
LFM2.5-VL-450M: Structured Visual Intelligence, Edge to Cloud
Today, we release LFM2.5-VL-450M, an improved version of LFM2-VL-450M with grounding capabilities, better instruction following, and function calling support. The result is a compact model that turns image streams into structured, actionable outputs in real time, even on edge hardware.
LFM2.5-VL-450M is available on Hugging Face, LEAP, and our Playground. Check out our docs on how to run and fine-tune it locally.
What’s new
Compared to our LFM2-VL-450M that we released a few months ago, we scaled the pre-training of LFM2.5-VL-450M from 10T to 28T tokens, followed by post-training focused on improving multimodal behavior in production settings. In particular, we used preference optimization and reinforcement learning to improve grounding, instruction following, and overall reliability across vision-language tasks.
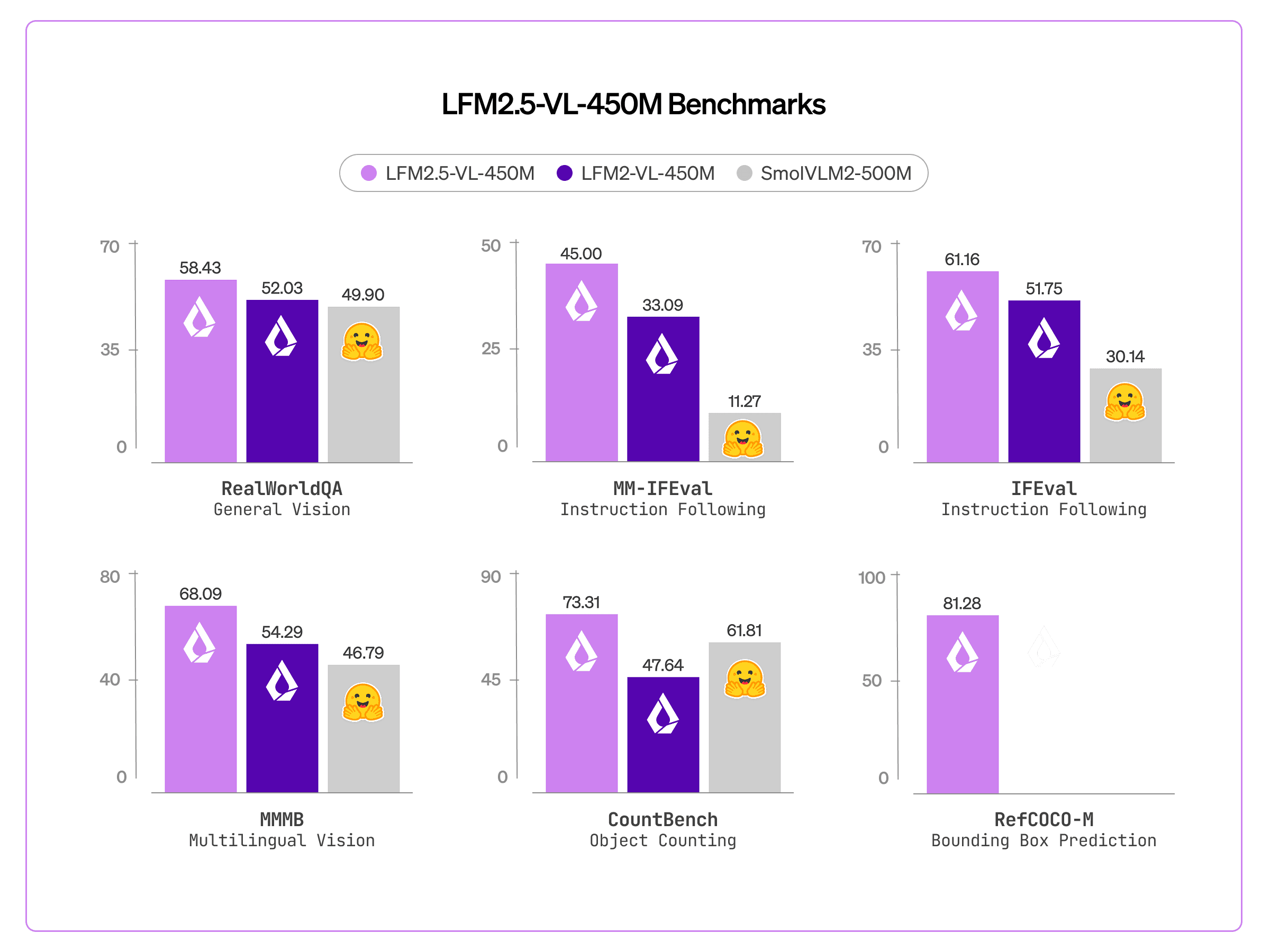
Bounding box prediction: 0 → 81.28 on RefCOCO-MWe added object detection, allowing the model to identify objects in an image and locate them with bounding boxes.
