
Introducing LFM2-2.6B: Redefining Efficiency in Language Models
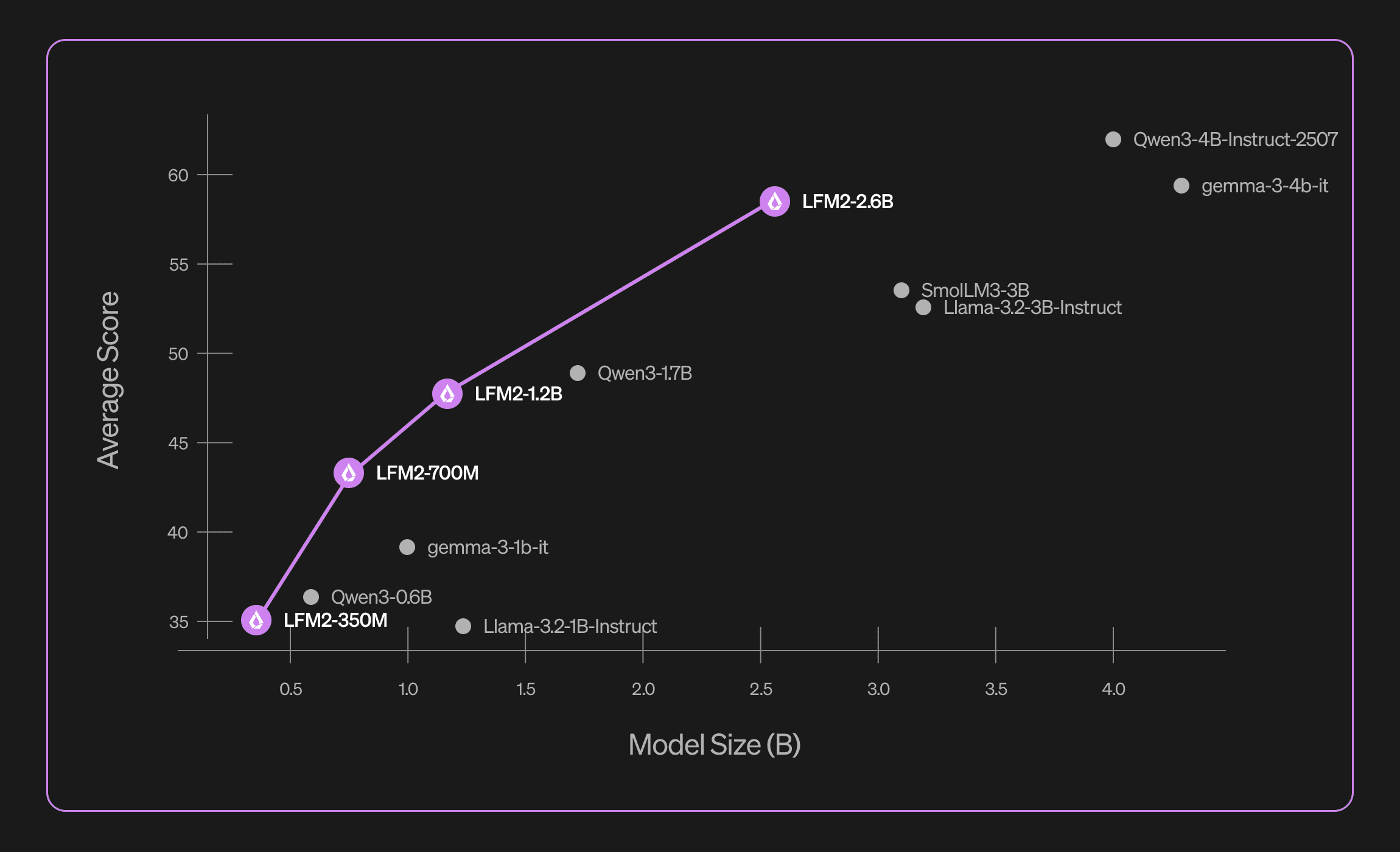
We're excited to announce LFM2-2.6B, the newest and currently largest model in our Liquid Foundation Model 2 series. Building on our 350M, 700M, and 1.2B models, LFM2-2.6B proves that exceptional performance doesn't require massive scale.
Small Model, Big Impact
With just 2.6 billion parameters, LFM2-2.6B outperforms models in the 3B+ class including Llama 3.2-3B-Instruct, Gemma-3-4b-it, and SmolLM3-3B. Trained on 10 trillion tokens, it achieves an impressive 82.41% on GSM8K for mathematical reasoning and 79.56% on IFEval for instruction following—rivaling much larger models.
The model was specifically tuned for English and Japanese, while maintaining strong performance in French, Spanish, German, Italian, Portuguese, Arabic, Chinese, and Korean, making it truly versatile for global applications.
Speed Through Innovation
LFM2-2.6B's hybrid architecture alternates blocks of Grouped Query Attention (GQA) with short convolutional layers, delivering significantly faster inference speeds and reduced KV cache requirements compared to other modern architectures. This translates to faster responses and lower deployment costs at scale.
Open and Available
LFM2-2.6B is now available on Hugging Face under our LFM Open License, making cutting-edge efficient AI accessible to developers and researchers worldwide.
The LFM2 series continues to push the boundaries of efficient AI. We're proving that with the right architecture and approach, smaller models can deliver enterprise-grade performance without the computational overhead. In the future, we will continue to scale our foundation models to bring this level of efficiency to more devices and unlock new applications.