
LFM2-Audio: An End-to-End Audio Foundation Model
Today, we release LFM2-Audio-1.5B, an end-to-end foundation model for audio and text generation. Designed for low latency, it enables responsive, high-quality conversations with only 1.5 billion parameters. This model extends the LFM2 family into the audio-text space.
LFM2-Audio can seamlessly switch between audio and text inputs and outputs. This offers a dynamic, practical backbone for diverse applications such as real-time chatbots, automatic speech recognition (ASR), or text-to-speech (TTS), all in a single multimodal foundation model. Our lightweight architecture enables seamless deployment across device environments and efficient inference.
Architecture
LFM2-Audio-1.5B extends the LFM2-1.2B language model to support both text and audio as first-class modalities in both input and output.
The language model backbone operates over sequences of tokens that can represent either text or audio. On the input side, the model can intake and tokenize both text tokens and audio tokens into the same shared space. On the output side, it can autoregressively generate either modality, depending on the task.
Modeling audio natively: Unlike other audio foundation models, we disentangle the representations of audio input (continuous token embeddings) and output (discrete token codes) as separate “representations”. Keeping audio input as a continuous feature provides a rich representation that avoids artifacts introduced by discrete tokenization. Meanwhile, outputting discrete audio tokens for generation enables the model to be trained as a unified end-to-end next-token predictor, leading to dramatically improved overall quality.
Input understanding: To maximize quality of audio input processing, we adopt a tokenizer-free approach. The raw audio waveform is chunked into short segments (~80 ms each), which are then directly projected into the native embedding space of the LFM2 backbone.
Output generation: To generate audio outputs, LFM2-Audio predicts discrete audio tokens in the same way it predicts text tokens. These tokens are then decoded back into raw audio waveform. Each token represents a short slice of sound, which when decoded and combined create fluid, continuous audio. For improved quality in generated audio, LFM2-Audio can decode up to 8 discrete audio tokens per step, enabling richer and more expressive audio outputs.
Evaluations
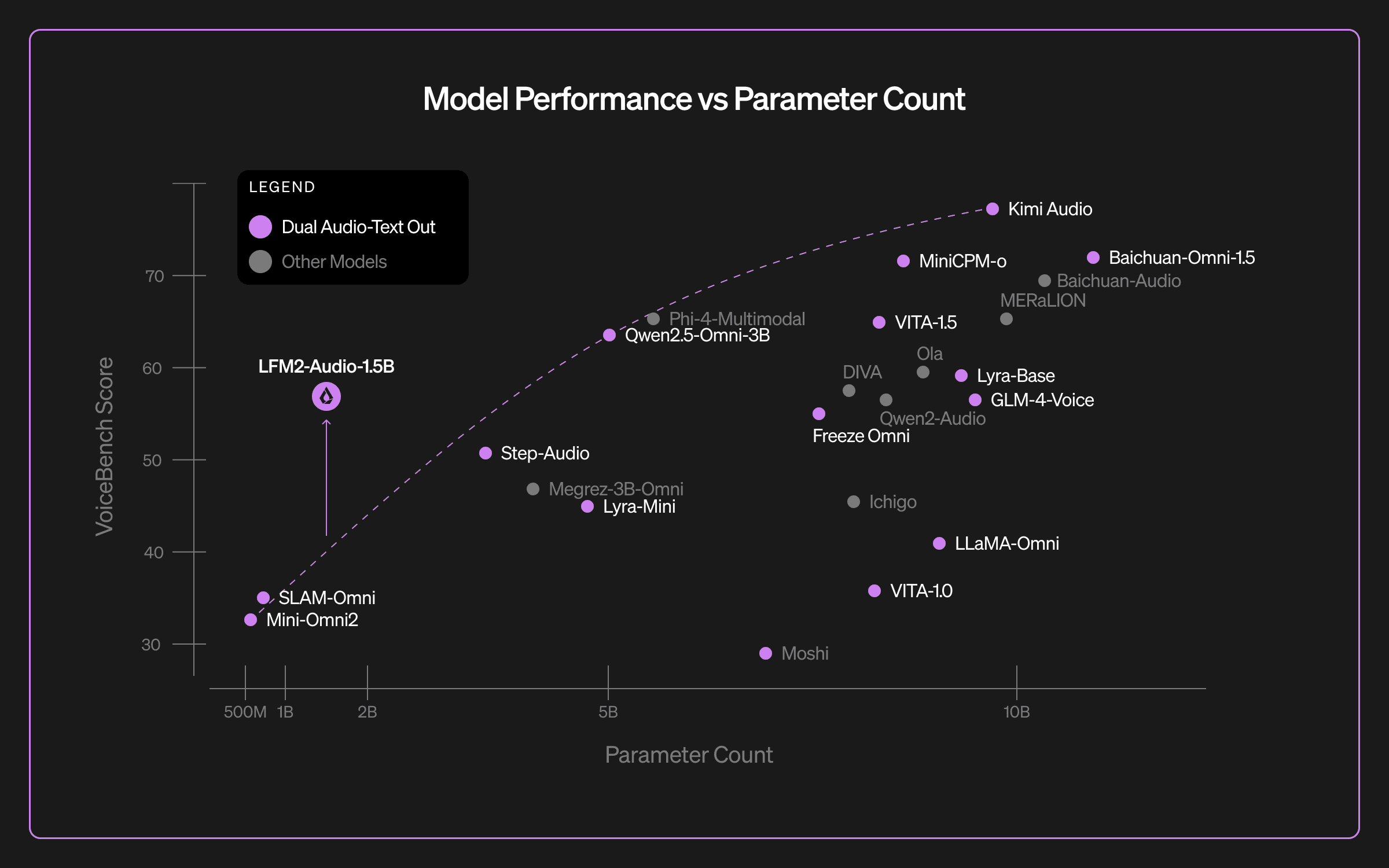
LFM2-Audio achieves strong results across audio and language tasks relative to much larger models. On VoiceBench, a suite of nine audio interaction benchmarks, it scores 56.8 overall with just 1.5B parameters. Despite not being an ASR specialized model, it matches or surpasses the quality of ASR-only models like Whisper-large-v3 — proving that edge-ready models can both be general-purpose without compromising on task-specific quality.
