.svg)
私たちは、合計83億パラメータを持ち、トークンごとに15億のアクティブパラメータを使用する、初のオンデバイスMixture-of-Experts(MoE)モデル「LFM2-8B-A1B」の初期チェックポイントを公開します。
推論時にスパースなパラメータの一部のみを活性化することで、LFM2-8B-A1Bは15億クラスのモデルと同等の計算コストで、より大きなモデル品質を実現します。
また、メモリ使用量のわずかな増加と引き換えに、従来の高密度モデルよりも高い品質と速度を両立します。
これにより、最新のスマートフォン、タブレット、ラップトップ上で、高速かつプライベートで遅延に敏感なアプリケーションが実現可能です。
ハイライト
- LFM2-8B-A1Bは、品質(3〜4Bクラスの高密度モデルと同等)と速度(Qwen3-1.7Bより高速)の両面で、最も優れたオンデバイスMoEです。
- LFM2-2.6Bと比較して、コードおよび知識能力が大幅に向上しています。
- 量子化されたバリアントは、ハイエンドのスマートフォン、タブレット、ラップトップ上で快適に動作します。
LFM2 MoE アーキテクチャ
ほとんどの MoE(Mixture of Experts)研究は、大規模バッチ処理を行うクラウドモデルに焦点を当てています。オンデバイスアプリケーションでは、厳しいメモリ制約の下でレイテンシとエネルギー消費を最適化することが鍵となります。LFM2-8B-A1B は、MoE アーキテクチャが小規模パラメータサイズでは効果的でないという一般的な認識に挑戦する初期のモデルの1つです。
