.svg)
Today, we're excited to announce the LFM2.5-1.2B model family, our most capable release yet for edge AI deployment. It builds on the LFM2 device-optimized architecture and represents a significant leap forward in building reliable agents on the edge.
We've extended pretraining from 10T to 28T tokens and significantly scaled up our post-training pipeline with reinforcement learning, pushing the boundaries of what 1B models can achieve. This is a comprehensive release with Base, Instruct, Japanese, Vision-Language, and Audio-Language models.
LFM2.5 is optimized for instruction following capabilities to be the building block of on-device agentic AI. LFM2.5 enables access to private, fast, and always-on intelligence on any device. Our new Text models offer uncompromised quality for high-performance on-device workflows. The Audio model is 8x faster than its predecessor, running natively on constrained hardware like vehicles, mobiles, and IoT devices. Finally, our VLM boosts multi-image, multilingual vision understanding and instruction following for on-edge multimodal use.
All models are open-weight and available on Hugging Face and LEAP today. We are pleased to announce that our launch partners, AMD and Nexa AI, are delivering optimized performance on NPUs.
Language Models
The foundation of the LFM2.5 series is laid by our general-purpose language models. We are excited to release both the Base and Instruct variants to help builders better tailor solutions for their use cases.
LFM2.5-1.2B-Base is the pretrained checkpoint, used to create all the LFM2.5-1.2B variants. It is recommended for tasks that require heavy fine-tuning, like language- or domain-specific assistants, training on proprietary data, or experimenting with novel post-training approaches.
LFM2.5-1.2B-Instruct is the general-purpose instruction-tuned variant, suited for most use cases. Trained with supervised fine-tuning, preference alignment, and large-scale multi-stage reinforcement learning, it delivers excellent instruction following and tool use capabilities out of the box.
Text Model Benchmarks
LFM2.5 offers extremely fast inference speed on CPUs with a low memory profile compared to similar-sized models.
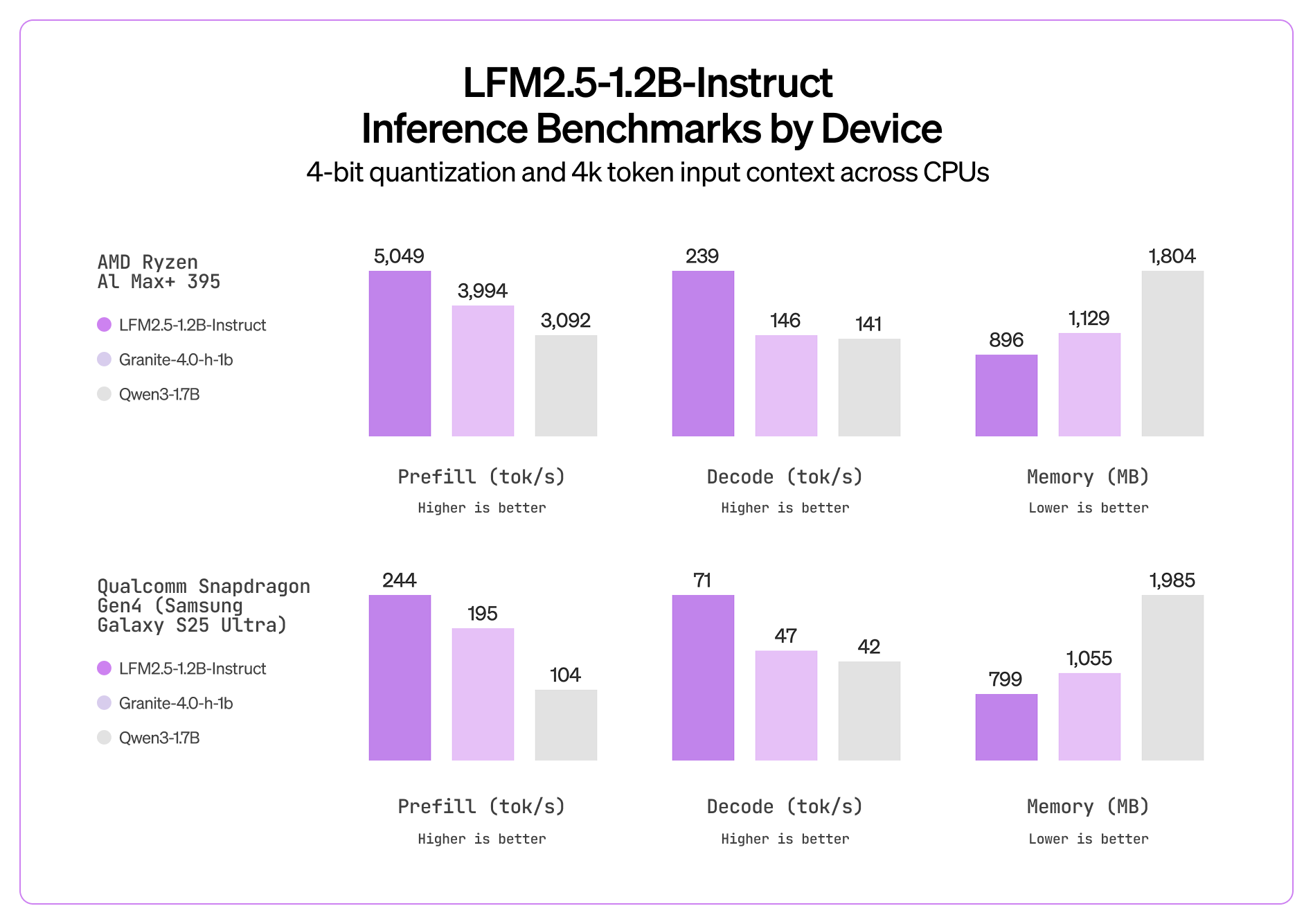
LFM2.5-1.2B-Instruct combines top performance and efficient inference at the 1B scale. It delivers best-in-class results across knowledge, instruction following, math, and tool use benchmarks while maintaining blazing inference speed thanks to our hybrid architecture. This makes it a natural fit for on-device use cases like local copilots, in-car assistants, and local productivity workflows.