VoiceBench Evaluation
(Higher is Better)
LFM2-Audio-1.5B 1.5B parameters | Moshi 7B parameters | Qwen2.5-Omni-3B 5B parameters | Mini-Omni2 0.6B parameters | |
|---|---|---|---|---|
AlpacaEval | 3.71 | 2.01 | 3.72 | 2.32 |
CommonEval | 3.49 | 1.60 | 3.51 | 2.18 |
WildVoice | 3.17 | 1.30 | 3.42 | 1.79 |
SD-QA | 30.56 | 15.64 | 44.94 | 9.31 |
MMSU | 31.95 | 24.04 | 55.29 | 24.27 |
OBQA | 44.40 | 25.93 | 76.26 | 26.59 |
BBH | 30.54 | 47.40 | 61.30 | 46.40 |
IFEval | 98.85 | 10.12 | 32.90 | 11.56 |
AdvBench | 67.33 | 44.23 | 88.46 | 57.50 |
Overall | 56.78 | 29.51 | 63.57 | 33.49 |
ASR Benchmark Word Error Rates
(Lower is Better)
LFM2-Audio-1.5B 1.5B parameters | Qwen2.5-Omni-3B 5B parameters | Whisper-large-V3 1.5Bparameters | elevenlabs/scribe_v1 unknown | |
|---|---|---|---|---|
Audio output | Yes | Yes | No - ASR only | No - ASR only |
Open | Yes | Yes | Yes | No |
AMI | 15.58 | 15.95 | 16.73 | 14.43 |
GigaSpeech | 10.67 | 10.02 | 10.76 | 9.66 |
LibriSpeech Clean | 2.01 | 2.01 | 2.73 | 1.79 |
LibriSpeech Other | 4.39 | 3.91 | 5.54 | 3.31 |
TED-LIUM | 3.56 | 3.86 | 3.91 | 3.17 |
Average | 7.24 | 7.15 | 7.93 | 6.47 |
Efficiency
Efficiency is critical for audio models as they run in interactive real-time scenarios. We measure the latency between a speaker asking a question, and the model starting to reply – representing the perceived latency for interactive use. The model is provided with an input waveform (4 seconds), and the time to generate the first audible sound from the model is measured. LFM2-Audio-1.5B achieved an average end-to-end latency of under 100 ms, highlighting superb efficiency, even faster than models much smaller than 1.5B parameters.
Deploy and build with LFM2-Audio
Thanks to its speed, quality, and multimodal understanding, LFM2-Audio unifies what used to be an entire pipeline of models. This allows developers to build diverse applications from a single architecture, including:
- Conversational chat with real-time audio
- Voice-controlled interfaces (e.g., in-car systems)
- Live translation and transcription
- Meeting transcription
- Audio and intent classification
- RAG-powered voice assistant
- Emotion detection
To help you get started building with LFM2-Audio, we have published a Python package containing inference code as well as a reference implementation for how the model can be deployed in a speech-to-speech live chat application.
Get Started
LFM2-Audio defines a new class of audio foundation models: lightweight, multimodal, and real-time. By unifying audio understanding and generation in one compact system, it enables conversational AI on devices where speed, privacy, and efficiency matter most. With LFM2-Audio, we’re taking another step toward multimodal agents that run privately and in real time on your own devices.
Closing
LFM2-Audio defines a new class of audio foundation models: lightweight, multimodal, and real-time. By unifying audio understanding and generation in one compact system, it enables conversational AI on devices where speed, privacy, and efficiency matter most. With LFM2-Audio, we’re taking another step toward multimodal agents that run privately and in real time on your own devices.