LFM2-8B-A1B は、わずかに大きなメモリ使用量と引き換えに高品質を実現しつつ、低レイテンシと低エネルギー消費を維持します。
LFM2 ファミリーは、短距離入力認識型ゲート付き畳み込み(short-range, input-aware gated convolutions)と grouped-query attention(GQA)を組み合わせ、厳しい速度とメモリ制約の中で品質を最大化するように調整された構成で、オンデバイス推論に最適化されています。
LFM2-8B-A1B はこの高速なバックボーンを維持しつつ、スパース MoE フィードフォワードネットワークを導入し、アクティブな計算経路を大きく増やすことなく表現能力を拡張します。
.png)
概要:
- LFM2 バックボーン: 18 個のゲート付きショート畳み込みブロックと 6 個の GQA ブロック。
- サイズ: 合計 83 億パラメータ、アクティブパラメータは 15 億。MoE 配置: 最初の 2 層を除き、すべての層に MoE ブロックを含む。最初の 2 層は安定性のために密な構造を維持。
- MoE 配置: 最初の 2 層を除き、すべての層に MoE ブロックを含む。最初の 2 層は安定性のために密な構造を維持。
- エキスパート粒度: 各 MoE ブロックに 32 のエキスパートがあり、トークンごとに上位 4 つのアクティブエキスパートが適用される。この構成により、低粒度設定よりも高品質を維持しながら、高速なルーティングと移植性の高いカーネルを実現。
- ルーター: 正規化されたシグモイドゲーティングを使用し、ロードバランシングと学習ダイナミクスを改善するために適応型ルーティングバイアスを採用。
