.svg)
Today, we release LFM2-ColBERT-350M, a late interaction retriever with excellent multilingual performance. It allows you to store documents in one language (for example, a product description in English) and retrieve them in many languages (e.g., a query in Spanish, German, French, etc.) with high accuracy. Thanks to the efficient LFM2 backbone, it also benefits from extremely fast inference speed, on par with models that are 2.3 times smaller.
Highlights
- LFM2-ColBERT-350M offers best-in-class accuracy across different languages.
- Inference speed is on par with models 2.3 times smaller, thanks to the efficient LFM2 backbone.
- You can use it today as a drop-in replacement in your current RAG pipelines to improve performance.
Why Late Interaction?
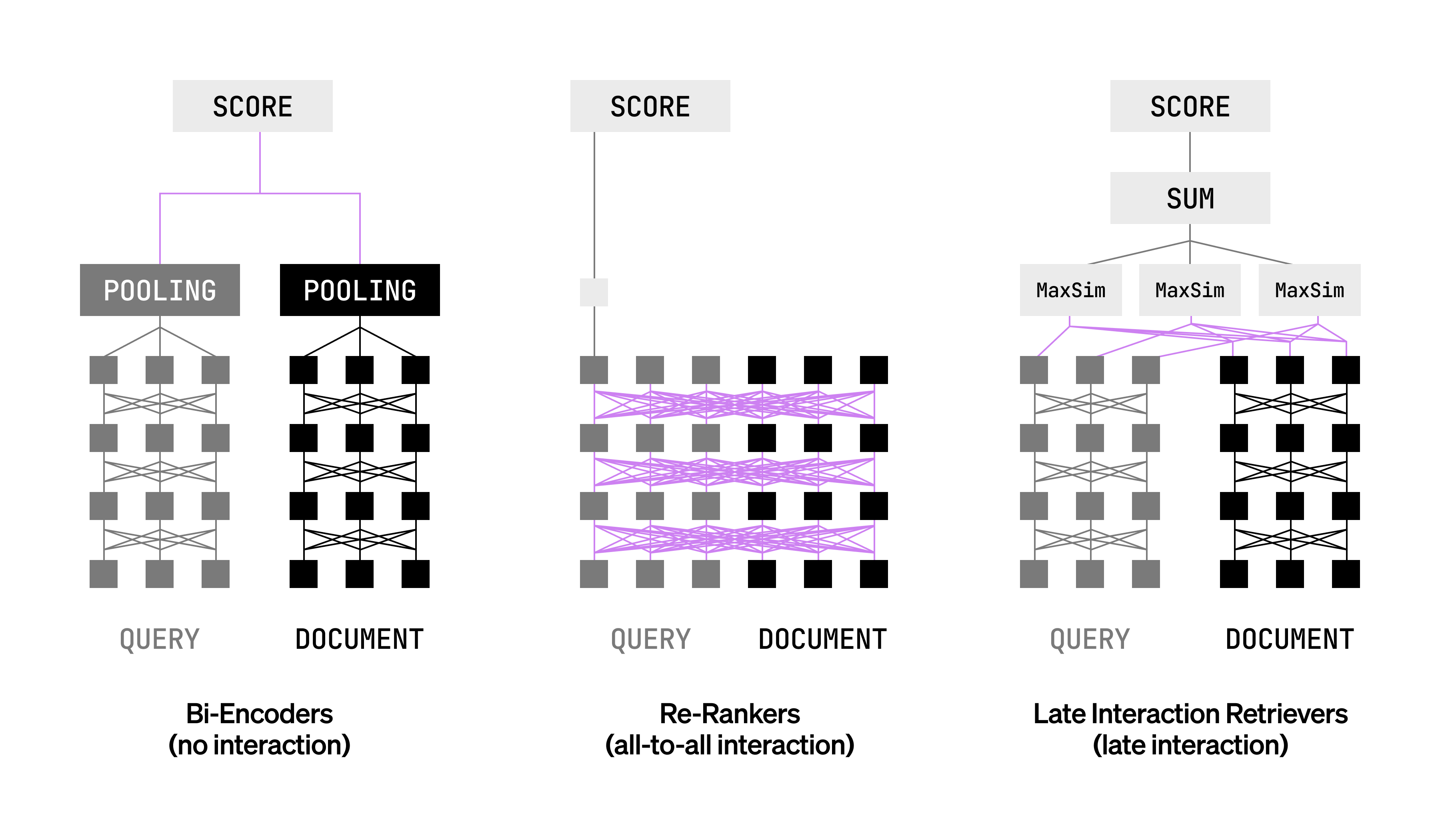
Embedding models can be divided into three families:
- Bi-encoders like BERT encode queries and documents independently, then compute a similarity score. These are fast and scalable but lose fine-grained token-level interactions, which often hide critical signals like subtle term matching.
- Rerankers (or cross-encoders) encode queries and documents jointly, enabling full attention-based interaction between query and document tokens. Accuracy is high, but computational cost is prohibitive at scale.
- Late interaction retrievers encode queries and documents independently at a token level for higher accuracy. At query time, it compares the tokens from the query and document embedding (e.g., via MaxSim) and aggregates the scores.
Late interaction retrievers are particularly interesting because they preserve much of the expressivity of cross-attention while retaining the efficiency of pre-computation. In practice, they're used to both retrieve documents at scale (like bi-encoders) and rank them at the same time (like rerankers).
Evaluations
We compared LFM2-ColBERT-350M against the current best late interaction retriever in the sub-500M parameter category: GTE-ModernColBERT-v1 (150M parameters).
We extended the NanoBEIR benchmark to include Japanese and Korean languages. We open-sourced this dataset on Hugging Face at LiquidAI/nanobeir-multilingual-extended for reproducibility. On this NanoBEIR benchmark, LFM2-ColBERT-350M displays significantly stronger multilingual capabilities (especially in German, Arabic, Korean, and Japanese) while maintaining English performance.
.png)
Even more interestingly, LFM2-ColBERT-350M is an excellent cross-lingual retriever. This means that it is capable of retrieving documents based on queries from other languages. This is ideal for client-facing applications, like in e-commerce, where a description might be in English but the query is in another language.
This works especially well for English, French, Spanish, Italian, Portuguese, and German, as shown with these NDCG@10 scores on NanoBEIR:
In comparison, GTE-ModernColBERT-v1 consistently gets lower scores when documents and queries are not in the same language.
This makes retrieval a lot more reliable and can replace architectures with multiple models with a single, unified retriever.
Inference speed
Despite being more than twice as big, LFM2-ColBERT-350M demonstrates throughput performance on par with GTE-ModernColBERT-v1 for query and document encoding across various batch sizes.
We profiled inference speed as follows:
- Query encoding was evaluated using realistic query patterns from datasets like MS MARCO and Natural Questions.
- Document encoding was measured on realistic documents with varying lengths and domains.
.png)
.png)
This fast inference is possible thanks to the efficient LFM2 backbone that combines short‑range, input‑aware gated convolutions with grouped‑query attention.
Build with LFM2
LFM2-ColBERT-350M is available today on Hugging Face, complete with an interactive demo. If you are interested in custom solutions with edge deployment, please contact our sales team.