
The Future of Meeting Summarization: Local, Fast, Private, and Fully Secure
This week at CES, our Liquid AI team and partners at AMD are showcasing the future of on-device intelligence with lightning fast, reliable and entirely secure meeting summarization, run locally on AMD hardware.
Meetings capture critical business intelligence: decisions, commitments, customer insights, action items, and often, confidential and sensitive information. Most AI summarization tools require sending that data to the cloud, introducing latency, unpredictable costs, and real security and compliance risks.
Together, the Liquid AI and AMD teams have developed and deployed a cloud-quality meeting summarization model that runs entirely on-device across the full AMD Ryzen™ AI platform, providing:
- Cloud-level summarization quality
- Summaries generated in seconds
- <3 GB RAM usage
- Lower latency and energy consumption than larger transformer baselines
- Fully local execution across CPU, GPU, and NPU
This project went from zero to deployed in under two weeks, showcasing how LFMs are powering the “AI everywhere” movement and what’s possible when highly specialized models are designed with hardware in mind and deployed on-device. Read the full case study here.
Today, we’re bringing this fast, private, on-device enterprise-grade meeting summarization to everyone, with LFM2-2.6B-Transcript: a purpose-built Liquid Nano designed for long-form meeting transcripts and real operational use.
No cloud dependency, no data leaving the device, and no compromise on performance. Deployable on your chosen hardware across CPU, NPU, and GPU.
Now available for download on LEAP and Hugging Face.
LFM2-2.6B-Transcript: Cloud-quality meeting summarization, fully on-device
LFM2-2.6B-Transcript is trained for long-form transcript summarization of 30–60 minute meetings. Making it ideal for internal team meetings, sales calls, customer conversations, board and executive briefings, sensitive security critical conversations, and offline or low-connectivity workflows.
It produces clear, structured outputs, like key discussion points, explicit decisions, and attributed action items, with consistent formatting and tone.
To achieve the best results, we use a specific format to input meeting transcripts for summarization:
<user_prompt>
Title (example: Claims Processing training module)
Date (example: July 2, 2021)
Time (example: 1:00 PM)
Duration (example: 45 minutes)
Participants (example: Julie Franco (Training Facilitator), Amanda Newman (Subject Matter Expert))
----------
**Speaker 1**: Message 1 (example: **Julie Franco**: Good morning, everyone. Thanks for joining me today.)
**Speaker 2**: Message 2 (example: **Amanda Newman**: Good morning, Julie. Happy to be here.)
etc.Users can then specify what the model outputs among the following summary types by simply replacing <user_prompt> with the following options:
Summary type | User prompt |
|---|---|
Executive summary | Provide a brief executive summary (2-3 sentences) of the key outcomes and decisions from this transcript. |
Detailed summary | Provide a detailed summary of the transcript, covering all major topics, discussions, and outcomes in paragraph form. |
Action items | List the specific action items that were assigned during this meeting. Include who is responsible for each item when mentioned. |
Key decisions | List the key decisions that were made during this meeting. Focus on concrete decisions and outcomes. |
Participants | List the participants mentioned in this transcript. Include their roles or titles when available. |
Topics discussed | List the main topics and subjects that were discussed in this meeting. |
We designed it to be freeform, allowing users to mix and match, adding several prompts or combining them into a single one, to create the output format that’s best for them. Below are some examples:
Performance and benchmarks
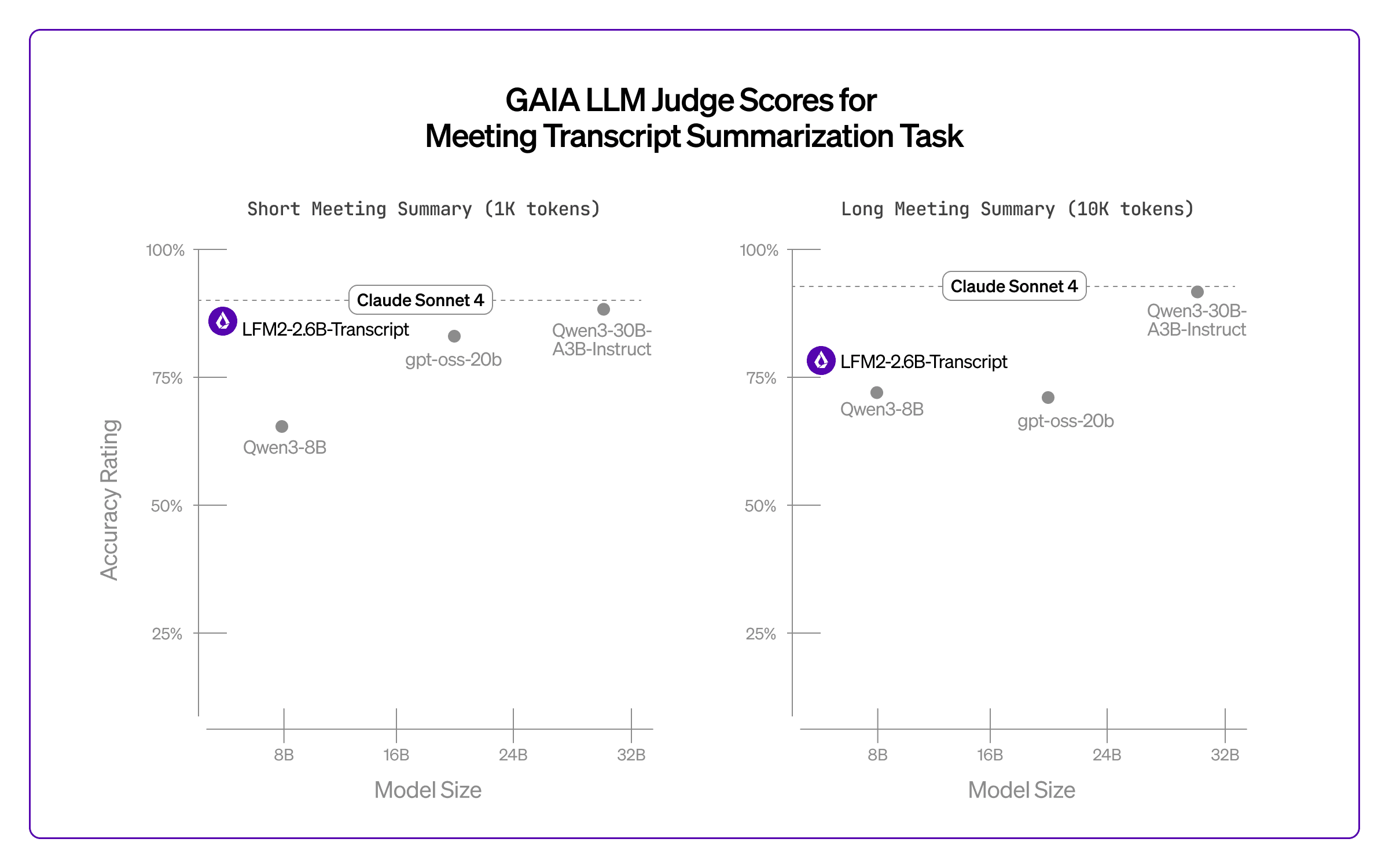
Accuracy: Benchmarking shows the model outperforming gpt-oss-20b and approaching the performance of Qwen3-30B and Claude Sonnet on short (1K transcripts), both of which are orders of magnitude larger.
On long (10K) transcripts, the LFM2 model still outperforms gpt-oss-20b, while slightly underperforming the significantly larger Qwen3-30B and cloud models.