なぜデバイス上で重要なのか?
トークンごとにネットワークの一部のみがアクティブになるため、トークンあたりの FLOPs とレイテンシは約 15 億パラメータの密モデルに相当する。一方で、総容量 83 億パラメータにより、各エキスパートが推論、多言語、コード、ロングテール知識などの専門領域に特化でき、品質を向上させる。
メモリと展開性:
重みの保存は総パラメータ数に比例してスケールするが、計算と状態キャッシュはアクティブパスに比例してスケールする。実際には、量子化されたバリアントはハイエンドのスマートフォン、タブレット、ノートパソコンに快適に収まり、幅広いアプリケーションに対応できる。
推論
次の動画では、LFM2-8B-A1B が Apple M2 Pro チップを搭載した MacBook Pro 上で Metal 有効化(Q4_0 量子化) によりローカル実行されている様子を示しています。
LFM2-8B-A1B は、llama.cpp, ExecuTorch, vLLM(公開版は近日リリース予定) など、複数の推論フレームワークと互換性があります。
以下のグラフは、llama.cpp バックエンドおよび Q4_0 量子化を使用した場合のデコードスループットを、2つのハードウェアターゲット上で比較したものです:
- Samsung Galaxy S24 Ultra(Qualcomm Snapdragon SoC)
- AMD Ryzen HX370
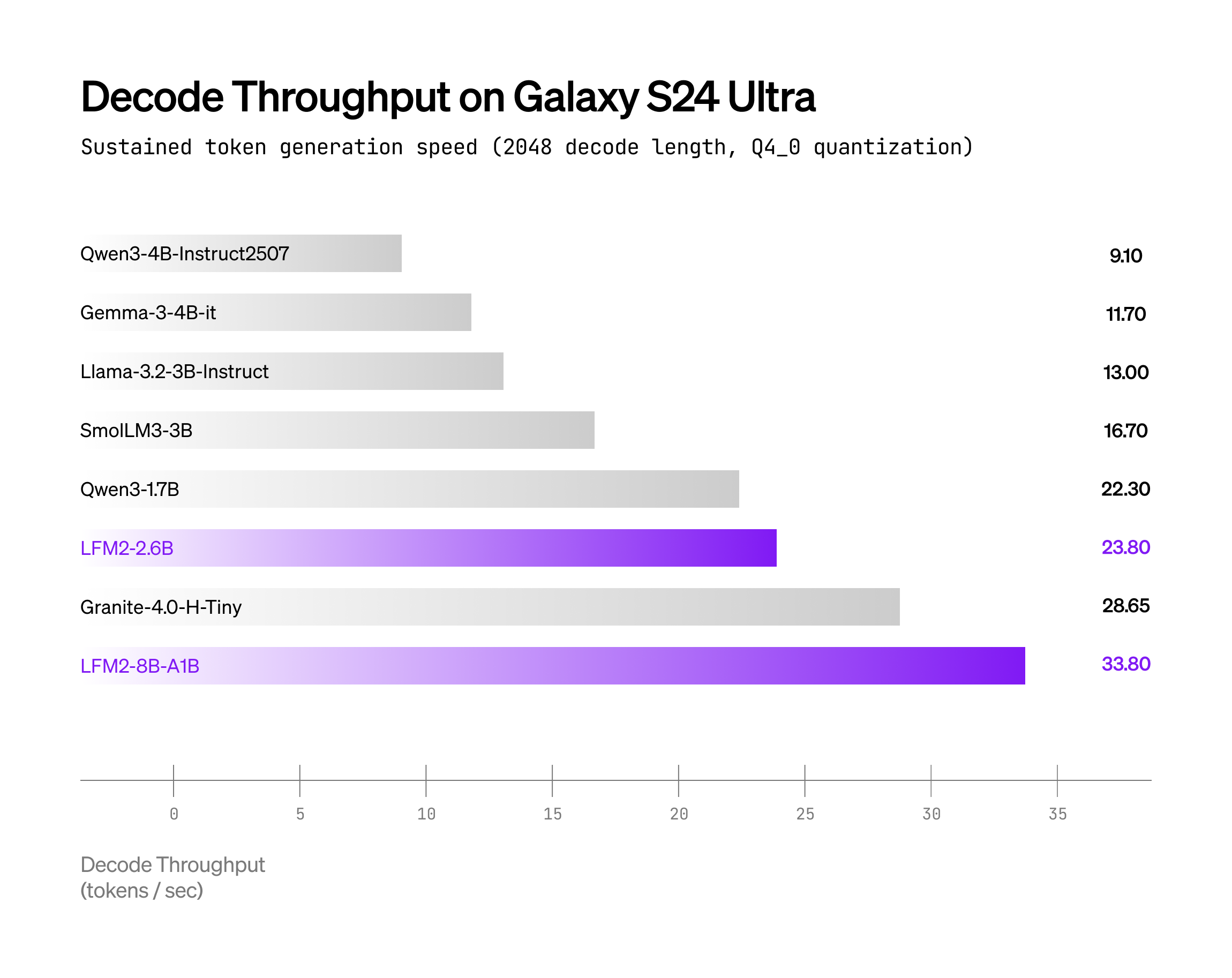
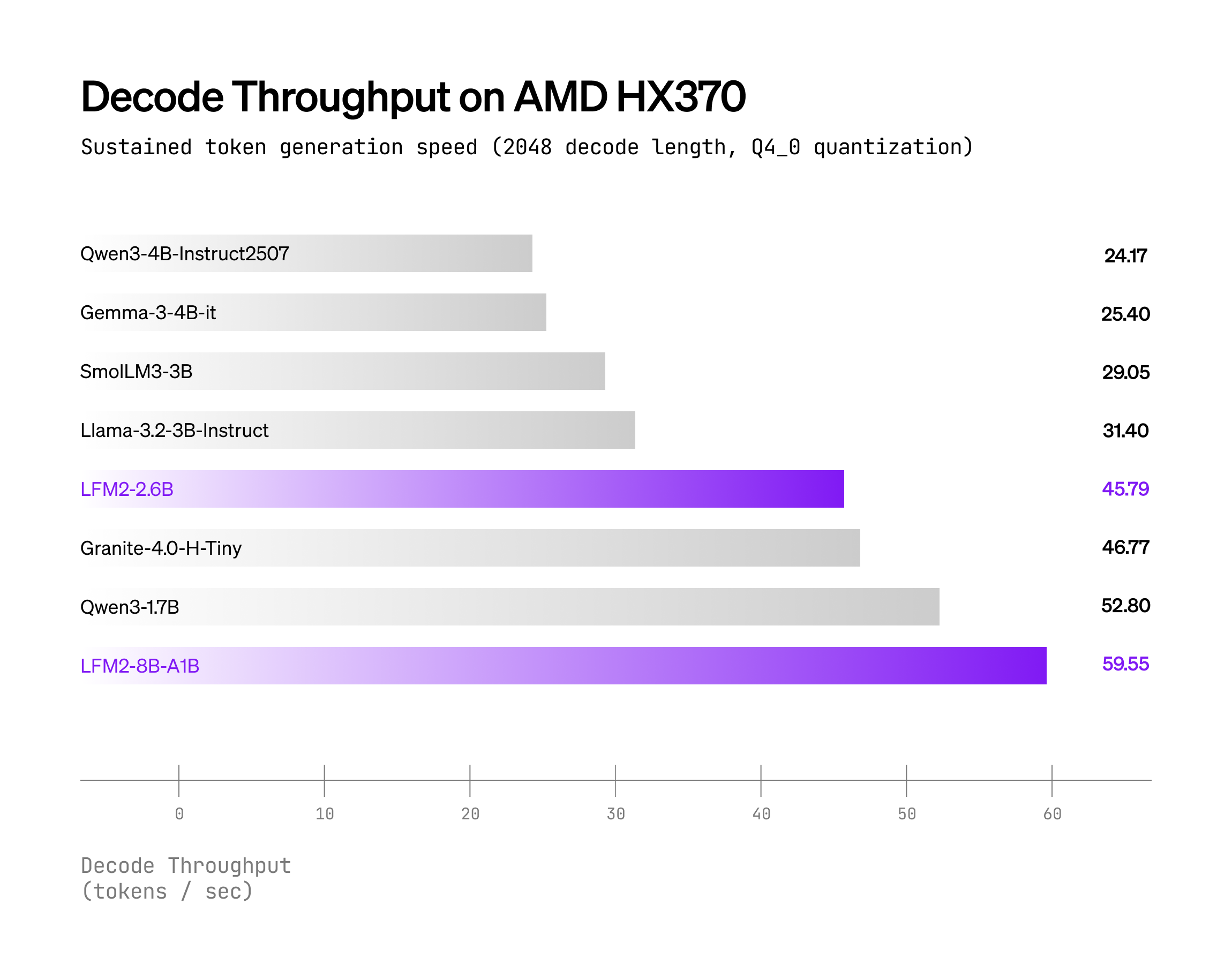
