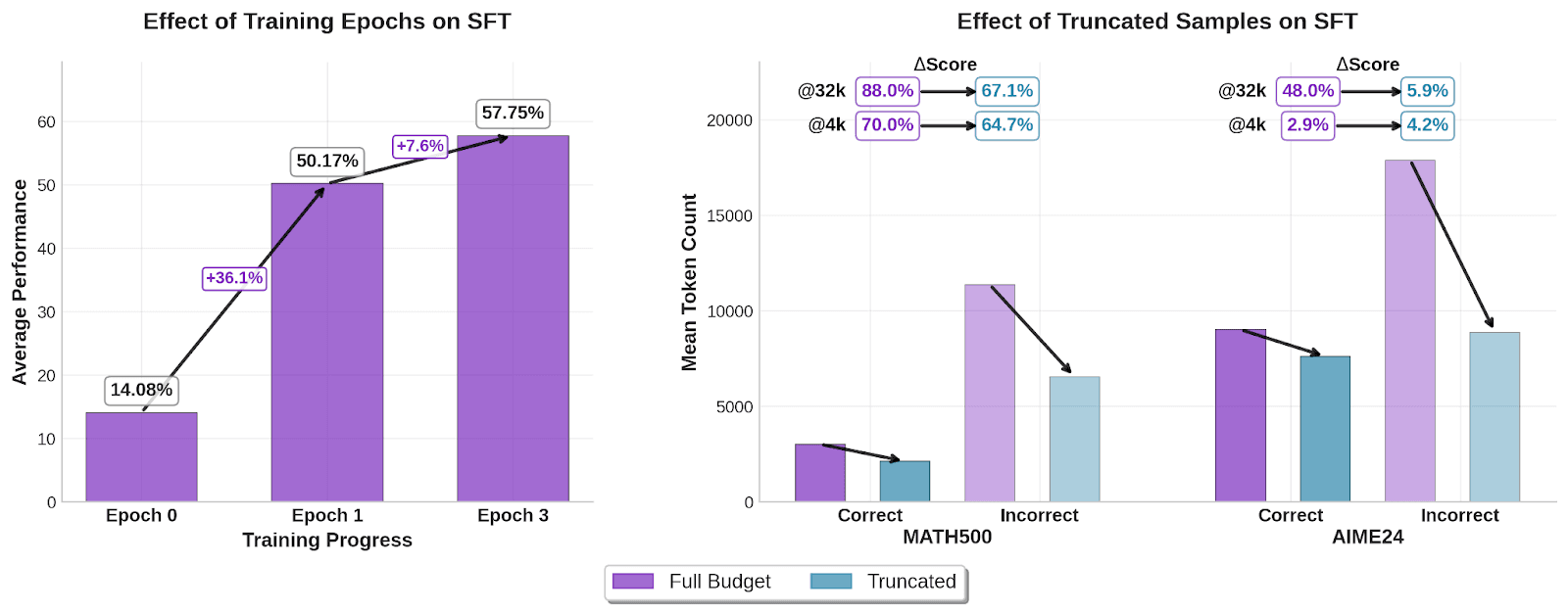
To fully leverage the benefit of these large, high-quality datasets, we deviated significantly from our usual post-training recipe. Specifically, we employed a relatively high learning rate of 3e-4 and trained for a total of 3 epochs, translating to approximately 100 billion tokens. These aggressive hyperparameter choices were crucial for extracting the most knowledge out of these large datasets, which are inherently harder to fully compress and overfit on. Figure 1 (left) highlights the cumulative benefit of multi-epoch training, where the first epoch increased average performance by 36%, with the following two epochs contributing an additional 7.6%.
Response verbosity
Reasoning enables models to explore multiple solution strategies sequentially, correcting potential mistakes and self-verifying final answers. While this can significantly improve solution accuracy, responses naturally become longer and may exhibit verbosity that is not entirely goal-directed. This is incompatible with most edge applications, where both memory and generation speed are limiting factors.
We explored several ways to shorten response length through SFT alone, including:
- Removing the top 20% longest samples, filtering approximately 50% of the total tokens
- Post-hoc conditioning responses via system prompts, e.g., "thinking: {low; medium; high}"
- Truncating reasoning traces to ensure the entire response remained within 3k tokens
In the latter case, we were curious whether training on truncated reasoning traces could provide sufficient information to improve performance when evaluating on a constrained budget of 4k response tokens. As highlighted in Figure 1 (right), training on truncated reasoning traces successfully shortened the resulting response length. However, it did not increase performance when evaluating on the constrained response budget at 4k tokens, while reducing performance on the unconstrained budget at 32k tokens. We therefore observe no benefit over directly constraining the length of generation of the original model.
