.svg)
Today, we're releasing LFM2.5-350M, an improved version of our 350M model with additional pre-training (from 10T to 28T tokens) and large-scale reinforcement learning. Built on the LFM2 architecture, it delivers exceptionally fast inference and runs everywhere, from cloud GPUs to cheap CPUs. It excels at tool use, data extraction, and structured outputs - all at 350M parameters - making it purpose-built for large-scale data processing and function calling at the edge.
To meet developers where they are, we ensure our models run seamlessly on preferred inference engines and hardware across CPUs, NPUs, and GPUs. We are thrilled to welcome Zetic, RunAnywhere, and Mirai to our local AI ecosystem, joining AMD, Qualcomm Technologies, Intel, LM Studio, and Cactus Compute to drive robust edge deployments across vehicles, smartphones, laptops, IoT, and embedded systems. Additionally, our new collaboration with Distil Labs empowers teams to effortlessly fine-tune highly efficient LFMs models to replace expensive and slow LLMs using just model traces.
The base (LFM2.5-350M-Base) and post-trained (LFM2.5-350M) models are available today on Hugging Face, LEAP, and our Playground. Check out our docs on how to run and fine-tune them locally.
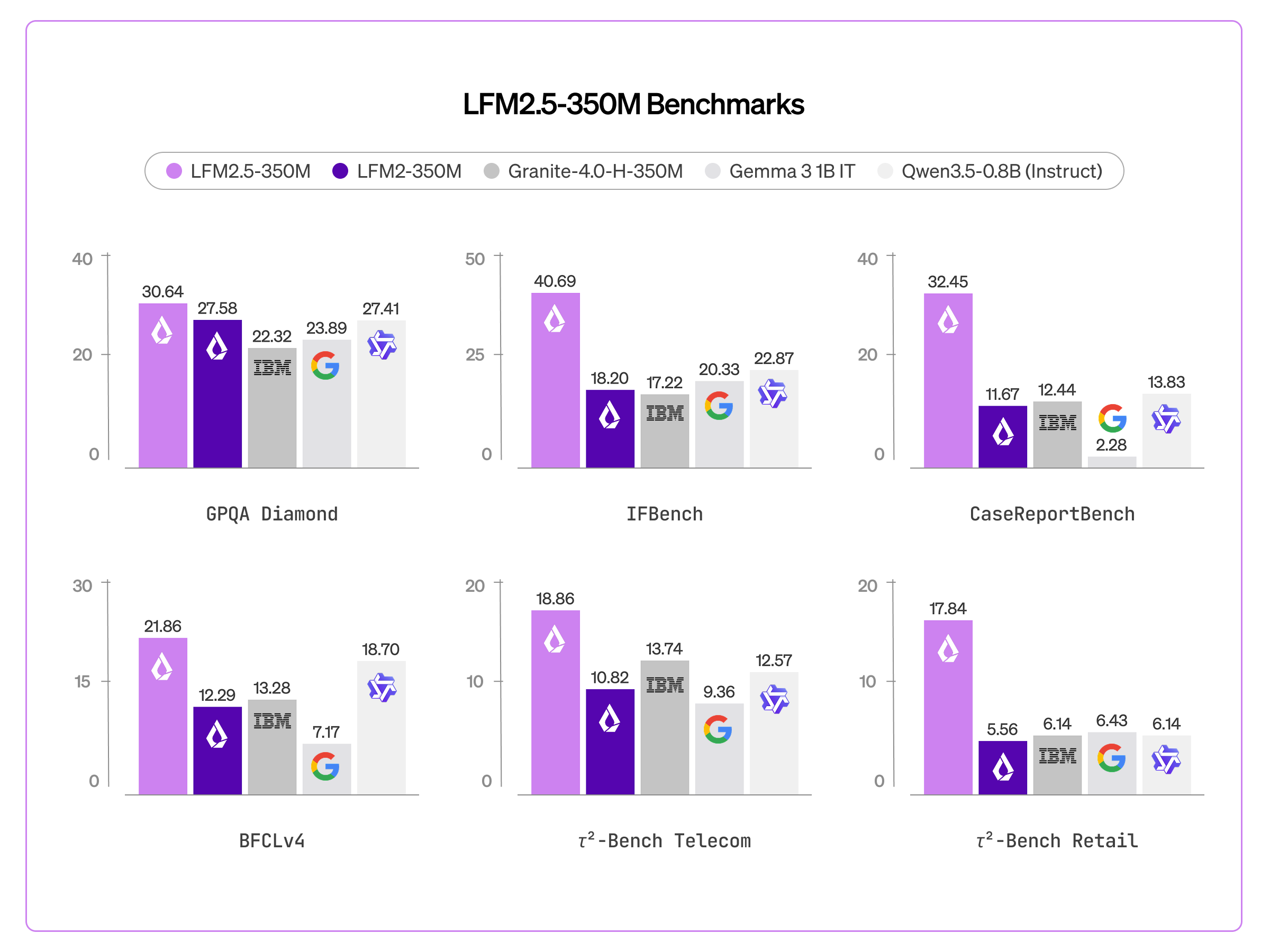
Benchmarks
We evaluated LFM2.5-350M across ten benchmarks spanning core capabilities and applied tasks. It outperforms models more than twice its size on core capabilities like knowledge (GPQA Diamond, MMLU-Pro) and instruction following (IFEval, IFBench, Multi-IF), but also specific tasks like data extraction (CaseReportBench) and tool use (BFCLv3, BFCLv4, 𝜏²-Bench Telecom and Retail).