LFM2-8B-A1B は、同等のアクティブパラメータ数を持つモデル(例:Qwen3-1.7B)と比べて大幅に高速です。
評価
LFM2-8B-A1B のベースバージョンは、ウェブおよびライセンス済みデータから収集された約 12 兆トークンで事前学習されました。学習コーパスの構成は、およそ英語 55%、多言語 25%、コードデータ 20%です。現在もベースモデルの学習を継続しています。
LFM2-8B-A1B は、知識(5-shot MMLU、5-shot MMLU-Pro、0-shot GPQA)、指示追従(IFEval、IFBench、Multi-IF)、数学(5-shot GSM8K、5-shot GSMPlus、0-shot MATH500、0-shot Math Lvl 5)、および多言語タスク(5-shot MGSM、5-shot MMMLU)を含む 16 の主要ベンチマークで包括的に評価しました。すべての結果は社内評価ライブラリを使用して取得しています。
同等サイズのモデルと比較して、LFM2-8B-A1B は指示追従と数学分野で高い性能を示しながら、動作速度も大幅に向上しています。LFM2-2.6B と比較すると、パラメータ数が多いため知識容量が増加しており、MMLU-Pro スコアは LFM2-2.6B に対して +11.46 ポイントの向上を示しています。
また、LFM2-8B-A1B は事前学習および後学習の両方で LFM2-2.6B よりも多くのコードデータで訓練されています。これにより、LiveCodeBench(LCB)v6、v5、および HumanEval+ スコアに示されるように、より競争力のあるコーディング能力を獲得しています。