Reinforcement Learning
We find that SFT is insufficient to shorten reasoning without significantly sacrificing performance. Instead, we leverage RL to refine our model towards concise reasoning behavior. We base our approach on Group Relative Policy Optimization (GRPO) [10], as its combination of Monte Carlo advantage estimation with verifiable outcome rewards yields a straightforward optimization objective. To further improve training stability, we remove advantage normalization and apply overlong filtering [11,12]. We note the similarity of GRPO, RLOO [13], and REINFORCE [14] under these modifications, adopting GRPO for consistency.
Controlling verbosity with RL
A common first step towards reducing model verbosity is to introduce dedicated reward terms based on a priori defined length heuristics. This can hinder the ability to adjust the reasoning budget in the presence of diverse problem complexity. Small models, in particular, are limited in their zero-shot capabilities and may need several explorative attempts before solving hard questions. However, we still want to regularize our responses towards conciseness. Here, we follow a difficulty-aware reward formulation and advantage re-weighting based on GRPO-LEAD [15] to improve alignment between chain-of-thought length and problem complexity.
In the following, we denote the state by s, action by a, and reward by r, where we sample G responses per prompt and define individual generations ai to consist of token-level actions ai,ₜ. The outcome reward is then defined via a length-aware exponential scaling as
where μG and σG denote the group mean and standard deviation of the correct response lengths.
Our objective function then follows the advantage re-weighted formulation of [15] within a simple policy-gradient setting that leverages single on-policy updates without KL regularization,
where sg() denotes the stop-gradient operator, and the advantage Ai is weighted based on
Here, ρG represents the ratio of correct responses for group G associated with sample i.
To avoid extensive filtering of overlong responses, we set an explicit reasoning budget before forcing generation of the final response as adopted by Elastic Reasoning in [16]. After successful fine-tuning on non-truncated reasoning traces, we observe that truncated reasoning traces often contain sufficient signal to enhance final response quality during the RL stage. The resulting samples consist of a prompt, a reasoning trace, and a final answer, such that
where the reasoning trace may be partial and the final answer may not have terminated.
RL data mixture
Our dataset combines samples from several common open-source datasets. Generally, we did not find performance to strongly depend on precise data mixtures beyond balancing problem difficulty. To ensure sufficient learning signal for GRPO, we evaluate empirical solve-rates based on an SFT checkpoint, with our final mixture only containing samples that yield a solve-rate of 20-80% at 4096 token generation budget. We further randomly sub-sample large datasets to arrive at a mixture of 11,373 samples with the following distribution:
Dataset | Category | # Samples |
|---|---|---|
BytedTsinghua-SIA/DAPO-Math-17k [12] | Math | 3,537 (31%) |
nvidia/OpenMathReasoning [5] | Math | 3,183 (28%) |
openai/gsm8k [17] | Math | 1,864 (16%) |
nvidia/Llama-Nemotron-Post-Training-Dataset (Science) [6] | Science | 1,339 (12%) |
EleutherAI/hendrycks_math [18] | Math | 848 (8%) |
agentica-org/DeepScaleR-Preview-Dataset [19] | Math | 602 (5%) |
Table 2. Composition of the reinforcement learning dataset.
Hyperparameters
We sample batches of 128 prompts, for which we generate 13 responses at temperature 1.0 with a context length of 4096 tokens and a final response budget of 1024 tokens. We utilize the AdamW optimizer with a constant learning rate of 5e-6 and do not apply KL regularization. We apply the GRPO-LEAD parameters: α = 0.05, k1 = 0.4, k2 = 1.1, k3 = 10, and ρ0 = 0.75.
Evaluation
To assess the performance of our reasoning checkpoints, we evaluated them on standard reasoning benchmarks, including GPQA Diamond, MATH500, AIME24, AIME25, and AMC23. While GPQA Diamond contains diverse questions about biology, physics, and chemistry, the other benchmarks are focused on math. We consider two distinct response budgets, the full 32k tokens and an edge-constrained 4k token setting.