Improved multilingual image understanding: MMMB 54.29 → 68.09, covering Arabic, Chinese, French, German, Japanese, Korean, Portuguese, SpanishLFM2.5-VL-450M handles prompts in eight languages with higher accuracy, extending visual reasoning to global deployments without separate localization models.
Better instruction following: MM-IFEval 32.93 → 45.00The model is more responsive to explicit constraints and user instructions, improving steerability across both text and vision inputs.
Credit: Joshua Lochner for the original VLM demo
Benchmarks
We evaluated LFM2.5-VL-450M across benchmarks covering core vision understanding, object detection, and language reasoning. LFM2.5-VL-450M improves over LFM2-VL-450M across both vision and language benchmarks, while also adding support for bounding box prediction (measured on RefCOCO-M) and text function calling (measured by BFCLv4).
LFM2.5-VL-450M | LFM2-VL-450M | SmolVLM2-500M | |
|---|---|---|---|
Vision | |||
MMStar | 43.00 | 40.87 | 38.20 |
RealWorldQA | 58.43 | 52.03 | 49.90 |
MMBench (dev en) | 60.91 | 56.27 | 52.32 |
MMMU (val) | 32.67 | 34.44 | 34.10 |
POPE | 86.93 | 83.79 | 82.67 |
MMVet | 41.10 | 33.85 | 29.90 |
BLINK | 43.92 | 42.61 | 40.70 |
InfoVQA (val) | 43.02 | 44.56 | 24.64 |
OCRBench | 684 | 657 | 609 |
MM-IFEval | 45.00 | 33.09 | 11.27 |
MMMB | 68.09 | 54.29 | 46.79 |
CountBench | 73.31 | 47.64 | 61.81 |
RefCOCO-M | 81.28 | - | - |
Language (text only) | |||
GPQA | 25.66 | 23.13 | 23.84 |
MMLU Pro | 19.32 | 17.22 | 13.57 |
IFEval | 61.16 | 51.75 | 30.14 |
Multi-IF | 34.63 | 26.21 | 6.82 |
BFCLv4 | 21.08 | - | - |
*All vision benchmark scores are obtained using VLMEvalKit. Multilingual MMMB scores are based on the average of benchmarks translated by GPT-4.1-mini from English to Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish.
Performance: Made for the Edge
In real-world deployments, VLMs process live camera and image input, and must reason and act within a tight latency budget. LFM2.5-VL-450M (Q4_0) runs within budget across the whole range, from embedded AI modules (Jetson Orin) to mini-PC APUs (Ryzen AI Max+ 395) to flagship phone SoCs (Snapdragon 8 Elite).
Resolution | Jetson Orin | Samsung S25 Ultra | AMD 395+ Max |
|---|---|---|---|
256×256 | 233 ms | 950 ms | 637 ms |
512×512 | 242 ms | 2.4 s | 944 ms |
On Jetson Orin, the model reasons over a 512×512 image in under 250ms, fast enough to process every frame in a 4 FPS video stream with full vision-language understanding, not just detection. On consumer mobile silicon, it stays under one second for smaller resolutions, keeping interactive experiences responsive.
Real-World Use Cases:
LFM2.5-VL-450M is especially well suited to real-world deployments where low latency, compact structured outputs, and efficient semantic reasoning matter most. These qualities make it a strong fit for early adoption in environments with tight compute, power, or throughput constraints, and in settings where offline operation or on-device processing is important for privacy.
Industrial Automation — Edge and Constrained Environments
In compute-constrained environments such as passenger vehicles, agricultural machinery, and warehouses, perception models are often limited to bounding-box outputs. LFM2.5-VL-450M goes further, providing grounded scene understanding in a single pass so systems can reason semantically about the scene, not just detect objects in it. That means richer outputs for settings like warehouse aisles, including worker actions, forklift movement, and inventory flow, while still fitting existing edge hardware like a Jetson Orin.
Wearables and Always-On Monitoring — On-Device and Privacy-Sensitive
Wearables and other always-on monitoring systems are a natural fit for compact VLMs because they operate under strict power, latency, and privacy constraints. Devices such as smart glasses, body-worn assistants, dashcams, and security or industrial monitors cannot afford large perception stacks or constant cloud streaming. In these settings, an efficient VLM can produce compact semantic outputs locally, turning raw video into useful structured understanding while keeping compute demands low and preserving privacy.
Retail and E-Commerce — High-Throughput Visual Processing
Retail and e-commerce platforms operate in extremely high-throughput environments, where millions of product and shelf images must be processed under tight latency and cost constraints. Tasks like catalog ingestion, visual search, product matching, and shelf compliance require more than object detection, but richer visual understanding is often too expensive to deploy at this scale. LFM2.5-VL-450M makes structured visual reasoning practical for these workloads, delivering semantic outputs with the speed and efficiency needed for real production systems.
Get Started
The LFM2.5-VL-450M model is available today on Hugging Face, LEAP, and our Playground. Adapt it to your domain with LEAP Fine-Tune.