さらに、短編創作の文章品質を LLM が評価する EQ-Bench Creative Writing v3 においても評価を行いました。LFM2-8B-A1B のライティング能力は、はるかに多くのアクティブパラメータを持つモデルと比較しても十分に競争力があります。
Liquidの嗜好調整
私たちは、強力なモデル性能と迅速な反復を両立させるために、直接的なアライメント手法を適用しています。
私たちのプリファレンス・データセットは、分布内カバレッジを重視しています。これは、オープンソースおよび独自の命令・嗜好データの両方から抽出された約100万件の会話から始まります。各プロンプトに対して、SFTチェックポイントから5つの応答をサンプリングし、LLMベースの評価者がそれらをランク付けします。最上位の応答を「選択済み(chosen)」、最下位の応答を「拒否済み(rejected)」として選び、同点の場合はオンポリシーの出力を優先します。特定のサブセット(例:指示追従)については、Contrastive Learning from AI Revisions(CLAIR)を用いて選択済み応答をさらに洗練させます。定量的および定性的フィルターを組み合わせて適用し、高品質なデータを確保するとともに、望ましくない挙動を除去しています。
その後のトレーニングは、次の一般化損失関数で表される、長さ正規化されたアライメント目的関数のファミリーに基づいて実行されます。
.png)