Table 3 shows the performance of LFM-1.3B checkpoints and other small reasoning models with a 32k output token budget. Note that DeepSeek-R1-Distill-Qwen-1.5B was supervised fine-tuned on long CoTs based on Qwen2.5-Math [20], a model specifically pre-trained on math data. Despite no math-specific pre-training, LFM-1.3B-Math is competitive with these small reasoning models. In particular, we observe that SFT on long CoTs significantly improves the average performance from 14.08% to 59.87% for LFM-1.3B-Distill to yield competitive performance across all benchmarks, including strong results on the challenging AIME subset.
Small reasoning models are particularly suitable for edge applications, where overly long response length can negatively impact user experience due to visibility or compute constraints (e.g., scrolling on a smartphone). An ideal model will aptly align response length with problem difficulty, providing strong performance at the full token budget at low average response length.
We therefore consider a constrained setting in Table 4, where response length is limited to 4k tokens. Here, we observe considerable performance degradation for the majority of models, indicating pronounced reliance on long CoT reasoning. To mitigate this behavior, we leverage length-constrained reinforcement learning to create LFM-1.3B-Math. The resulting model significantly improves performance in the constrained setting from 30.9% to 46.98% (Table 4), with only a small drop in unconstrained average performance (Table 3). We further observe large reduction in verbosity as highlighted by the lower average response lengths in Figure 2. LFM-1.3B-Math therefore positions itself as a strong edge model capable of solving complex science and math problems, while carefully adjusting response length to problem complexity.
Model | Method | Average | GPQA-D | MATH500 | AIME24 | AIME25 | AMC23 |
|---|---|---|---|---|---|---|---|
Qwen3-1.7B (reasoning on) | SFT [21] | 59.02 | 39.86 | 89.56 | 46.15 | 35.31 | 84.22 |
↳ e3-1.7B | RL [22] | 60.28 | 41.29 | 89.91 | 46.98 | 36.25 | 86.95 |
DeepSeek-R1-Distill-Qwen-1.5B | SFT [2] | 47.67 | 33.31 | 82.61 | 28.65 | 22.70 | 71.09 |
↳ OpenMath-Nemotron-1.5B | SFT [5] | 62.79 | 25.58 | 89.76 | 59.27 | 50.93 | 88.43 |
↳ Nemotron-Research-Reasoning | RL [23] | 59.28 | 39.78 | 90.67 | 46.25 | 36.66 | 83.04 |
↳ DeepScaleR-Preview | RL [19] | 54.16 | 34.48 | 87.3 | 38.12 | 28.95 | 81.95 |
↳ E1-Math | RL [16] | 51.60 | 34.12 | 85.26 | 34.58 | 25.93 | 78.12 |
LFM-1.3B | DPO [1] | 14.08 | 27.47 | 28.91 | 0.20 | 0.0 | 13.82 |
↳ LFM-1.3B-Distill | SFT | 59.87 | 39.29 | 87.48 | 51.04 | 36.25 | 85.31 |
↳ LFM-1.3B-Math | RL | 56.93 | 39.05 | 84.31 | 45.21 | 34.06 | 82.03 |
Table 3. Comparison of performance on reasoning benchmarks with a 32k output token budget. We generate 32 independent runs via sampling and report average results to estimate pass@1.
Model | Method | Average | GPQA-D | MATH500 | AIME24 | AIME25 | AMC23 |
|---|---|---|---|---|---|---|---|
Qwen3-1.7B (reasoning on) | SFT [21] | 23.41 | 32.22 | 52.86 | 0.52 | 3.23 | 28.20 |
↳ e3-1.7B | RL [22] | 28.28 | 32.80 | 62.98 | 2.71 | 2.60 | 40.31 |
DeepSeek-R1-Distill-Qwen-1.5B | SFT [2] | 30.21 | 30.41 | 62.83 | 7.71 | 10.20 | 39.92 |
↳ OpenMath-Nemotron-1.5B | SFT [5] | 30.37 | 25.50 | 66.76 | 3.12 | 14.58 | 41.87 |
↳ Nemotron-Research-Reasoning | RL [23] | 27.73 | 29.48 | 53.39 | 4.68 | 3.75 | 27.34 |
↳ DeepScaleR-Preview | RL [19] | 37.74 | 30.47 | 73.99 | 13.12 | 16.77 | 54.37 |
↳ E1-Math | RL [16] | 46.94 | 33.77 | 82.15 | 25.10 | 22.08 | 71.64 |
LFM-1.3B | DPO [1] | 14.10 | 27.52 | 28.90 | 0.20 | 0.0 | 13.82 |
↳ LFM-1.3B-Distill | SFT | 30.09 | 11.42 | 69.80 | 8.03 | 15.73 | 45.46 |
↳ LFM-1.3B-Math | RL | 46.98 | 33.71 | 79.46 | 27.71 | 25.21 | 68.83 |
Table 4. Comparison of performance on reasoning benchmarks with a 4k output token budget. We generate 32 independent runs via sampling and report average results to estimate pass@1.