Compared to LFM2-350M, three capabilities see a significant improvement: instruction following (IFBench 18.20 → 40.69), data extraction (CaseReportBench 11.67 → 32.45), and tool use (BFCLv3 22.95 → 44.11).
This makes LFM2.5-350M an ideal solution to power large-scale data extraction pipelines or lightweight on-device agentic pipelines. However, it is not recommended for tasks like math, code, and creative writing.
Fast Inference Everywhere
LFM2.5-350M ships with day-one support across the inference ecosystem:
- LEAP — Liquid's Edge AI Platform for iOS and Android deployment
- llama.cpp — GGUF checkpoints for efficient edge inference
- MLX — Optimized inference for Apple Silicon
- vLLM — GPU-accelerated serving for production throughput
- SGLang — GPU-accelerated serving for production throughput
- ONNX — Cross-platform inference across diverse accelerators
- OpenVino — Optimization and deployment toolkit for Intel hardware
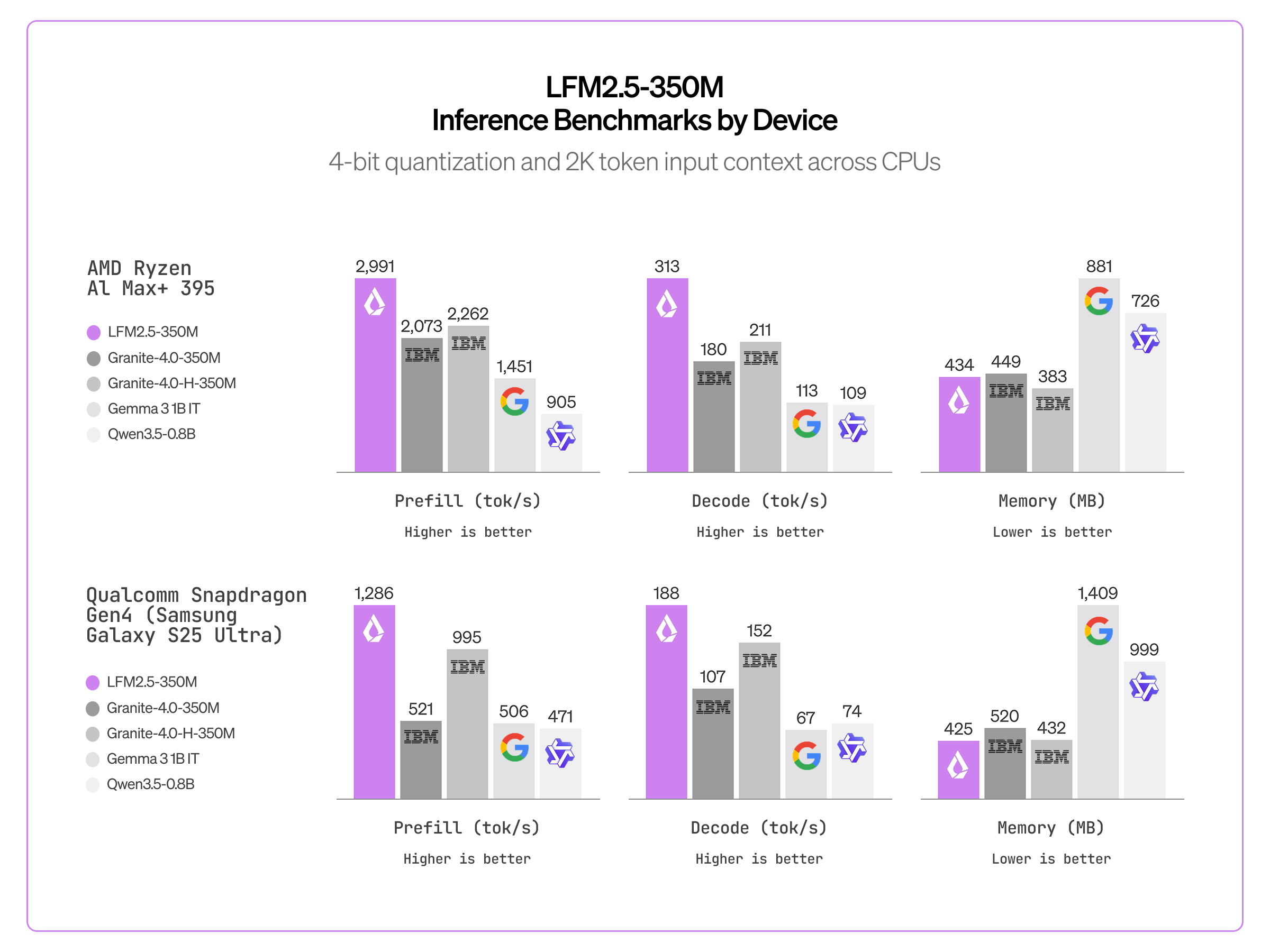
CPU inference. Thanks to the efficient LFM2 architecture, LFM2.5-350M is significantly faster than similar-sized models, including SSM hybrids (Granite-4.0-H-1B) and Gated Delta Networks (Qwen3.5-0.8B).
GPU inference. To enable big data processing, we support high-throughput inference engines such as vLLM and SGLang. We measure output throughput (total output tokens / wall time) on a single NVIDIA H100 SXM5 GPU using a sustained load setting: at each concurrency level, we continuously maintain the target number of in-flight requests (as soon as one request completes, another is sent to replace it).