データセット $\mathcal{D}$ からサンプリングされたプロンプト $x$、好ましい応答 $y_w$、および好ましくない応答 $y_l$ に対して評価を行います。ここで、暗黙的な報酬は $r_\theta\left(x,y\right)=\beta\log\frac{\pi_\theta\left(y|x\right)}{\pi_\text{ref}\left(y|x\right)}$ によって与えられます。これに基づいて、長さ正規化された相対値 $\Delta=\frac{r_\theta(x,y_w)}{|y_w|} - \frac{r_\theta(x,y_l)}{|y_l|}$ および絶対値 $\delta=\sigma \left(\frac{r_\theta(x,y_w)}{|y_w|}\right) - \sigma\left(\frac{r_\theta(x,y_l)}{|y_l|}\right)$ の損失成分を定義します。ここで $|y|$ はトークン数を示し、$\sigma$ はシグモイド関数を表します。これらの項は関数 $f(\cdot)$ および $g(\cdot)$ によって変換され、重み $\omega$ および $\lambda$ によって結合されます。上式において、$\beta$ は標準的なKL係数を、$m$ はマージンを示します。
この一般的な定式化から、特別なケースとして長さ正規化DPO($\omega=1$, $f(x)=\log(\sigma(x))$, $m=0$, $\lambda=0$, $g(x)=0$)および長さ正規化APO-zero($\omega=0$, $f(x)=0$, $m=0$, $\lambda=1$, $g(x)=x$)を導くことができます。