Japanese Language Model
LFM2.5-1.2B-JP is a chat model specifically optimized for Japanese. While LFM2 already supported Japanese as one of eight languages, LFM2.5-JP pushes state-of-the-art on Japanese knowledge and instruction-following at its scale. This model is ideal for developers building Japanese-language applications where cultural and linguistic nuance matter.
Japanese Benchmark Results
Vision-Language Model
LFM2.5-VL-1.6B is our refreshed vision-language model, built on an updated LFM2.5-base backbone and tuned for stronger real-world performance. This release delivers clear gains in multi-image comprehension, and it also improves multilingual vision understanding, handling prompts in Arabic, Chinese, French, German, Japanese, Korean, and Spanish with greater accuracy. LFM2.5-VL-1.6B shows stronger instruction-following performance across both vision and text instruction benchmarks, making it an excellent choice for multimodal on-edge applications.
Vision and Text Benchmark Results
Audio-Language Model
LFM2.5-Audio-1.5B is a native audio-language model that accepts both speech and text as input and output modalities. Unlike pipelined approaches that chain transcription, LLM processing, and TTS as separate stages, LFM2.5-Audio processes audio natively, eliminating the information barriers between components and dramatically reducing end-to-end latency.
Key improvements include a custom, LFM-based audio detokenizer with significantly reduced latency, llama.cpp compatible GGUFs for CPU inference, and improved base language quality across ASR and TTS performance.
At the core of LFM2.5-Audio is a new compact audio detokenizer – an LFM-based architecture that efficiently converts discrete tokens from the language model backbone into high-fidelity audio waveforms. The LFM2.5 detokenizer is 8x faster than the LFM2’s Mimi detokenizer at the same precision on a mobile CPU. For maximum quality, it was also quantization-aware trained (QAT) with INT4 precision to enable seamless deployment directly at low precision, achieving very little quality loss compared to the original LFM2 Mimi detokenizer at FP32.
Below shows the performance of different audio models speaking the following text in both a male and female voice.
“The birch canoe slid on the smooth planks. Glue the sheet to the dark blue background. It's easy to tell the depth of a well.”
Run LFM2.5
Powerful models should be easy to deploy. That's why we're launching LFM2.5 with day-zero support across the most popular inference frameworks:
LEAP — Liquid's Edge AI Platform for deploying models to iOS and Android as easily as calling a cloud API.
llama.cpp — The go-to solution for CPU inference. GGUF checkpoints are available for all models, enabling efficient deployment on any hardware with optimized quantization.
MLX — Apple Silicon users can take full advantage of the unified memory architecture with our MLX-optimized checkpoints.
vLLM — For GPU-accelerated serving, vLLM support enables high-throughput inference for production deployments.
ONNX — Cross-platform inference with broad hardware support. ONNX checkpoints enable deployment across diverse accelerators and runtimes, from cloud to edge devices.
All frameworks support both CPU and GPU acceleration across Apple, AMD, Qualcomm, and Nvidia hardware.
Launch Partnerships
We are also partnering with AMD and Nexa AI to bring the LFM2.5 family to NPUs. These optimized models are available through our partners, enabling highly efficient on-device inference.
These capabilities unlock new deployment scenarios across various devices, including vehicles, mobile devices, laptops, IoT devices, and embedded systems.
Inference Speed Benchmarks
Get Started
The LFM2.5 family is available now on Hugging Face, LEAP, and our playground:
- LFM2.5-1.2B-Base: Hugging Face
- LFM2.5-1.2B-Instruct: Hugging Face, LEAP, Playground
- LFM2.5-1.2B-JP: Hugging Face, LEAP
- LFM2.5-VL-1.6B: Hugging Face, LEAP, Playground, Demo
- LFM2.5-Audio-1.5B: Hugging Face, LEAP, Playground
Our LFM2.5-1.2B variants are part of the LFM2.5 family of models, which we will grow across model sizes and reasoning capabilities.
With LFM2.5, we're delivering on our vision of AI that runs anywhere. These models are:
- Open-weight — Download, fine-tune, and deploy without restrictions
- Fast from day one — Native support for llama.cpp, NexaSDK, MLX, and vLLM across Apple, AMD, Qualcomm, and Nvidia hardware
- A complete family — From base models for customization to specialized audio and vision variants, one architecture covers diverse use cases
The edge AI future is here. We can't wait to see what you build.
For enterprise deployments and custom solutions, contact our sales team. Read our technical report for implementation details.