Each model is benchmarked with SGLang 0.5.9 across concurrency levels from 1 to 4,096, using 1,024 input tokens and up to 256 output tokens (max_tokens=256) in BF16 precision. We repeat each experiment 3 times and report the average throughput. LFM2.5-350M achieves the highest peak throughput among models in this size category, reaching 40.4K output tokens per second at high concurrency — equivalent to over 3.5B tokens per day on a single H100.
Liquid’s Partner Ecosystem Expands
.png)
To ensure the LFM2.5 family runs efficiently and effectively wherever you need it, we are rapidly expanding our hardware and software ecosystem. Today, we are thrilled to welcome a diverse group of partners, from silicon leaders and optimization runtimes, like Mirai, Zetic, and Runanywhere, to customization partners like Distil Labs. Whether you are fine-tuning for specific workflows or deploying on mobile NPUs and edge devices, our ecosystem empowers developers to choose their preferred environments and hit the ground running.
Customizing for Production: Distil Labs
To push the limits of our new 350M model, we partnered with Distil Labs to benchmark LFM2.5 on real-world agentic workflows. By fine-tuning the model for multi-turn interactions across smart home, banking, and terminal-based use cases, they achieved a massive jump in tool-calling reliability, hitting over 95% accuracy throughout the dialog. This result proves that LFM2.5 isn't just fast; it’s highly capable of handling the sophisticated back-and-forth required for production-grade AI agents
Silicon and Software Optimization Partners
To bring LFM2.5 to the edge, we have collaborated with leading silicon and software partners to optimize the models across CPUs, GPUs, and NPUs.