最終モデルは、各目的でトレーニングされたチェックポイントの強みを組み合わせるタスク算術的マージによって生成されます。
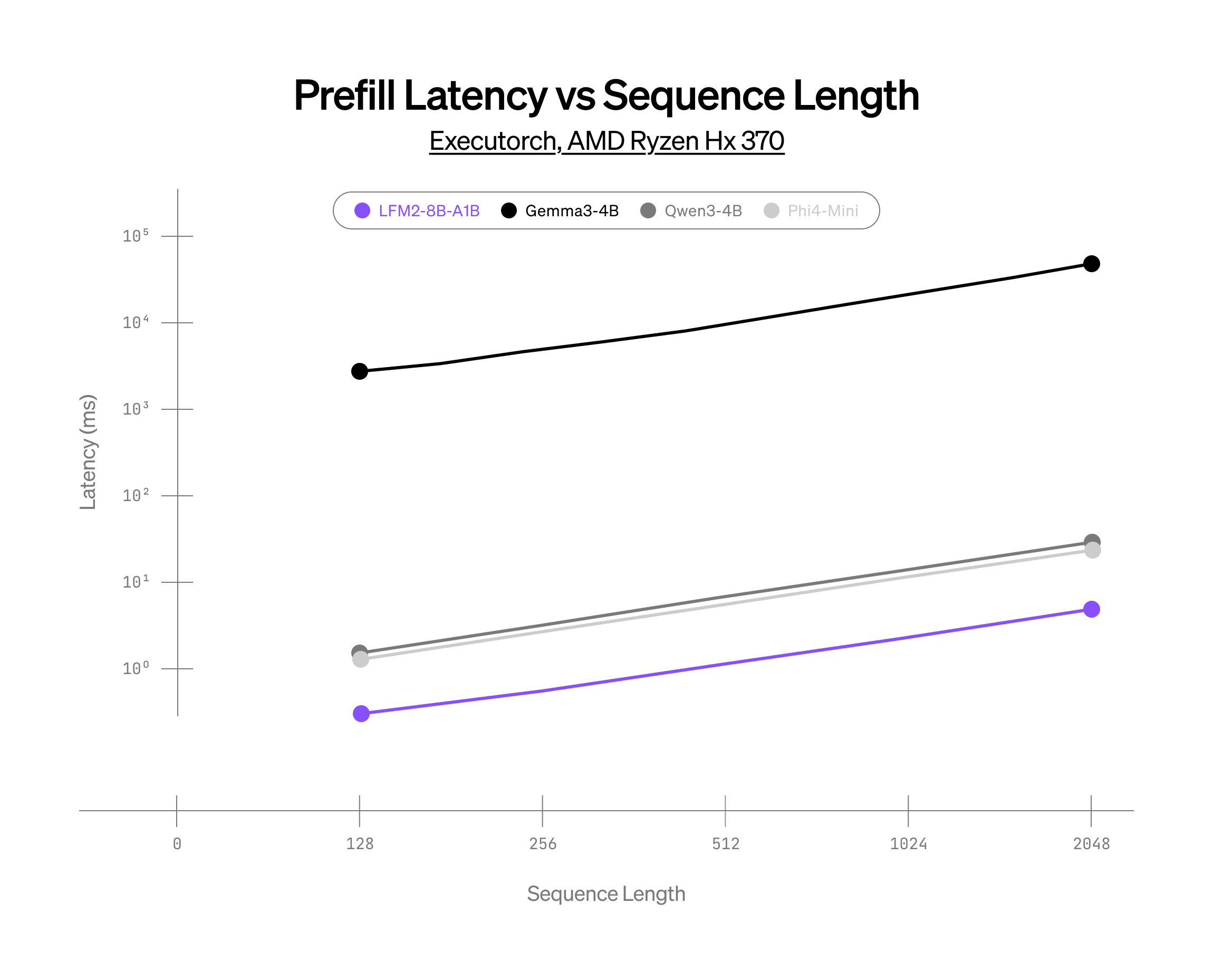
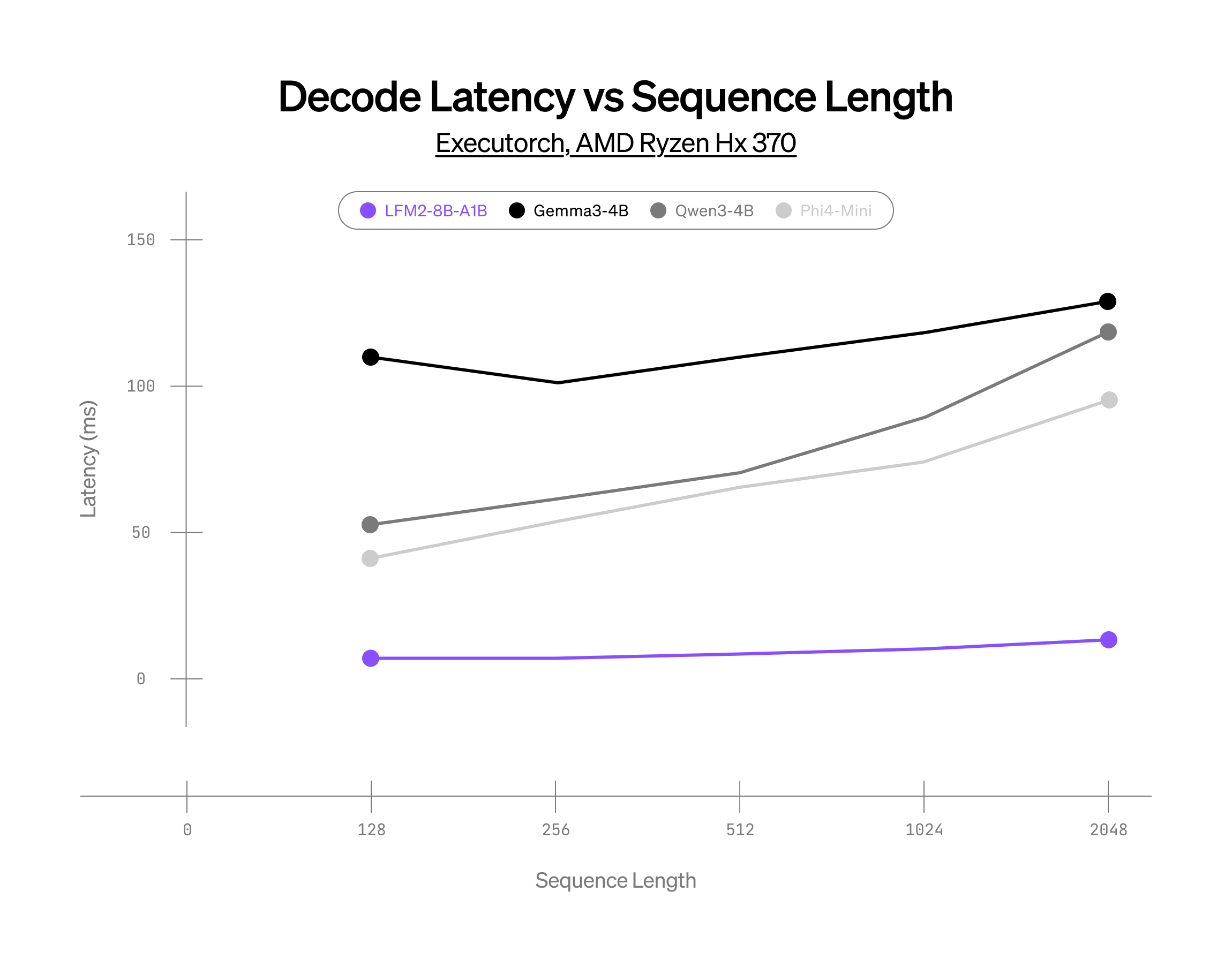
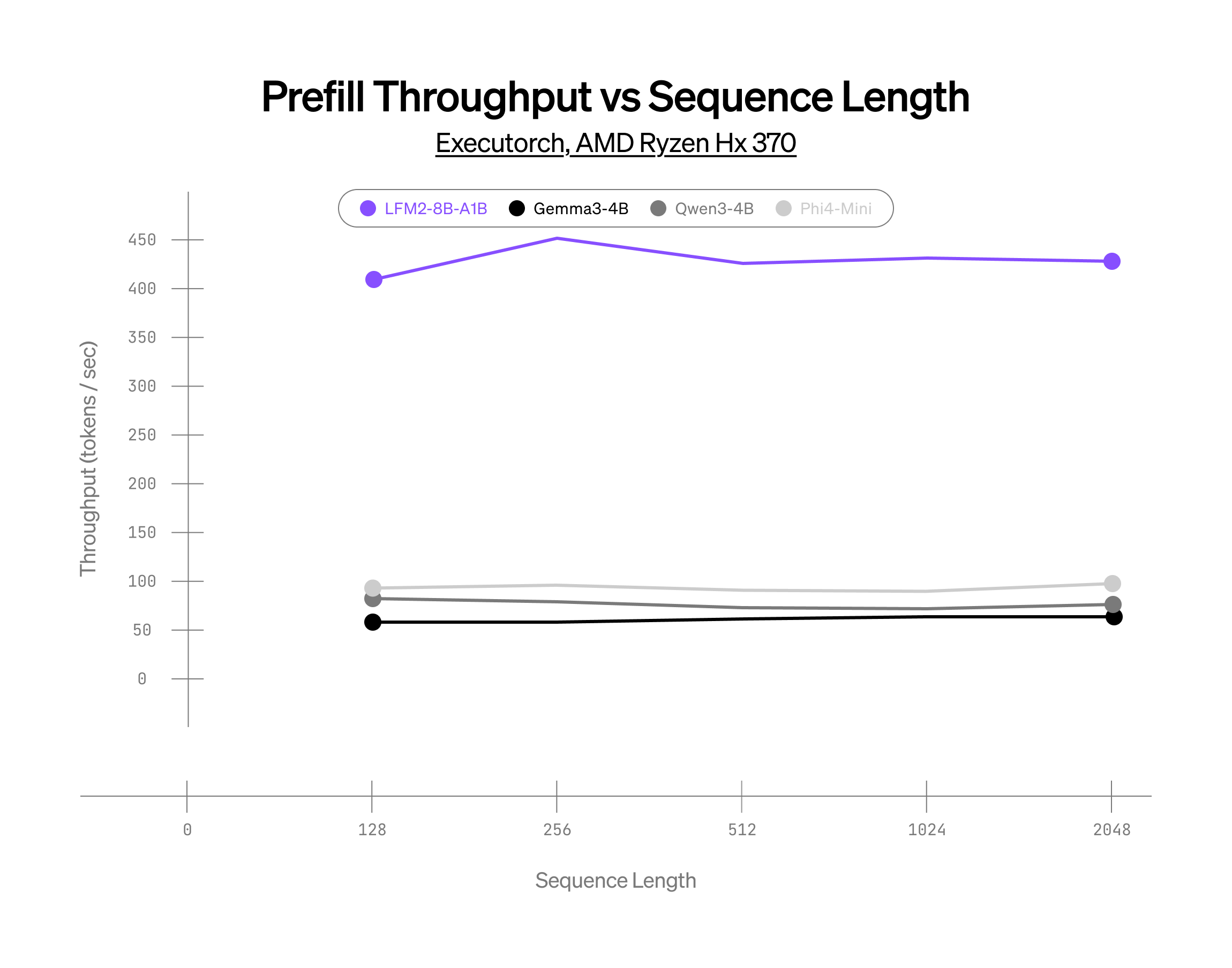
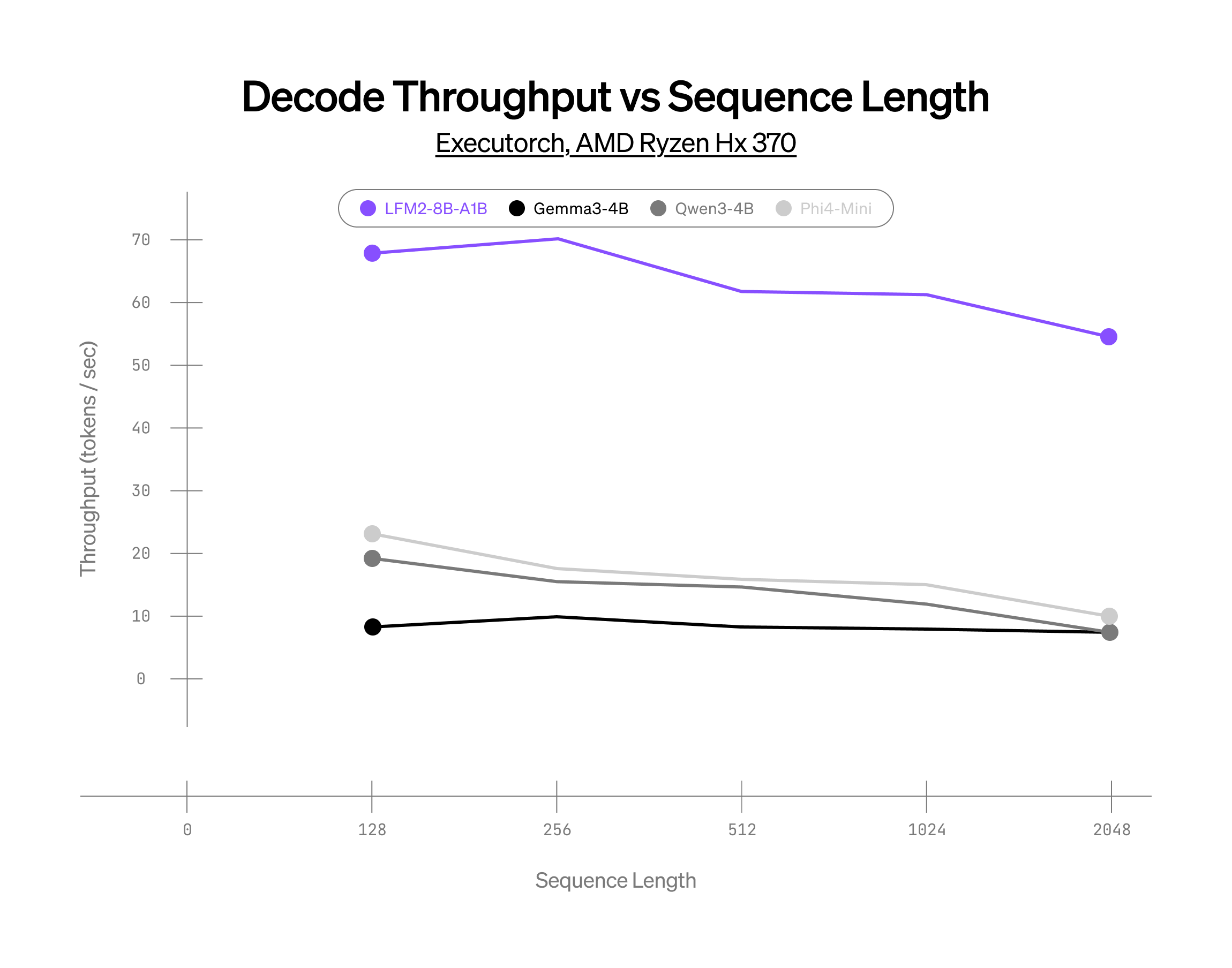
CPU上でのMoE推論の限界に挑戦
AMD HX 370でのパフォーマンス
int4量子化、XNNPACKベースの推論スタック
当社CTOのマティアス・レヒナー(Mathias Lechner)が自身の記事「Short Convolutions」で述べているように、Liquidの設計哲学は次の2つの側面から成り立っています。(1) 強力なLLM性能 (2) エッジデバイスでの効率性
LFM2-8B-A1Bの開発中、私たちにとって最も重要だったのは、お客様のデバイス上でモデルが非常に高速に動作することを検証することでした。そこで社内開発では、XNNPACKベースの推論スタックを用いてさまざまなアーキテクチャをプロファイリングしました。これにより、実行のあらゆる側面を制御し、ボトルネックを特定し、最適化されたカーネルを書く柔軟性を得ることができました。
この過程で、単純なMoE CPU実装はCPUハードウェアの活用という点で最適ではなく、GPU向けに最適化されたパターンに暗黙的に依存していることが分かりました。そこで、LFM2 MoEのためにCPU向けに最適化されたカーネルを新たに作成し、コアからより多くのFLOPsを引き出すことに成功しました。