Conclusion
LFM-1.3B-Math demonstrates that small language models can achieve competitive reasoning performance without relying on math-specific pre-training. Through careful application of large-scale supervised fine-tuning and targeted reinforcement learning, we successfully transformed a general 1.3B parameter model into a capable reasoner that is competitive with specialized alternatives. Here, extensive SFT on curated chain-of-thought data unlocks strong reasoning, while short-horizon RL ensures reasoning chains remain concise.
The resulting combination of aggressive training hyperparameters, difficulty-aware reward formulation, and explicit reasoning budgets proved essential for enabling strong performance on limited response budgets—an ideal trade-off for resource-constrained deployment onto edge devices. We speculate that reasoning capabilities observed in larger models are not solely dependent on scale or domain-specific training data, but can be effectively unlocked through thoughtful training recipes.
References
- [1] Liquid AI. “Liquid Foundation Models: Our First Series of Generative AI Models.” https://www.liquid.ai/blog/liquid-foundation-models-our-first-series-of-generative-ai-models (2024)
- [2] DeepSeek-AI et al. "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." arXiv preprint arXiv:2501.12948 (2025).
- [3] Niklas Muennighoff et al. "s1: Simple test-time scaling." arXiv preprint arXiv:2501.19393 (2025).
- [4] Kanishk Gandhi et al. "Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs." arXiv preprint arXiv:2503.01307v1 (2025).
- [5] Ivan Moshkov et al. "AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset." arXiv preprint arXiv:2504.16891 (2025).
- [6] Akhiad Bercovich et al. "Llama-Nemotron: Efficient Reasoning Models." arXiv preprint arXiv:2505.00949 (2025). https://arxiv.org/abs/2505.00949.
- [7] Hugging Face. "GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1." 2025, https://github.com/huggingface/open-r1.
- [8] Etash Guha et al. "OpenThoughts: Data Recipes for Reasoning Models." arXiv preprint arXiv:2506.04178 (2025).
- [9] Dakuan Lu et al. "SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain." arXiv preprint arXiv:2501.15587 (2025). https://arxiv.org/abs/2501.15587.
- [10] Zhihong Shao et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models." arXiv preprint arXiv:2402.03300 (2024).
- [11] Zichen Liu et al. "Understanding r1-zero-like training: A critical perspective." arXiv preprint arXiv:2503.20783 (2025).
- [12] Qiying Yu et al. "Dapo: An open-source llm reinforcement learning system at scale." arXiv preprint arXiv:2503.14476 (2025).
- [13] Arash Ahmadian et al. "Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms." arXiv preprint arXiv:2402.14740 (2024).
- [14] Ronald J. Williams "Simple statistical gradient-following algorithms for connectionist reinforcement learning." Machine learning 8 (1992): 229-256.
- [15] Jixiao Zhang and Chunsheng Zuo. "Grpo-lead: A difficulty-aware reinforcement learning approach for concise mathematical reasoning in language models." arXiv preprint arXiv:2504.09696 (2025).
- [16] Yuhui Xu et al. "Scalable chain of thoughts via elastic reasoning." arXiv preprint arXiv:2505.05315 (2025).
- [17] Karl Cobbe et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021).
- [18] Dan Hendrycks et al. "Measuring mathematical problem solving with the math dataset." arXiv preprint arXiv:2103.03874 (2021).
- [19] Michael Luo et al. “DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL.” https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2 (2025).
- [20] An Yang et al. “Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement.” arXiv preprint arXiv:2409.12122v1 (2024).
- [21] An Yang et al. "Qwen3 technical report." arXiv preprint arXiv:2505.09388 (2025).
- [22] Amrith Setlur et al. "e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs." ICML 2025 Workshop on Long-Context Foundation Models (2025).
- [23] Mingjie Liu et al. "ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models." arXiv preprint arXiv:2505.24864 (2025).