AMD: Our partnership with AMD ensures LFM2.5-350M is fully optimized for their Ryzen™ AI hardware. By leveraging the Ryzen™ AI inference engine, we deliver a high-efficiency local experience across CPUs, GPUs, and NPUs.
“AMD is proud to provide day zero support for LFM2.5-350M. Our Ryzen™ AI processors provide an ideal platform for local deployment of this compact yet powerful model.” - Ramine Roane, Corporate Vice President of AI Product Management at AMD.
Qualcomm Technologies: To fully harness the power of Qualcomm SoCs, we have partnered with Qualcomm Technologies, Zetic and Runanywhere. Zetic’s Melange execution layer delivers Day 0 support for the LFM2.5 350M on Qualcomm Snapdragon® devices. This allows developers to instantly leverage Qualcomm CPUs, GPUs and NPUs for rapid on-device inference without needing custom optimization. Alongside Zetic, RunAnywhere further expands our Snapdragon footprint, providing developers with seamless, optimized execution tailored specifically for the Hexagon architecture.
“What LiquidAI has achieved with their LFM2.5-350M model is a strong validation of the on-device AI approach, that we have been building at Qualcomm Technologies,” stated Vinesh Sukumar, VP, Product Management and Head of Gen AI/ML, Qualcomm Technologies, Inc. “Their architecture is uniquely suited for the constraints of mobile and edge deployment, and when you run it on the Qualcomm® Hexagon™ NPU, you see that in numbers--low latency, low memory footprint and inference quality that competes with models several times its sizes. This announcement is a clear signal that efficient AI and capable AI are no longer a tradeoff”.
Intel brings accelerated performance to the LFM2.5 350M with native OpenVINO optimization. Designed to maximize inference speeds on Intel hardware, these ready-to-run models are available right now on Hugging Face.
“We are excited to bring the power of Liquid AI’s LFM 2.5 350M to the Intel ecosystem. By integrating native OpenVINO optimizations, we’re enabling developers to achieve exceptional inference speeds and efficient memory management across Intel-powered edge and AI PC environments.” - Sudhir Tonse Udupa, Vice President, AI PC Software Engineering, Intel
Apple Silicon Ecosystem: Powered by the Mirai engine, LiquidAI's LFM2.5-350M delivers blazing-fast, on-device inference across the entire Apple Silicon ecosystem. Benchmarks showcase exceptional generation speeds on hardware ranging from the mobile A18 Pro chip to desktop-class M1 through M5 Max processors.
Low-Memory Edge Devices: Proving that high performance doesn't require high-end hardware, Cactus Compute showcased the LFM2.5 350M running exceptionally fast on sub-$300 devices like the iPhone 13 Mini, Google Pixel 6a, and Raspberry Pi 5. The Cactus Engine makes this possible by heavily optimizing RAM usage for constrained edge environments.
Universal Local Deployment: Finally, LM Studio delivers Day 0 support for the LFM2.5 350M. Developers can run this model seamlessly on their local edge devices using llmster, LM Studio's headless daemon, making local experimentation and deployment effortless.
Inference Speed Benchmarks for LFM2.5-350M
Get Started
Start building today with LFM2.5-350M and LFM2.5-350M-Base, available on
.svg)

With LFM2.5, we're delivering on our vision of AI that runs anywhere. These models are:
- Open-weight — Download, fine-tune, and deploy without restrictions
- Fast from day one — Native support for llama.cpp, NexaSDK, MLX, and vLLM across Apple, AMD, Qualcomm, and Nvidia hardware
- A complete family — From base models for customization to specialized audio and vision variants, one architecture covers diverse use cases
The edge AI future is here. We can't wait to see what you build.
Citation
Please cite this article as:
Liquid AI, "LFM2.5-350M: No Size Left Behind", Liquid AI Blog, Mar 2026.Or use the BibTeX citation:
@article{liquidAI2026350M,
author = {Liquid AI},
title = {LFM2.5-350M: No Size Left Behind},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/lfm2-5-350m-no-size-left-behind},
}