上記の結果は、同規模の競合モデルと比較して、当社のMoEモデルが大幅なパフォーマンス向上を達成していること、そしてCPU上におけるスパースアーキテクチャの可能性を示しています。
GPU 推論の高速化
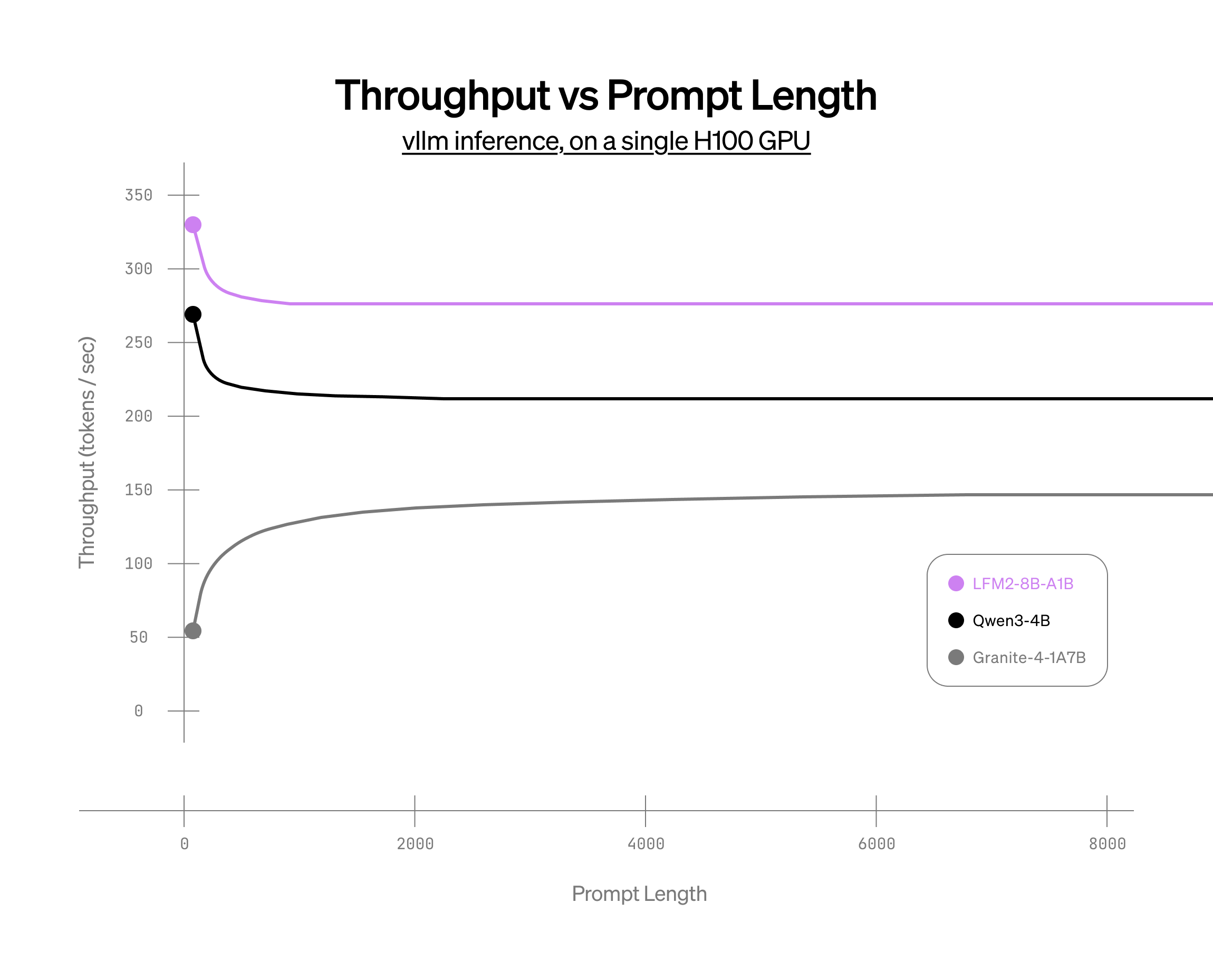
CPU のみのデバイスでの推論効率を検証するために、LFM2-8B-A1B を llama.cpp および Executorch に統合したのに加えて、GPU 上で単一リクエストおよびオンラインバッチ設定の両方でデプロイするためにモデルを vLLM にも統合しました。
当社の 8B LFM2 MoE モデルは、上記のグラフで示されているように、CPU 上で同等サイズのモデルを上回るだけでなく、GPU(1xH100)上でもそれらのモデルを凌駕します。
上記のすべてのモデルは、デコード時に完全な CUDA グラフコンパイルを行い、プリフィル時に部分的な CUDA グラフを使用する FlashInfer バックエンドで注意層をベンチマークしました。
今すぐ upstream vLLM 上で LFM2-8B-A1B をお試しください!
LFM2 で構築する
LFM2-8B-A1B は本日より Hugging Face で利用可能です。私たちは、Colab ノートブック を提供しており、GGUF 量子化モデル および TRL を使用して llama.cpp 上で実行するためのファインチューニングが可能です。今すぐ Liquid Playground でテストしてみてください。