RAM Usage: In our configuration, LFM2-2.6B-Transcript can process 10K tokens (~60-minute meeting transcript) in 2.7GB of RAM, cleanly fitting into typical 16GB RAM systems where only ~4GB is available for AI workloads. This is much less than the many gigabytes required for quality-comparable transformer models. The visual below summarizes RAM usage at equal context length. This gap is what makes full on-device deployment on 16GB AI PCs practical for LFM2—but effectively out of reach for many traditional transformer models.
Speed: Benchmarks show that LFM2-2.6B-Transcript can summarize a 60-minute, 10K-token, meeting into a 1K-token summary in 16 seconds—fast enough for interactive, near-real-time workflows rather than “batch overnight jobs.”
Getting started building with LFM2-2.6B-Transcript
The easiest way to experience LFM2-2.6B-Transcript is through our command-line tool example, which you can find in the Liquid AI Cookbook.
Steps:
1. Install uv if you don’t have it already. Once installed, run the following command to verify the installation:
$ uv --version
uv 0.9.182. Run the CLI for this sample transcript with the following command:
uv run
https://raw.githubusercontent.com/Liquid4All/cookbook/refs/heads/main/examples/meeting-summarization/summarize.pyNo API keys. No cloud services. No setup. Just pure local inference with real-time token streaming.
3. You can also pass your own transcript files (local or remote URLs). For example:
uv run
https://raw.githubusercontent.com/Liquid4All/cookbook/refs/heads/main/examples/meeting-summarization/summarize.py \
--transcript-file
https://raw.githubusercontent.com/Liquid4All/cookbook/refs/heads/main/examples/meeting-summarization/transcripts/example_2.txtThe tool uses llama.cpp for optimized inference and automatically handles model downloading and compilation for your platform. Check out the full code and documentation in our cookbook.
On-Device Meeting Summarization For Your Business
With LFM2.6B-Transcript, enterprises can now deploy meeting summarization that matches the quality of cloud-based tools, without exposing sensitive data, introducing latency, or relying on external infrastructure.
With Liquid’s efficiency-first foundation models, organizations can work directly with Liquid to fine-tune and deploy fully private, on-device meeting summarization systems tailored to their workflows or build themselves with LEAP.
These models run entirely within corporate environments—on employee laptops, secure workstations, or air-gapped systems, ensuring transcripts, summaries, and insights never leave the device.
Liquid works with customers to customize models for specific meeting types (e.g., executive briefings, customer calls, internal planning sessions) while optimizing performance for their exact hardware footprint. The result is a production-ready system that feels as seamless as SaaS, but operates entirely under enterprise control.
Giving enterprises the best of cloud AI without the tradeoffs:
- Cloud-level summary quality, tuned to your meeting formats and terminology
- Zero data exfiltration, enabling use in regulated, confidential, or IP-sensitive settings
- Instant responses, with no network latency or throttling
- No vendor lock-in or API dependencies, even during outages
- Predictable, low operating costs, with no per-call or per-token fees
Build with LFMs
Meeting summarization is just one example of what becomes possible when models are small, specialized, and hardware-aware. Instead of routing every workflow through costly cloud models, enterprises can deploy purpose-built intelligence wherever it’s needed: on laptops, edge devices, or secure on-prem systems.
This methodology of highly specializing small, efficient models for a specific task unlocks a world of other high-value use cases like personalized in-car AI assistants, customized experiences in consumer electronics, industrial robotics, and more.
Build with AMD hardware — AMD Ryzen AI 400 Series PCs optimized for on-device AI workloads. Learn more
Build with Liquid's LFMs—scenario-specific models delivering cloud-quality intelligence at a fraction of the cost and energy. Get in touch with Liquid AI today.